







编译原理实验——LL(1)文法分析
1、实验目的与内容
先输入一段文法,自动提取左公共因子,消除左递归,构建预测分析表。在输入一个表达式,进行表达式的分析。

文法由文件输入,如上图所示,要分析的表达式由控制台输入。
2、程序总体设计思路和框架
3、主要的数据结构和流程描述
struct grammer_node //存放文法规则的节点
{
string non_ter_sym; //产生式左边的非终结符号
vector<string> result; //产生式结果
};
vector<grammer_node *> all_gram; //存放所有的产生式
char non_ter_sym = 'Z'; //如果需要新的非终结符号,则使用
//void handle_grammer()
//建立二维映射关系
set<char> NTS_fir_set[128]; //非终结符号的first集
set<char> ri_fir_set[128][100]; //右边候选式的first集合,因为使用二维数组来存,建立映射,所以文法不能超过10条,如果两条产生式的候选式相同,这个结构是分别存储了
set<char> NTS_foll_set[128];
set<char> selc_set[128][100]; //前一个参数填写char,表示非终结符号映射,后一个参数填写数字
int analy_table[128][20];//分析表
主要数据结构如上。
4、测试结果与说明
为了直观的看到文法提取公共左因子和消除左递归的情况,我们选择将新生成的文法打印出来。
提取左公共因子
测试文法:
“>“表示箭头,”@“表示” ϵ \epsilon ϵ"。
S>ab|abc|abcd|bc|bcd|bcde|g
E>yu|y|S
测试结果:

消除左递归
测试文法:
E>E+T|T
T>T*F|F
F>(E)|i
测试结果:

LL(1)分析
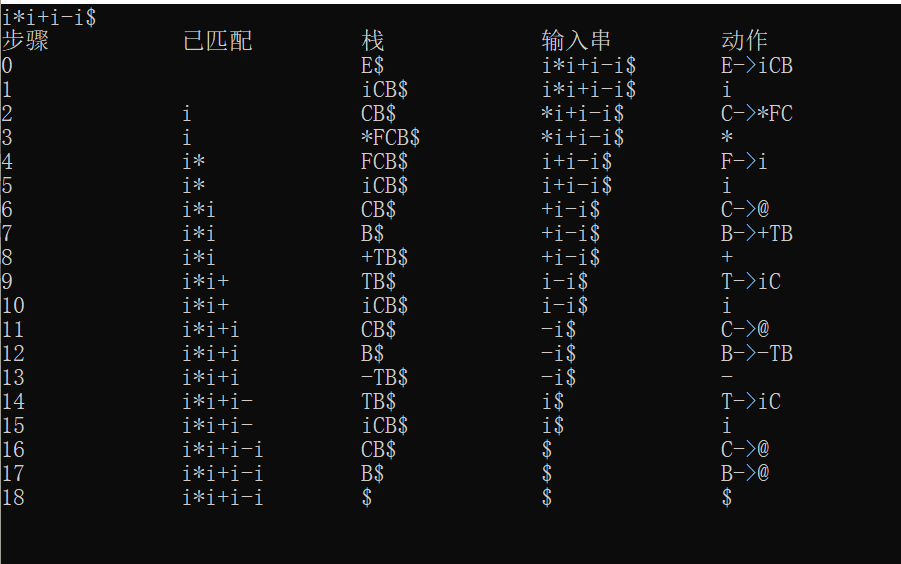
输入表达式:
i*i+i-i$
输入文法:
E>TB
B>ATB|@
T>FC
C>MFC |@
F>(E) | i
A > + | -
M > * | /
测试结果:
5、实验收获与反思
这个实验稍微有点难度,尤其是提取公共左因子的算法,也是想了很久,这方面网上的资料比价少,自己没有参考别人的资料,从头到尾写出来,虽然辛苦,但是还是比较有成就感的。

















 5639
5639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









