







尝试对DeblurGANv2网络进行改进:
backbone是图像的特征提取的部分,网络特征提取的效果直接影响着后续的去模糊效果,这里尝试了不同特征提取模块(backbone)对网络去模糊效果的影响,分别把backbone更换为mobilenet,shufflenet,efficient等轻量级网络骨干,看看是否能够对去模糊的速度有一定的提升!
下面是更换的过程:
1.首先要了解源网络的框架,需要在读懂源码的基础上,对源码进行修改,DeblurGANv2的框架如下图所示
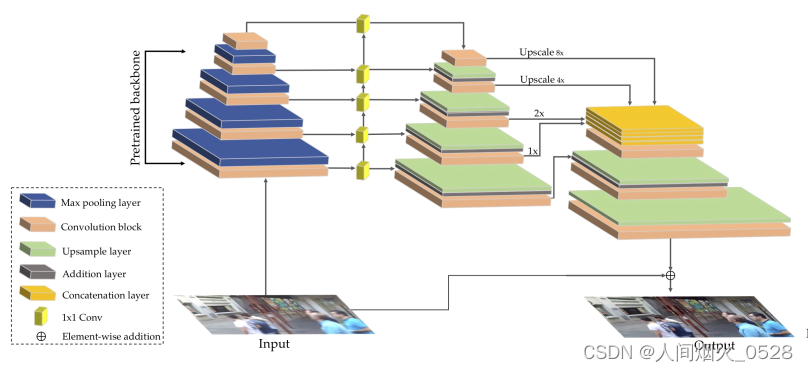
1.如上图所示,最左边的那一叠就是backbone,即提取图像特征的部分
2.中间的小块,经过1x1的卷积进行通道对齐,因为后续要对不同层次的特征图进行融合,需要具有相同的特征图的通道数和大小,这一步采用相同个数的卷积核就是为了对齐通道(通道数和卷积核的个数一致),后面进行下采样或者上采样等等是为了使特征图具有相同的大小(w和h)
3.把源代码下载下来后,可以观察源代码中涉及这部分的代码,models中的fpn_inception和fpn_mobilenet这两个文件,其中文件名fpn就是使用了特征金字塔进行了尺度融合,后面的inception和mobilenet是对图像特征的提取,看看这两个文件中的内容,会发现定义FPN的部分都是一样的即class FPNhead部分,如下:
fpn_mobilenet部分
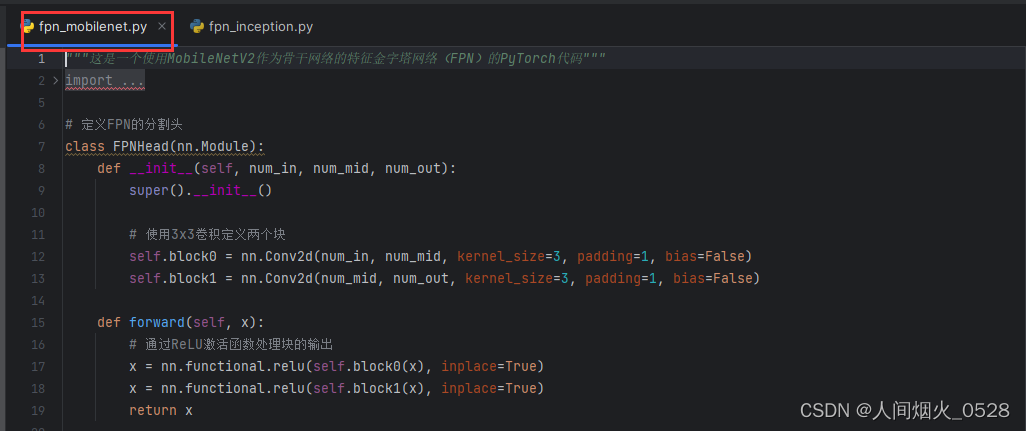
fpn_inception部分
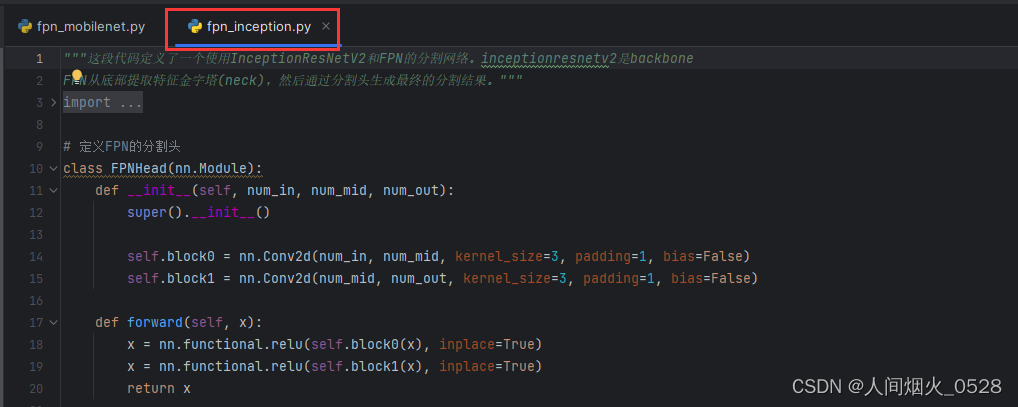
再次对比两个文件
(主要目标其实就是看看,更换backbone之后,哪个地方时不一样的,如果我们再次对backbone进行更改,可以对着进行修改)
fpn_mobilenet部分
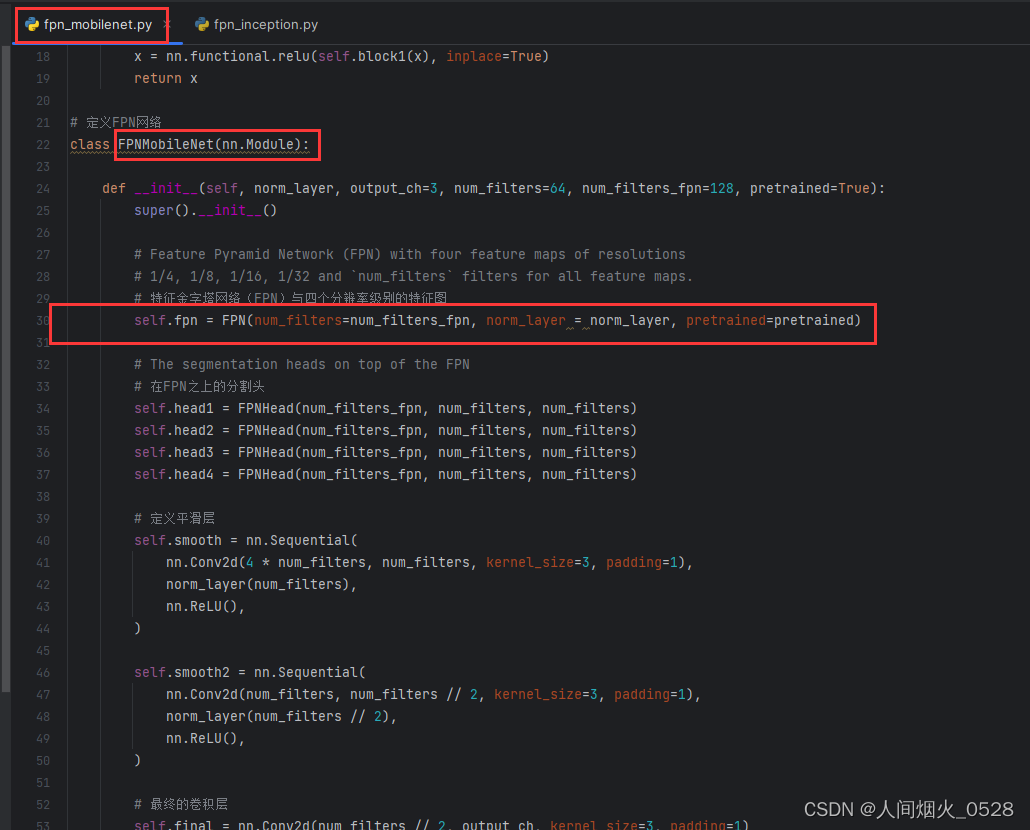
fpn_inception部分
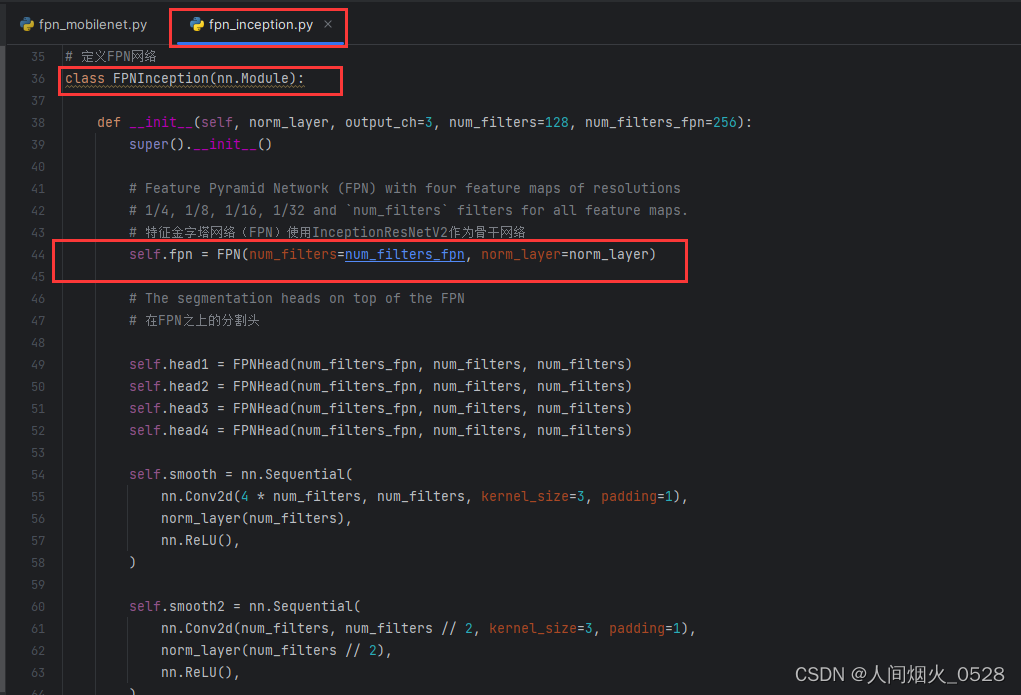
从上面的两个文件,可以观察出来哪个地方是不同的,名字其实就是表示一个使用mobilenet实现的FPN,一个是使用Inception实现的FPN,这个FPN函数可以在下面的4找到
4.FPN部分的修改
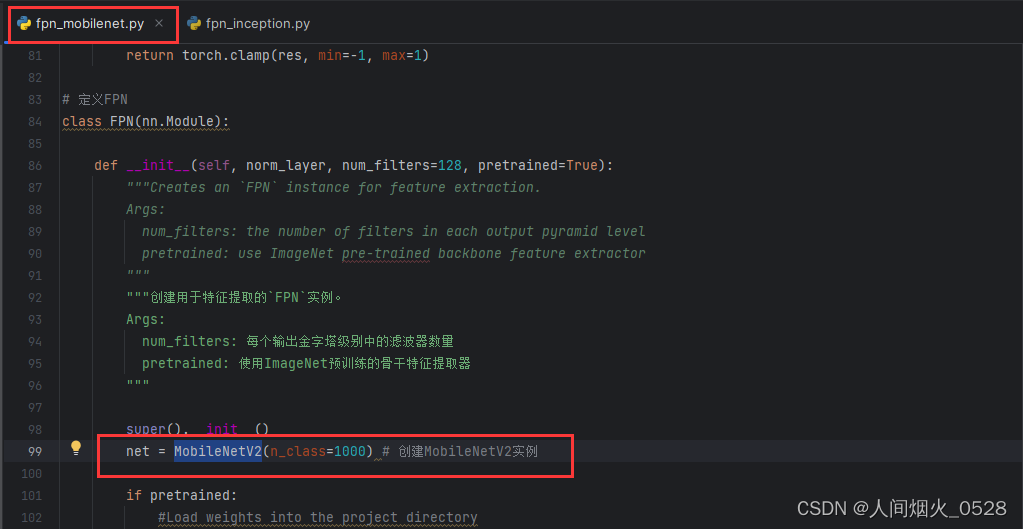
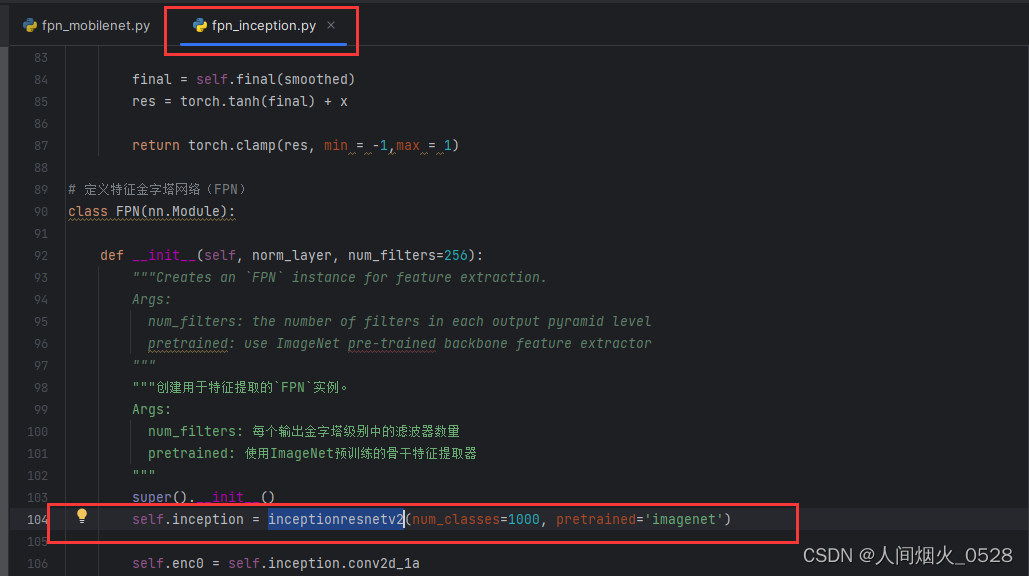
两个骨干网络中,都有FPN的类,考虑一下是干什么的,这里不同之处如下,一个提到的是inceptionresnetv2,另一个提到的是MobileNetV2,这里其实就是使用不同的backbone进行特征提取!
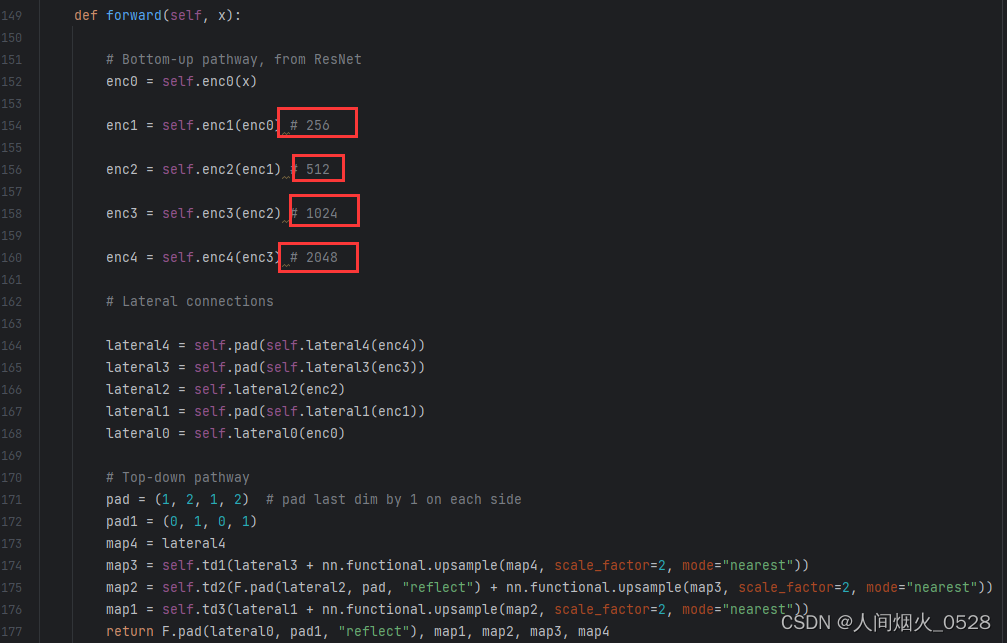
然后看下面整个网络的前向传播过程,其中的对应关系如下图所示:
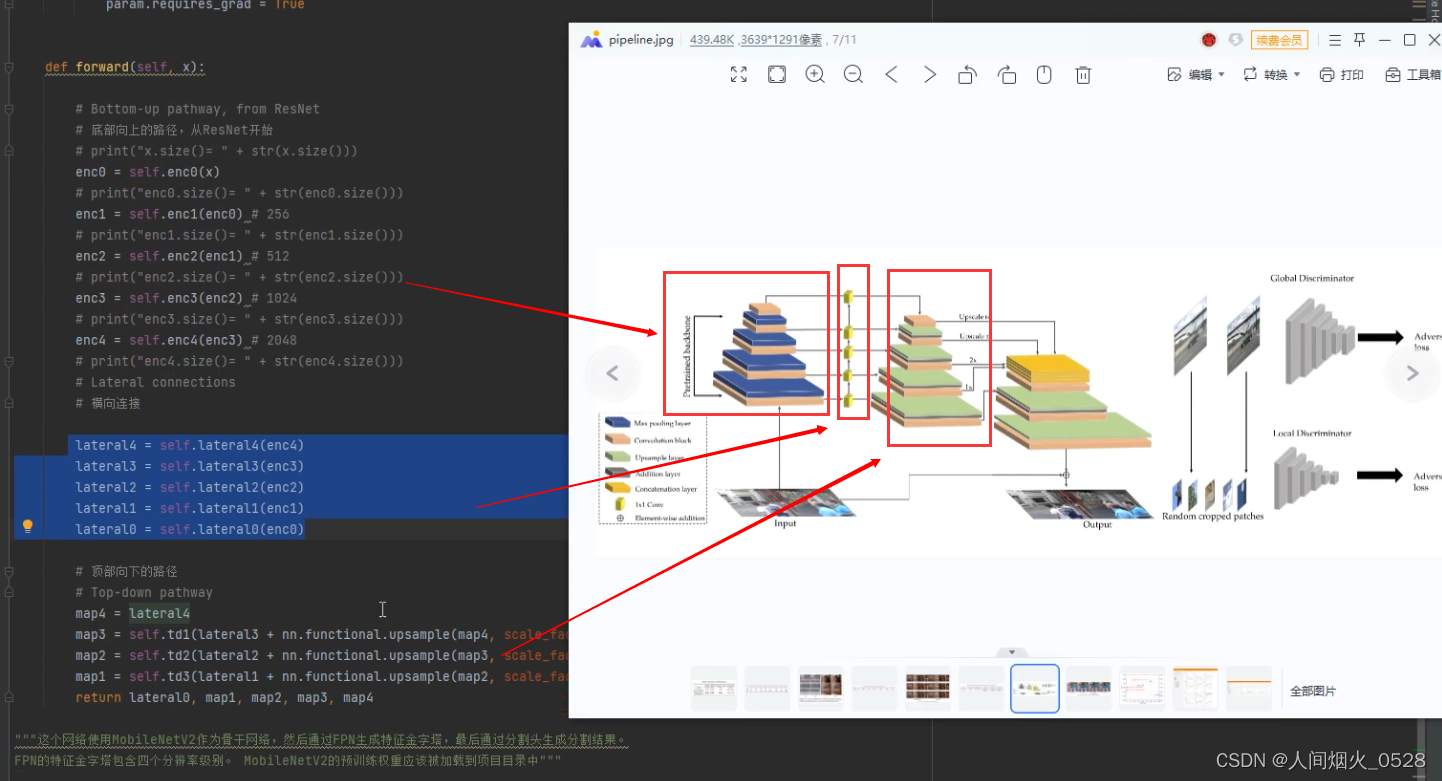
enc0是原图,enc1是第2层,,,,这个一个对应关系,总共有5层,对应从上向下的第1个箭头部分
lateral1,lateral2,,,,是横向连接部分,就是使通道数一样,对应从上向下的第2个箭头部分
map1,map2,,,自顶部向下,是拼特征图的部分,即融合不同尺度的特征,对应从上向下的第3个箭头部分
**注意:**在第一个箭头的部分,写的256,512,,,,等等代表的是图像的分辨率,那么从这个网络中可以看到,每个层的大小都是上一层的一半,最后经过上采样再汇合一起,那么在特征提取网络中,我们就需要找到哪一层是前一层大小一半的输出部分,这部分才是对我们来说是有用的,我们要使用backbone的这部分提取的特征。(重点:换backbone就是找到哪些层是在上一部分缩小了一半)
到这里,我们应该怎么改呢,就是改FPN这个函数部分,那么可以在原来的基础上进行更改,以fpn_efficientnet为例,创建fpn_efficientnet.py文件,把fpn_mobilenet.py文件中的内容复制进去,另外文件中是把mobilenet的网络实例化了,所以文件里有mobilenet的实现过程,同样,我们要改为efficient网络,这个文件夹里也应该放efficient的实现过程,具体操作步骤如下:
4.1下面这部分改为FPNefficient(因为骨干换成efficient了)
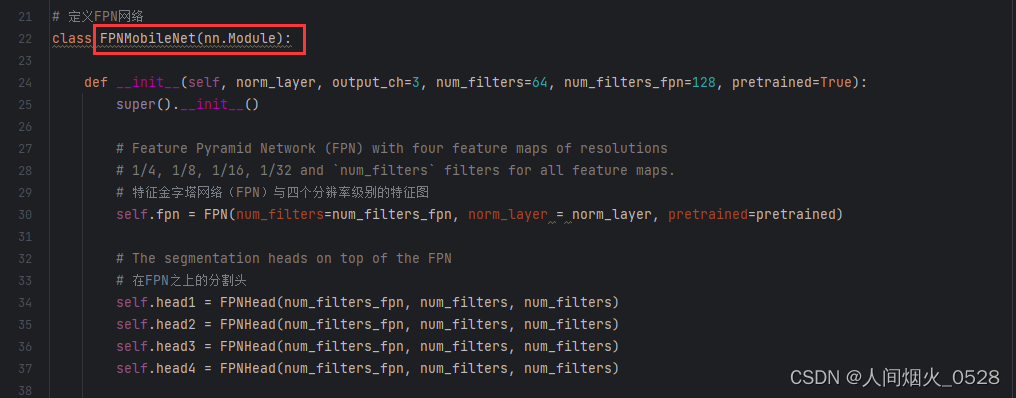
在FPN这个类里面,实例化部分改为Efficientnet,如下图:
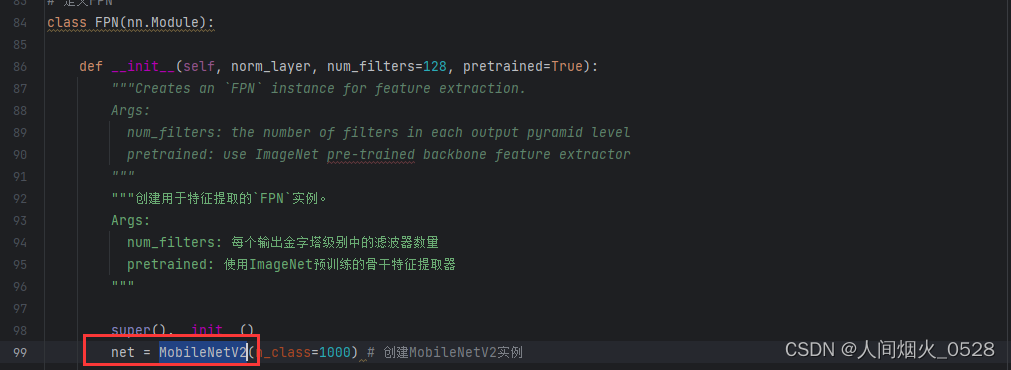
插入efficient的具体实现过程,直接去百度搜“efficientnet pytorch实现”,搜出来的结果都是一样的,任意找到一个代码就可以复制过来,在models里面创建efficientnet.py,然后把复制出来的代码复制粘贴进去,这个文件就是具体的视线过程。
4.2efficientnet的框架和mobilenet的框架肯定是不一样的,需要找到efficientnet中,哪些层输出特征的分辨率是上一层的一半,那怎么找呢,把efficient的网络结构打印出来,在实例化backbone之后,打印print(net)如下:
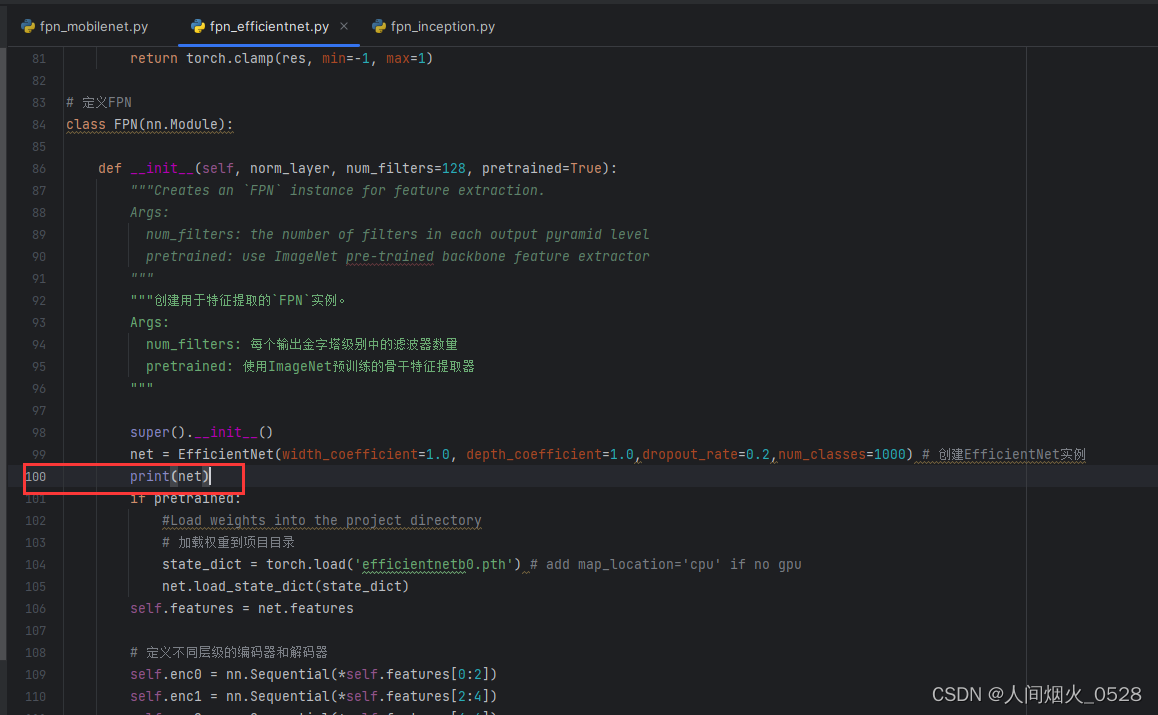
怎么知道缩小为原来的一半了呢,每一个都需要算,使用如下的公式:

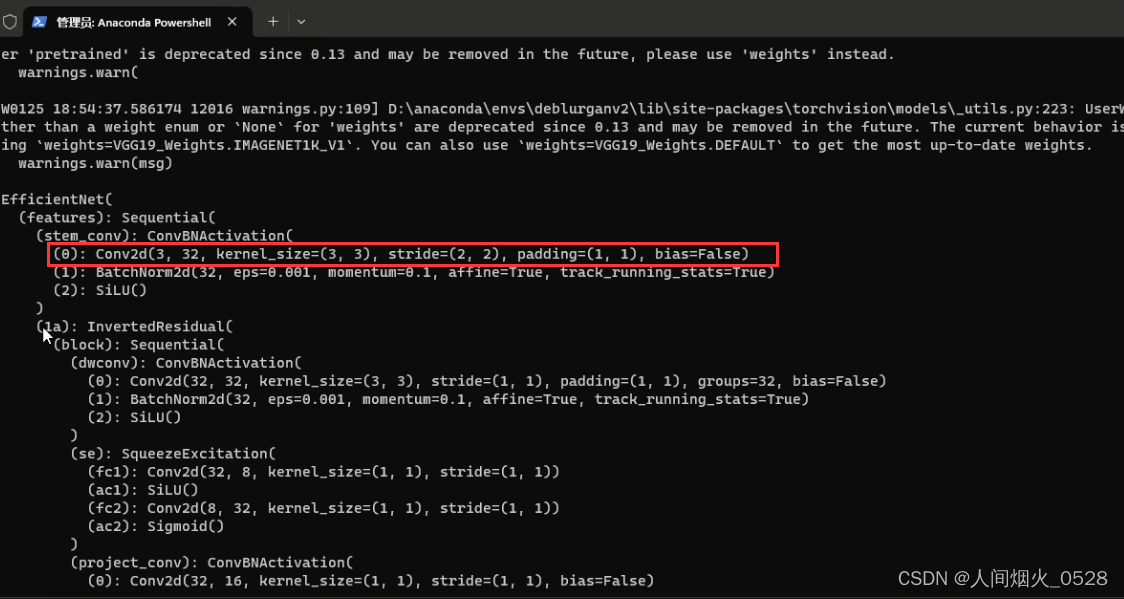
那么在这里经过stem_conv这一层之后,就会变为原来的一半,第一层记录在stem_conv这里,经过(1a)不变,经过(2a)又缩小了一半,第二层记录在2a这里,依次往下,找到所有5个可以缩小为原来一般的层;在代码中过的self.enc0=nn.Sequential(*self.features[0:2])表示从0-2缩小为原来的一半(刚刚说的stem_conv缩小为原来的一半,1a没有发生变化,合并到一起作为enc0),依次都是,如下图:

backbone中的特征提取部分就改到这里
还有,全连接部分还需要修改,维度还需要对应,就是上一层输出的维度和下一层输出的维度相对应,如下图所示:
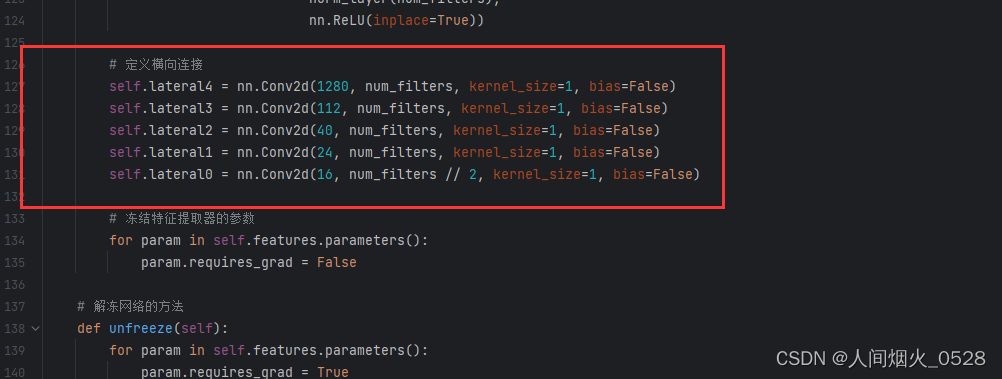
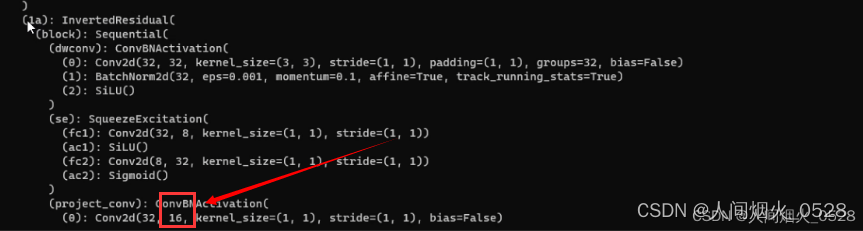
怎么找对应的维度呢,还是需要回到打印出来的网络架构中去寻找,刚刚可以看到enc0输出的维度是16,与上面的相对应,通过依次查找输出的维度,并对代码进行更改(其实就是告诉网络,输入输出的维度关系完成全连接!!)
主要修改了2个地方:
1.enc部分要注意哪些部分是原来图的一半(哪些enc0输出是上一层的一半)
2.横向连接部分的维度要和框架相对应(enc0是一半的输出维度是多少,就改为多少)
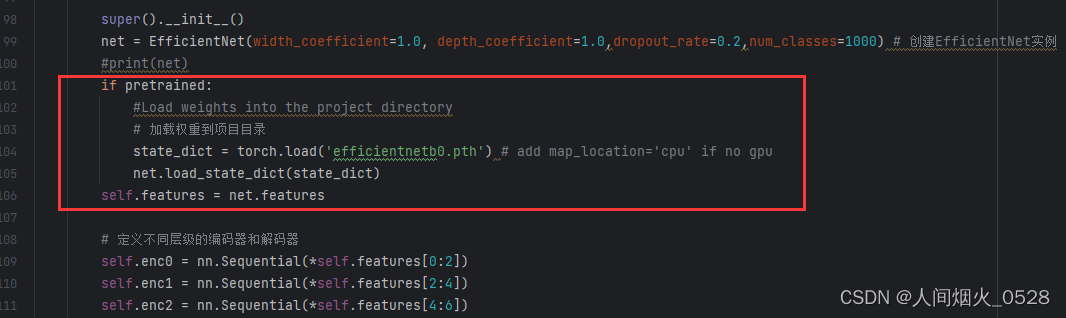
如果要加载预训练权重,就在创建完网络的部分进行加载
(权重文件放在这个目录下面,预训练权重同样通过百度去搜索和下载,权重文件和运行的模型相对应):
另外。在fpn_efficientnet里面还需要引用efficient,因为这里实例化了efficientnet,需要告诉它从哪儿来的,这部分还需要改,如下图:
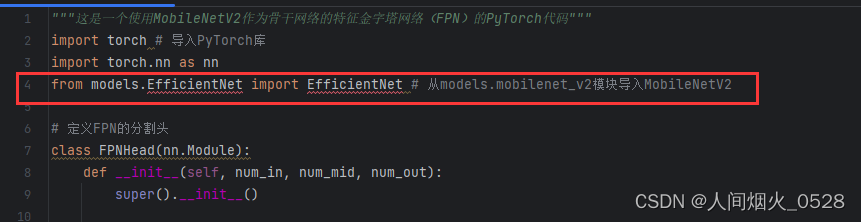
另外。才yaml文件中,需要指定模型,修改如下:
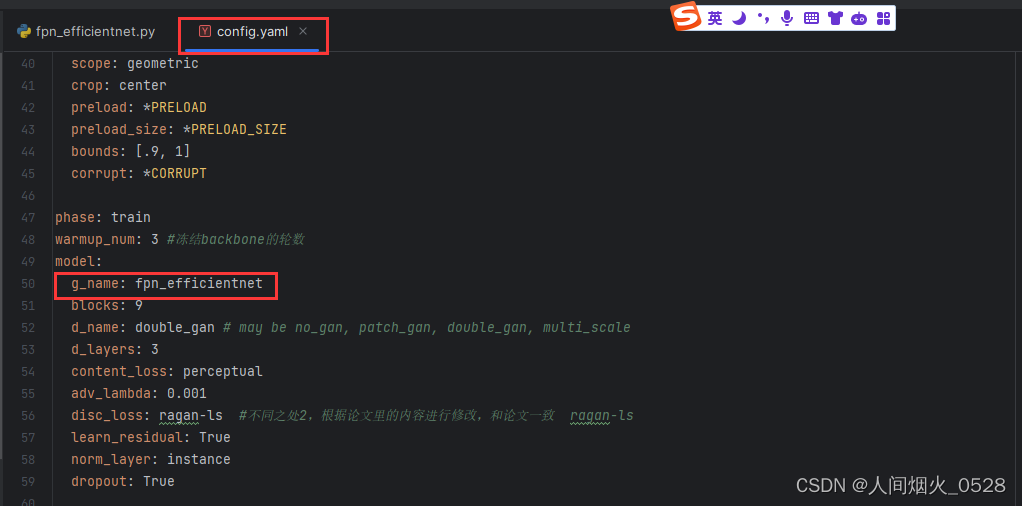
另外。在models文件夹下networks.py文件开头加入fpn_efficientnet的声明,告诉他有这个文件,其实前面都是讲backbone怎么提取特征,符合这个网络的要求,在这部分更多的是建立backbone和主干网络的关系,至于损失函数等都没有更改,如下图:
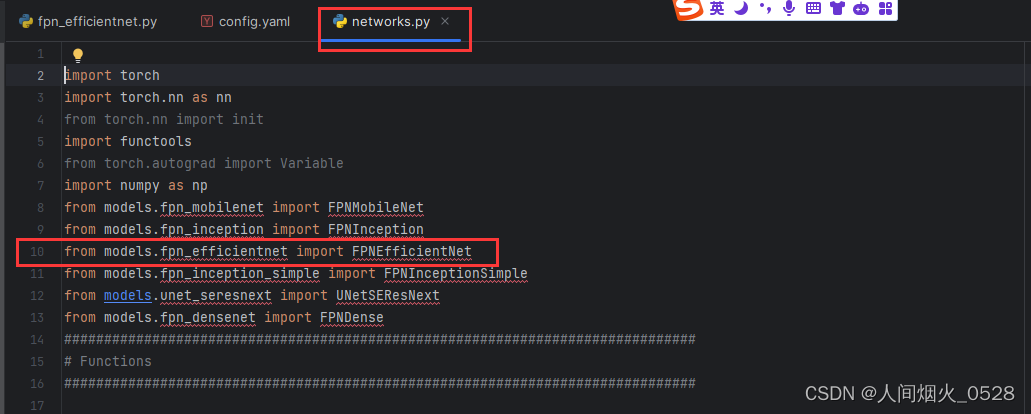
另外。在第316行get_generator函数中新增fpn_efficientnet调用选择,如下图
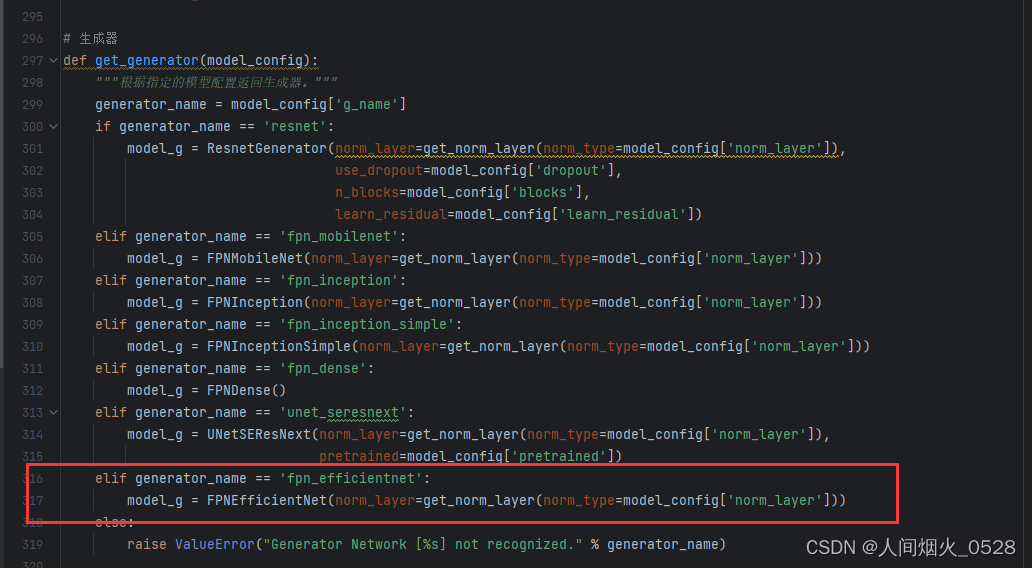
**更换不同的backbone,对性能指标的影响
PSNR指标对比
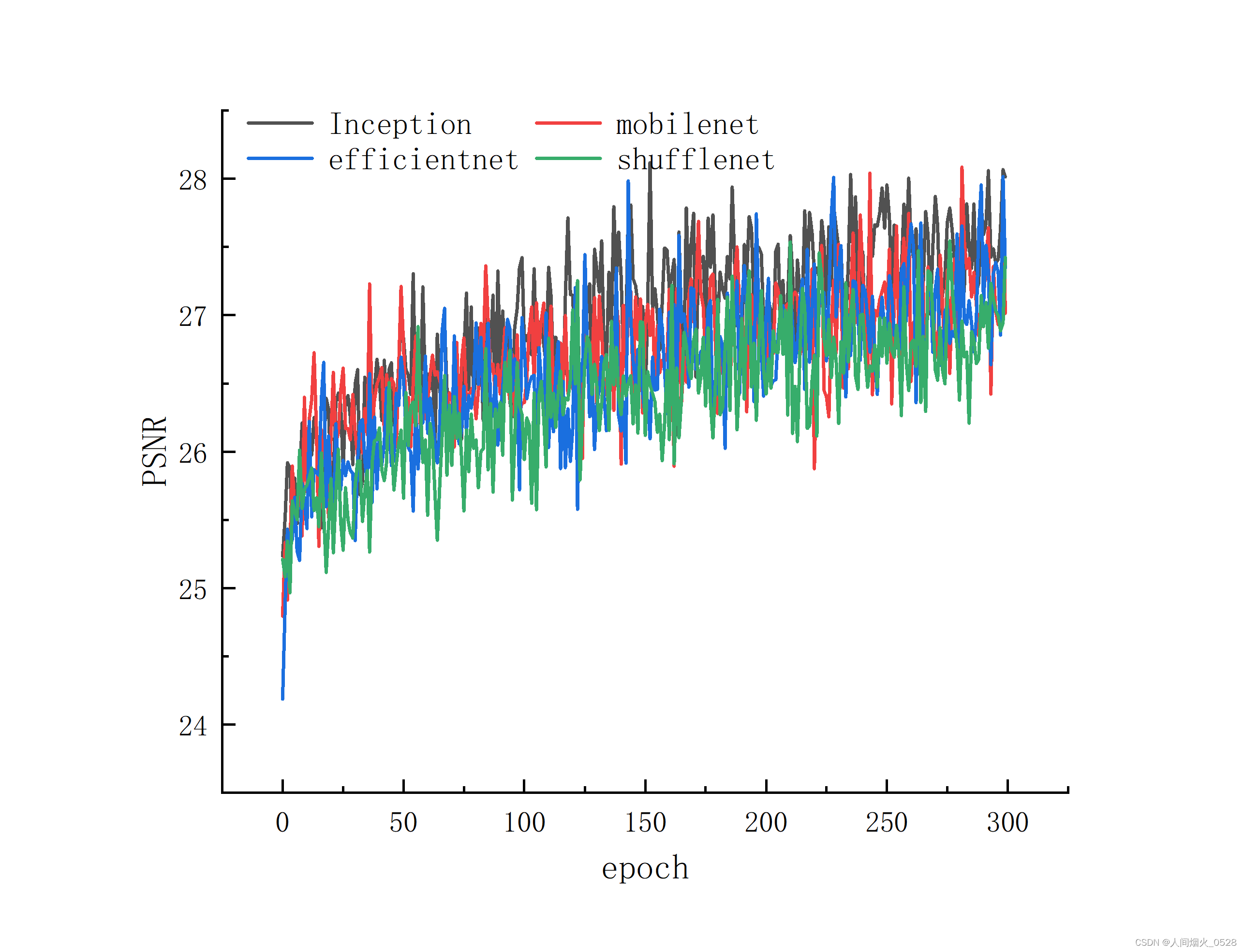
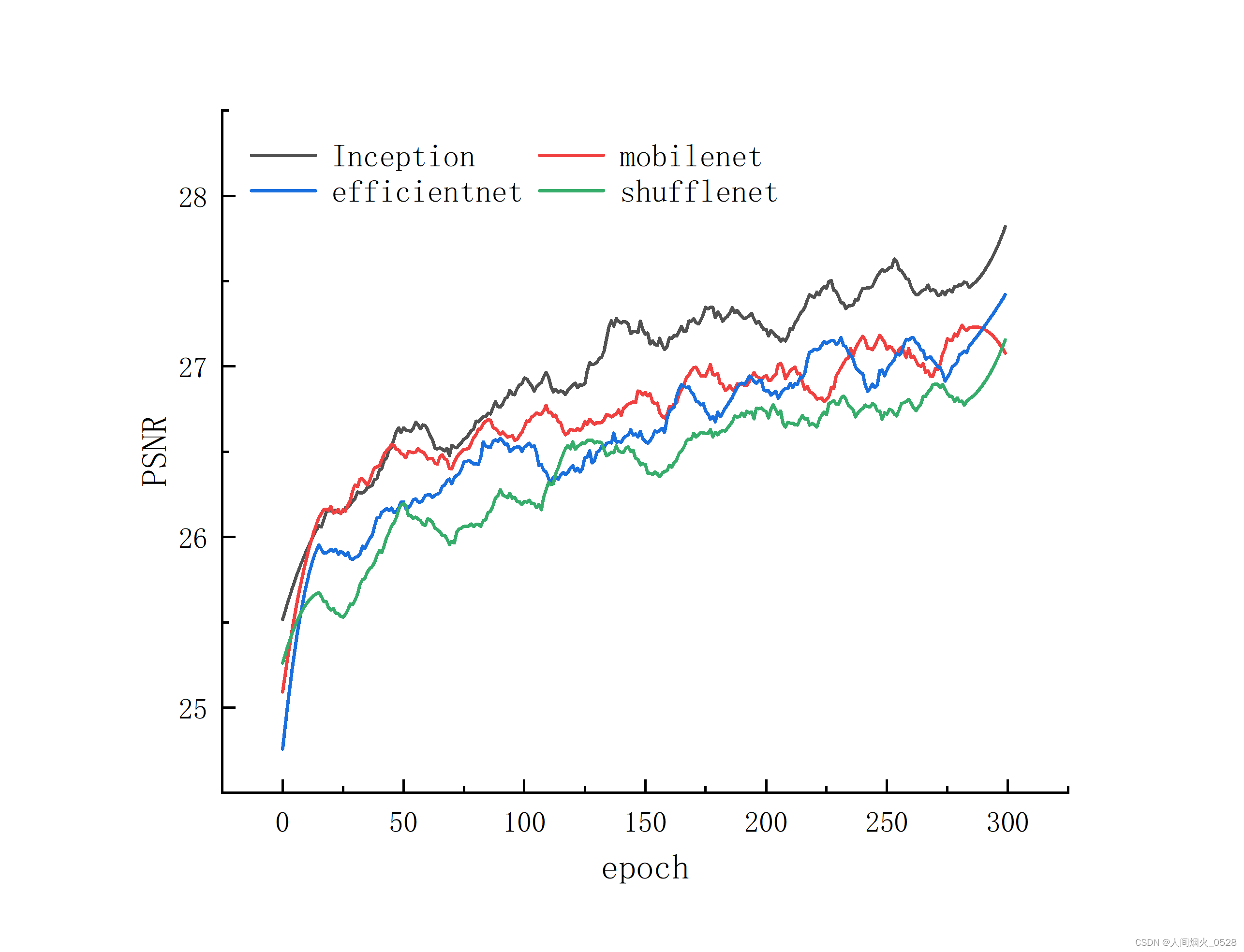
PSNR指标对比平滑操作(相邻30个像素点取平均)
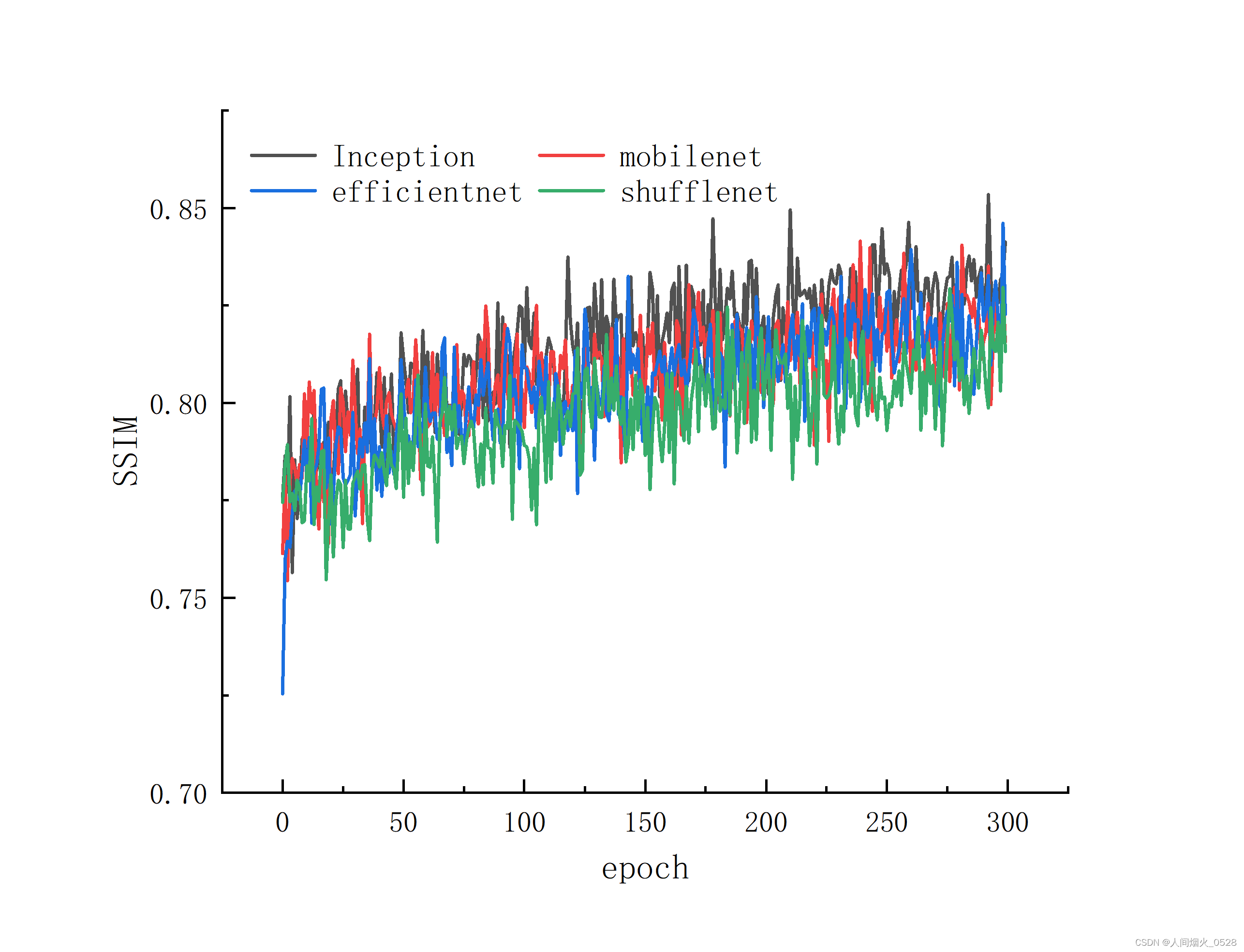
SSIM指标对比
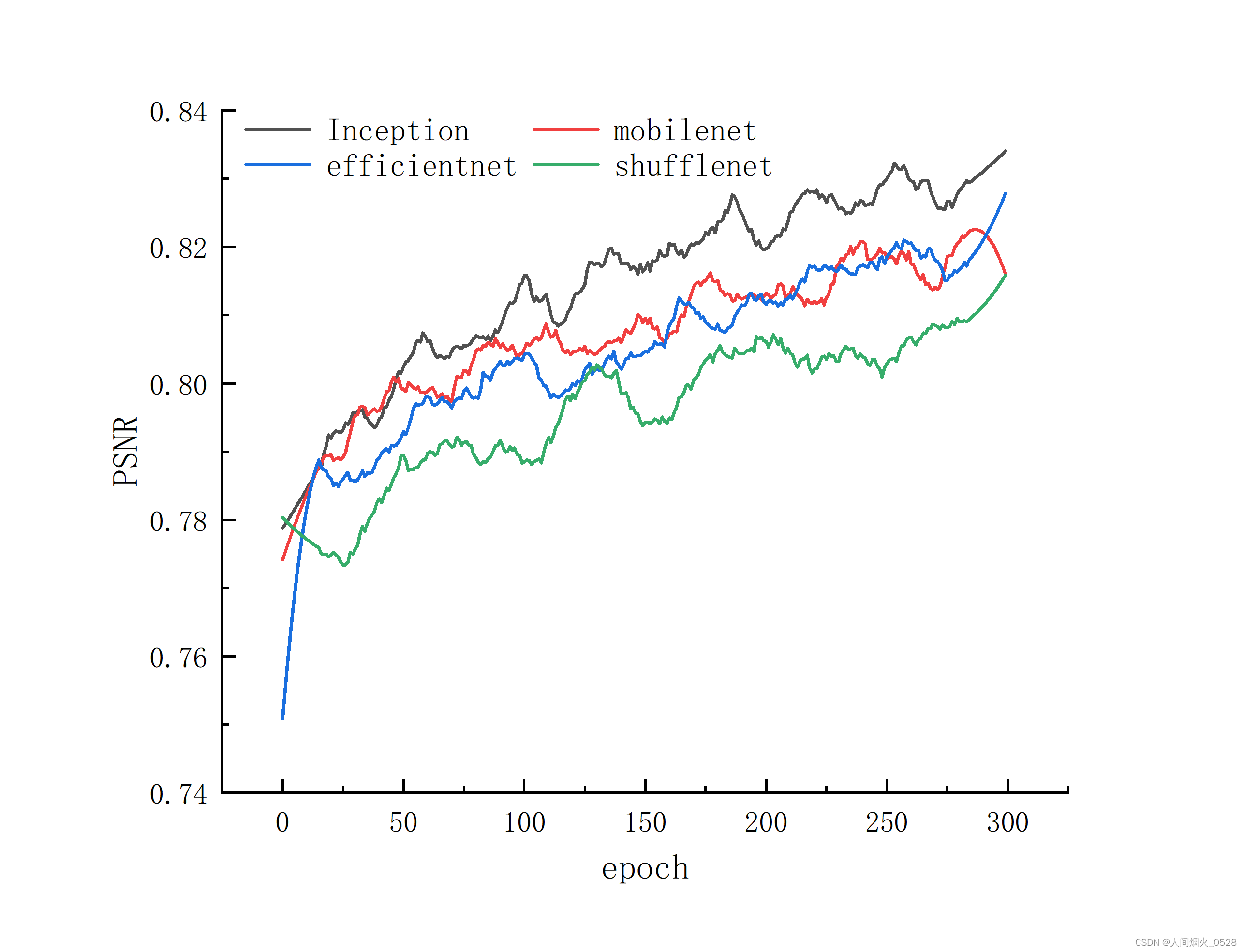
SSIM指标对比平滑操作**
总结:
1.Inception为骨干的网络效果最好(毕竟比较深,但是计算量大,推理时间慢)
2.轻量级网络mobilenet,efficientnet和shufflenet为骨干网络时,指标会有相应的下降,主要原因还是网络结构简单,但是速度快,能够实现实时效果
3.后续的改进方向,提高Inception骨干网络的速度或者提高轻量级的效果,看看是否能够通过添加更高效的模块,使之有所改进
4.更改数据集,如果数据集没有这么复杂,也许轻量级网络也可以有很好的效果,可以和作业场景相结合一下,也许作业场景并没有那么复杂,也不需要更深的网络,前提是需要有数据集

















 1343
1343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









