






Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
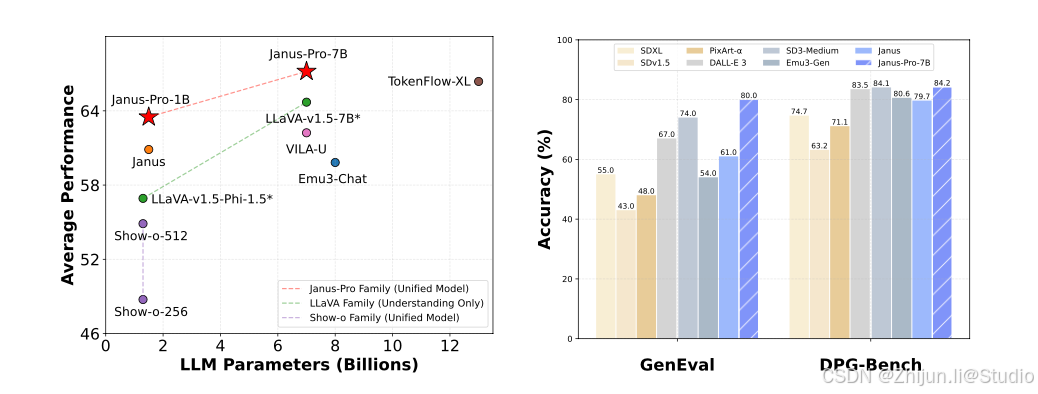
0.性能数据
双解码器协同,拳打LLAVA,脚踢DALLE
1. 模型架构
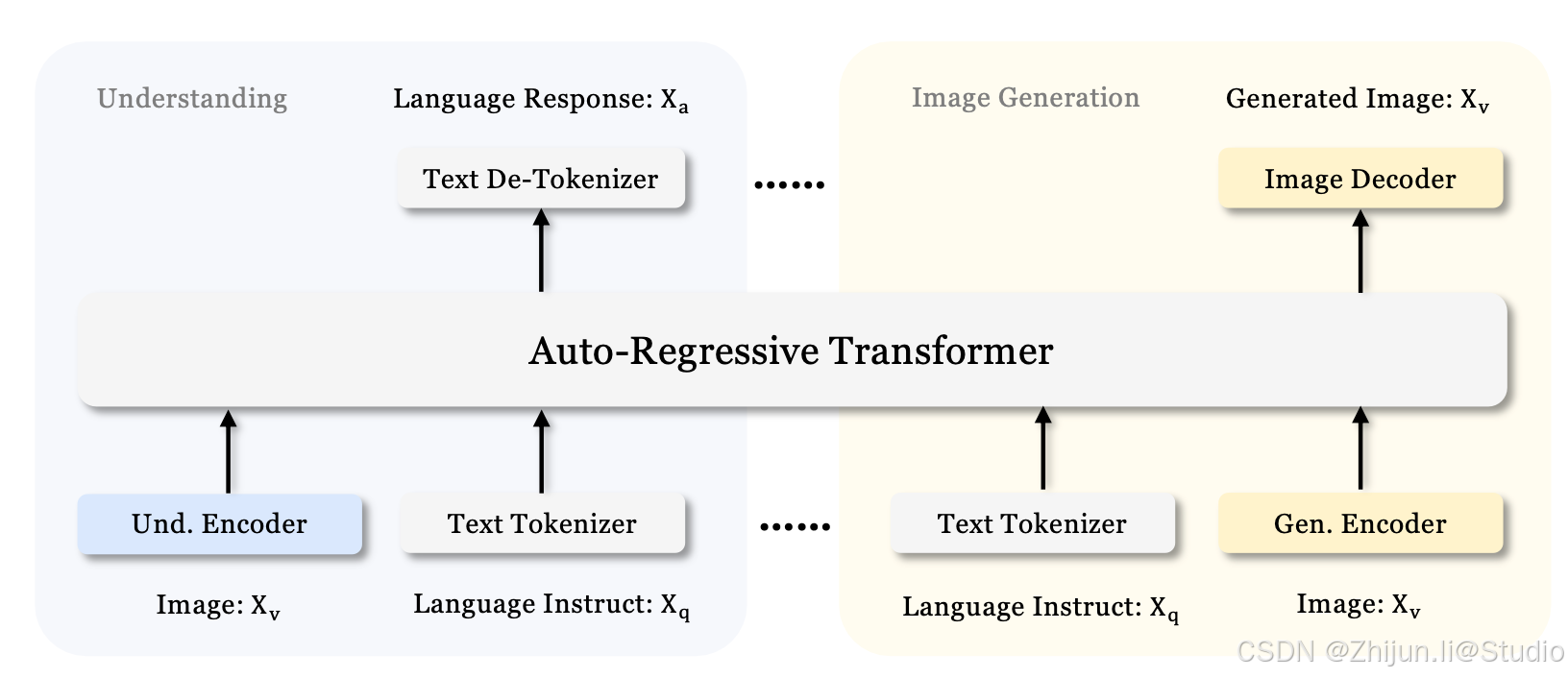
1.1 双重视觉编码器
-
理解编码器 (Understanding Encoder):
使用 SigLIP-Large-Patch16-384 作为视觉特征提取 backbone,将图像转化为高维语义特征。- 将 2D 网格特征展开为 1D 序列,通过一个两层 MLP 的 “理解适配器 (Understanding Adaptor)” 将这些特征嵌入 LLM 的输入空间。
-
生成编码器 (Generation Encoder):
使用 VQ Tokenizer 将图像离散化为一串 ID,进一步通过两层 MLP 的 “生成适配器 (Generation Adaptor)” 映射到 LLM 的输入空间。- 由于视觉理解和视觉生成所需的特征表征不同,二者在编码阶段完全分离,避免在同一编码器中出现冲突。
1.2 自回归 Transformer 统一处理
- LLM 基础:
使用 DeepSeek-LLM(有 1.5B 和 7B 两种规模),上下文窗口为 4096。 - 输入拼接:
将图像特征序列与文本 Token 序列级联后送入 LLM,输出时使用内置文本预测头或随机初始化的图像预测头进行自回归解码。 - 自回归框架:
整体是标准的 “Auto-Regressive” 生成流程,可同时处理文本和图像 Token 的预测。
1.3 其他实现细节
- 序列打包 (Sequence Packing):
在训练中将多模态数据、纯文本数据、文本-图像数据混合打包至一个 batch,提升 GPU 利用率和训练效率。 - 图像预处理:
- 多模态理解场景下:将图像长边缩放至 384,短边补灰色背景 (RGB: 127,127,127),得到 384×384 的输入。
- 文本生成图像场景下:将图像短边缩放至 384,然后再裁切长边到 384,方便后续的 VQ Tokenizer 离散化操作。
2. 数据
2.1 多模态理解数据
- DeepSeek-VL2:
在原有 Janus 数据的基础上,新增约 9000 万数据样本。
主要包括:- 大规模图文描述数据(如 YFCC 等)。
- 表格、文档、图表理解数据(Docmatix 等)。
- 多语言、对话式数据(包含中文对话)。
- 覆盖范围:
不仅有常规的图文匹配/对话,还涉及各种专门领域(文档表格、MEME 理解等),极大拓宽了模型在多模态上的适应度。
2.2 文本生成图像数据
- 真实数据 + 合成数据:
- 在 Janus-Pro 中,为了提高图像生成的质量和稳定性,引入了约 7200 万条“高美感 (Aesthetic)”的合成数据。
- 该合成数据从公开的高质量 prompt 生成,与真实数据按 1:1 的比例混合。
- 优势与收敛:
- 合成数据在风格多样性、内容可控性上更好,模型收敛速度更快;
- 显著提升了输出图像细节和审美质量,并减少了生成不稳定、模糊等问题。
3. 训练策略
3.1 三阶段训练流程
-
阶段 I:
- 主要在 ImageNet 类别上进行“像素依赖建模”,即根据简单类别提示生成对应图像;
- 固定 LLM,仅训练两个适配器和图像预测头(image head);
- 训练步数更长,以确保模型熟练掌握图像解码的能力。
-
阶段 II:
- 舍弃 ImageNet 类别提示,直接使用普通文本-图像 paired data 进行大规模统一预训练;
- 除了视觉理解和生成编码器外,LLM 以及其他组件参数都可更新(相较于 Janus,减少了重复和低效训练)。
- 在实际实验中,通过引入 Early Stopping(大约在 270K 步时停止),保证效率与性能平衡。
-
阶段 III:
- 监督微调 (SFT),涵盖多模态指令、纯文本指令、文本-图像指令三类数据;
- 数据比例由原先的 7:3:10 调整为 5:1:4,略微减少文本-图像比重,可在保持高质量生成的同时进一步提升理解能力;
- 在本阶段会开放理解编码器 (Understanding Encoder) 的参数更新,从而对视觉理解能力进行细化强化。
3.2 超参数与优化器细节
- 优化器方面:
- 采用 AdamW (β1=0.9, β2=0.95),无权重衰减 (Weight Decay=0.0)。
- 学习率在各阶段分别设置不同的固定值(如 1e-3, 1e-4, 4e-5)。
- 训练时长与批大小:
- 阶段 I: 2 万步、批大小 256(1B/1.5B 模型)或相应配置;
- 阶段 II: 36 万步(实际使用 Early Stopping 大约定格在 27 万步左右),批大小 512;
- 阶段 III: 4~8 万步以内,批大小 128;
- 训练框架与硬件:
- 基于 HAI-LLM 框架进行分布式训练,1B/1.5B 需要约 16 个节点训练 9 天,7B 版本在 32 个节点 14 天完成。
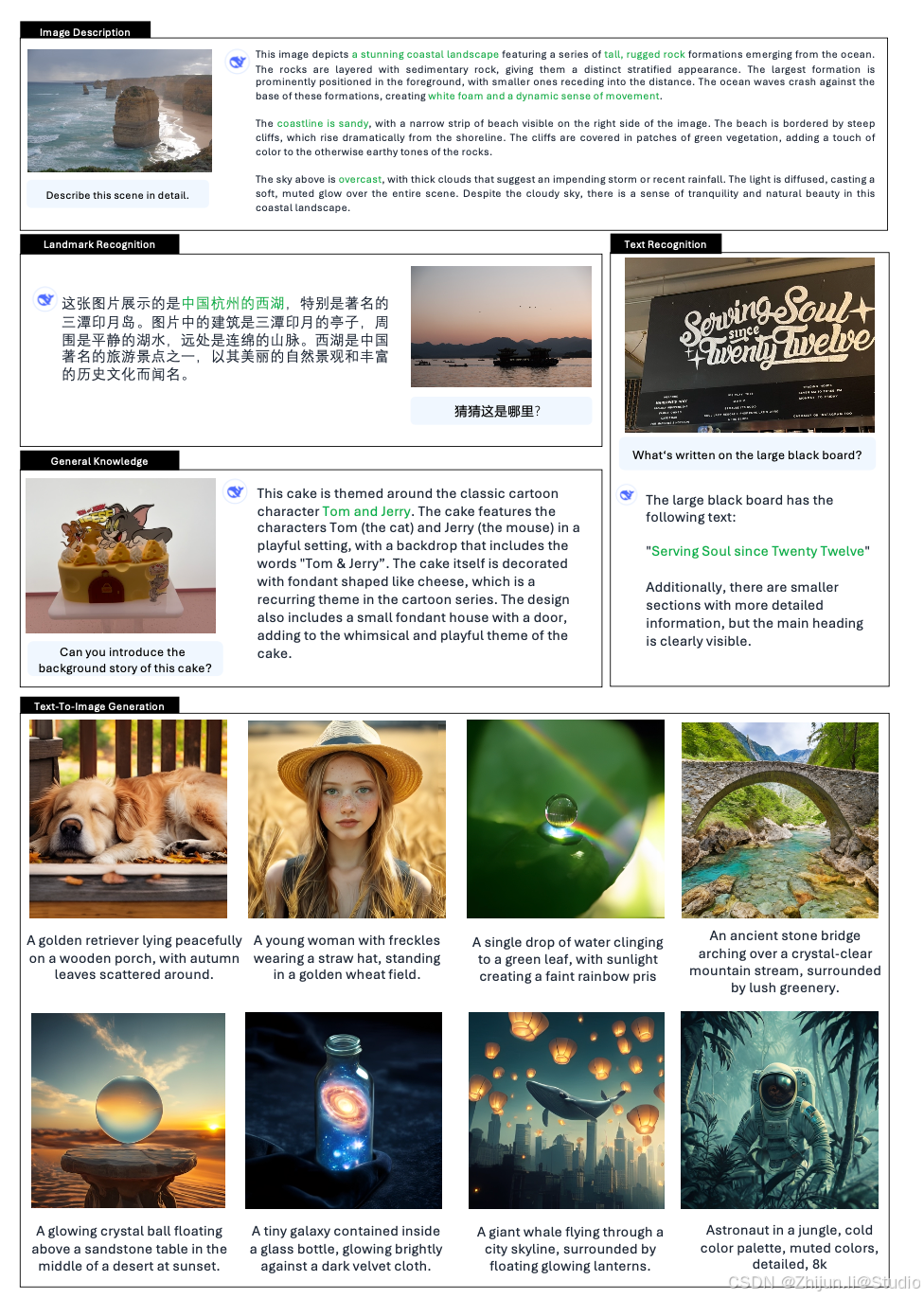
4. 小结
-
架构层面:
Janus-Pro 通过视觉编码解耦(Understanding Encoder + Generation Encoder + 统一的 AR Transformer)解决多模态理解和生成之间特征冲突的问题; -
数据层面:
拥有更大规模、多样性强的多模态和文本-图像数据,尤其加入 1:1 的高质合成数据,提高了图像生成的美学质量与稳定性; -
训练层面:
新的三阶段训练策略优化了不同数据在各阶段的配比,使得模型在理解与生成方面都能充分学习,最终在多个基准上取得了显著领先。
完整技术报告:https://github.com/deepseek-ai/Janus/blob/main/janus_pro_tech_report.pdf



















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











