







Wikidata
Wikidata 是一个自由、协作的知识库,它包含了从各种来源收集的信息,这些信息以 RDF(Resource Description Framework)三元组的形式存储。每个三元组包含主体(Subject)、谓语(Predicate)和宾语(Object),这种结构使得数据可以灵活地表示复杂的关系。
SPARQL
SPARQL是一种用于查询RDF(Resource Description Framework,资源描述框架)数据的语言。
Wikidata+SPARQL
使用SPARQL查询获取Wikidata中的结构化数据。
官方文档教程:Wikidata:SPARQL教程 - Wikidata
SPARQL简单实战
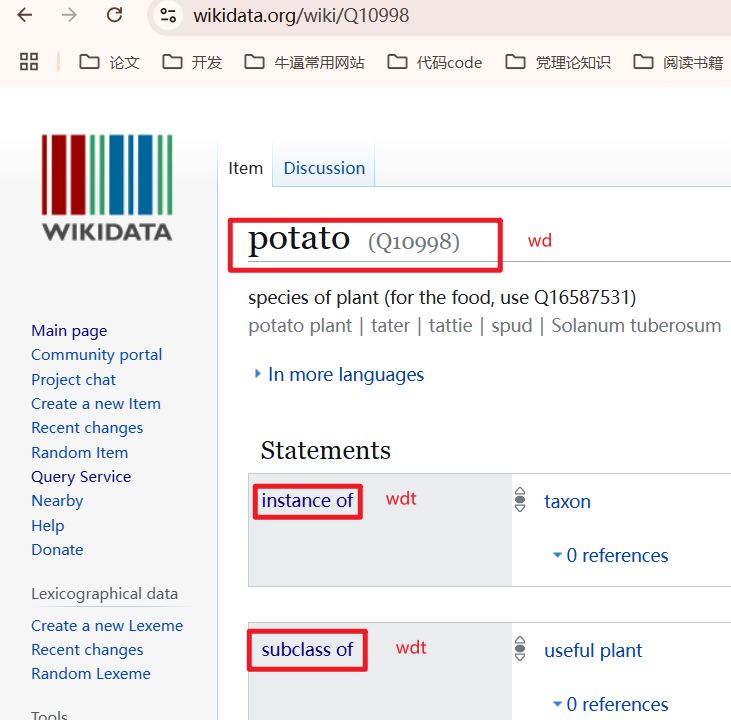
常用缩写解释:
wd:实体
- wd:Q10998
,potato
wdt:关系
- wdt:P31,instance of
- wdt:P279,subclass of
- wdt:p366,has use
- wdt:p18,image
- wdt:p105,taxon rank
- wdt:p171,parent taxon
demo演示:
演示网页:https://query.wikidata.org/
SELECT ?cropName ?cropNameLabel
WHERE {
?cropName wdt:P31 wd:Q235352.
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}
LIMIT 100cropName是一个变量,即所查找的具体作物。
WHERE含义:wdt:p31是instance of,wd:Q235352是crop,即查找crop的所有实例前100个。
SERVICE wikibase:label:返回显示变量的名称,没有这行代码就不显示查找的变量的名称。
wdt:P31/wdt:P279*
SELECT ?dish ?dishLabel
WHERE {
?dish wdt:P31/wdt:P279* wd:Q746549.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}
LIMIT 100含义:表示查询符合先是 P31 类型(实例)后再是 P279* 子类递归关系的实体。即,它会先确定实体属于某个类,然后再查找该类的子类。是按层次结构进行的逐步筛选。
举个例子:如果查询一个“菜肴”类的实例,它会先找到菜肴类的所有实例,然后再找该类的子类(如果有的话),并包括这些子类下的实例。
查找顺序:严格按照顺序,先查实例类型,再查其子类。
(wdt:P31|wdt:P279*)
SELECT ?dish ?dishLabel
WHERE {
?dish (wdt:P31|wdt:P279*) wd:Q746549.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}
LIMIT 100# (P31 是instance of,P279 是subclass of,Q746549是dish)
含义:查询既是 dish 的实例,也可以是 dish 的子类,* 表示可以递归查询子类。表示查询实例是某个类的实例 或者 该实体是某个类的子类。换句话说,它会同时查找属于菜肴类的实例和所有作为菜肴类子类的实体(这两者是并列的,不要求顺序)。
举个例子:查询的是菜肴类的实例或它的子类的实例,结果会同时包括菜肴类的所有实例和所有子类实例。
查找顺序:表示或操作,会查找既是实例又是子类的所有实体。

两者区别
为了更好地帮助你理解这两种表达式的查询顺序和结果,我们可以通过图示来阐明。以下是对两种查询表达式(wdt:P31/wdt:P279* 和 (wdt:P31|wdt:P279*))的查找顺序以及它们的查询结果的可视化解释。
1. wdt:P31/wdt:P279* 查询
这种查询的含义是:
wdt:P31:查询实体是某个类的实例。wdt:P279*:然后查询这个类及其所有子类,并递归查找子类。
查询顺序:
- 先查找某个实体是否是
dish类的实例(即是否属于Q2090类)。 - 然后,递归查找该实例所属的类是否是
dish类的子类(例如:炖菜stew是菜肴dish类的子类)。
查询示意图:
Q2090 (dish) <- 菜肴类
|
+-- Q36048 (stew) <- 子类1(炖菜类)
| |
| +-- Q36049 (beef stew) <- 炖牛肉,实例1
| +-- Q36050 (chicken stew) <- 炖鸡肉,实例2
|
+-- Q36051 (soup) <- 子类2(汤类)
|
+-- Q36052 (tomato soup) <- 番茄汤,实例3
解释:
- 通过
wdt:P31/wdt:P279*,你会首先找到属于dish类(菜肴类)的所有实例,然后会递归查找该类的所有子类的实例。所以,结果将包括菜肴类本身的实例(如炖牛肉、番茄汤等),以及所有属于菜肴子类的实例。
2. (wdt:P31|wdt:P279*) 查询
这种查询的含义是:
wdt:P31:查询实体是某个类的实例。wdt:P279*:查询实体是否是某个类的子类,包括所有递归的子类。
查询顺序:
- 查找所有属于
dish类的实例。 - 查找所有是
dish类及其子类的实例,不要求严格顺序。
查询示意图:
Q2090 (dish) <- 菜肴类
|
+-- Q36048 (stew) <- 子类1(炖菜类)
| |
| +-- Q36049 (beef stew) <- 炖牛肉,实例1
| +-- Q36050 (chicken stew) <- 炖鸡肉,实例2
|
+-- Q36051 (soup) <- 子类2(汤类)
|
+-- Q36052 (tomato soup) <- 番茄汤,实例3
解释:
- 使用
(wdt:P31|wdt:P279*),你查询的是“菜肴类(dish)”的所有实例和它的子类的实例。这个查询会同时返回菜肴类的实例(例如:炖牛肉、番茄汤)以及菜肴类的所有子类实例,不关心它们是在哪个层级。 - 结果会包括菜肴类的所有实例,如
beef stew(炖牛肉)、tomato soup(番茄汤)等,同时也会包含炖菜类(stew)和汤类(soup)作为菜肴类的子类。
关键区别:
-
wdt:P31/wdt:P279*是一个顺序查询。首先检查实例,再递归检查该实例所属的类的子类。换句话说,它首先查找属于“菜肴”类的实例,然后逐级查找属于菜肴类子类的实例。 -
(wdt:P31|wdt:P279*)是一个并列查询。查询同时返回两个条件的结果:既是“菜肴类”的实例,也包括所有属于“菜肴类”的子类的实例。它并不区分顺序,而是查找两个条件下的所有符合项。
总结:
wdt:P31/wdt:P279*:先查实例,再递归查其子类。(wdt:P31|wdt:P279*):并列查找实例和子类。
相同点:
这两种查询都涵盖了“实例”以及“子类”的所有实体。

















 2589
2589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









