







 本文详细介绍了Elasticsearch的基本概念,如索引、类型和文档,以及其工作原理——倒排索引。通过Docker容器安装ES和Kibana,并提供了配置挂载目录的步骤。同时,文章还涵盖了如何在ES中进行初步检索、新增、查看、更新和删除文档,以及批量操作和乐观锁的使用。此外,还展示了如何处理并发修改冲突。
本文详细介绍了Elasticsearch的基本概念,如索引、类型和文档,以及其工作原理——倒排索引。通过Docker容器安装ES和Kibana,并提供了配置挂载目录的步骤。同时,文章还涵盖了如何在ES中进行初步检索、新增、查看、更新和删除文档,以及批量操作和乐观锁的使用。此外,还展示了如何处理并发修改冲突。
ElasticSearch
一、简介
mysql作为数据持久化,ElasticSearch提供检索功能
基本概念
| ES | MySQL |
|---|---|
| index(索引) | database |
| type(类型) | table |
| document(文档) | record(记录) |
在ES中,数据是以
json格式存储的
ES模型

ES的工作原理
倒排索引
将要保存的数据data进行分词后保存到一个【分词-索引】表中,并且一直维护这个表。当需要检索特定数据时,就可以快速的根据这张表返回相应数据。
二、安装ES
使用docker容器安装
1、elasticsearch=>mysql kibana=》navicate
docker pull elasticsearch:7.4.2
docker pull kibana:7.4.2
版本要统一
2、配置挂载目录等等
# 将docker里的目录挂载到linux的/mydata目录中
# 修改/mydata就可以改掉docker里的
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
#查看系统当前内存使用情况
free -m
# es可以被远程任何机器访问
echo "http.host: 0.0.0.0" >/mydata/elasticsearch/config/elasticsearch.yml
#查询docker日志
docker logs [容器id]
# 递归更改es目录权限,否则访问失败
chmod -R 777 /mydata/elasticsearch/
#启动Elastic search
# 9200是用户交互端口 9300是集群心跳端口
# -e指定是单阶段运行
# -e指定占用的内存大小,生产时可以设置32G
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
2、配置挂载目录等等
#查看当前虚拟机的ip地址
ifconfig
#启动kibana:
sudo docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.56.10:9200 -p 5601:5601 -d kibana:7.4.2
查看Linuxip地址的方法
- ifconfig
- ip addr
- hostname -I
三、初步检索
1、检索es信息
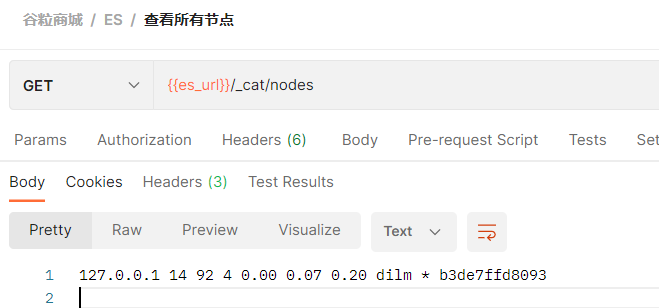
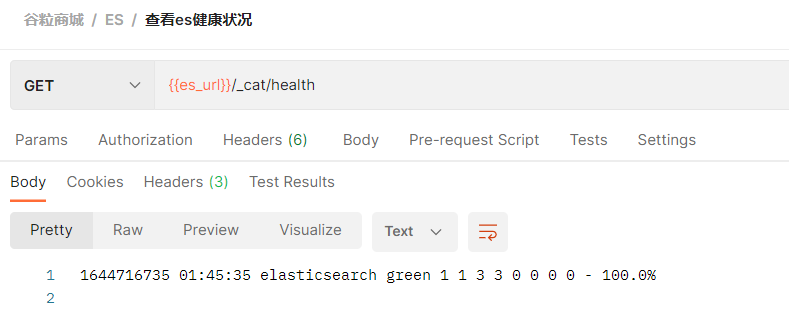
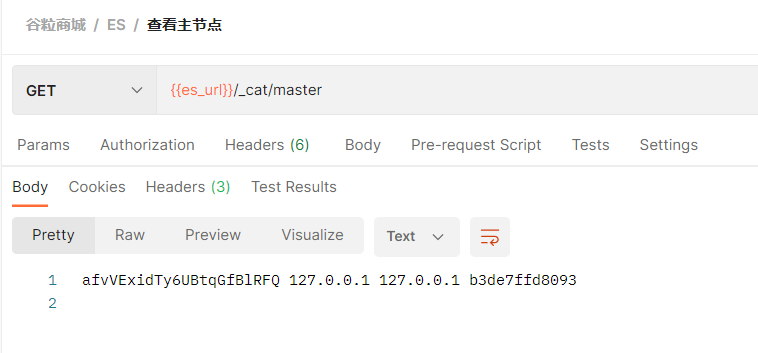
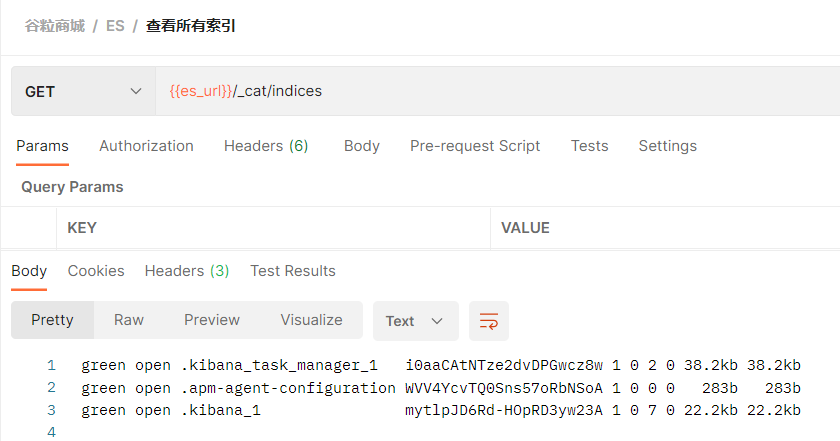
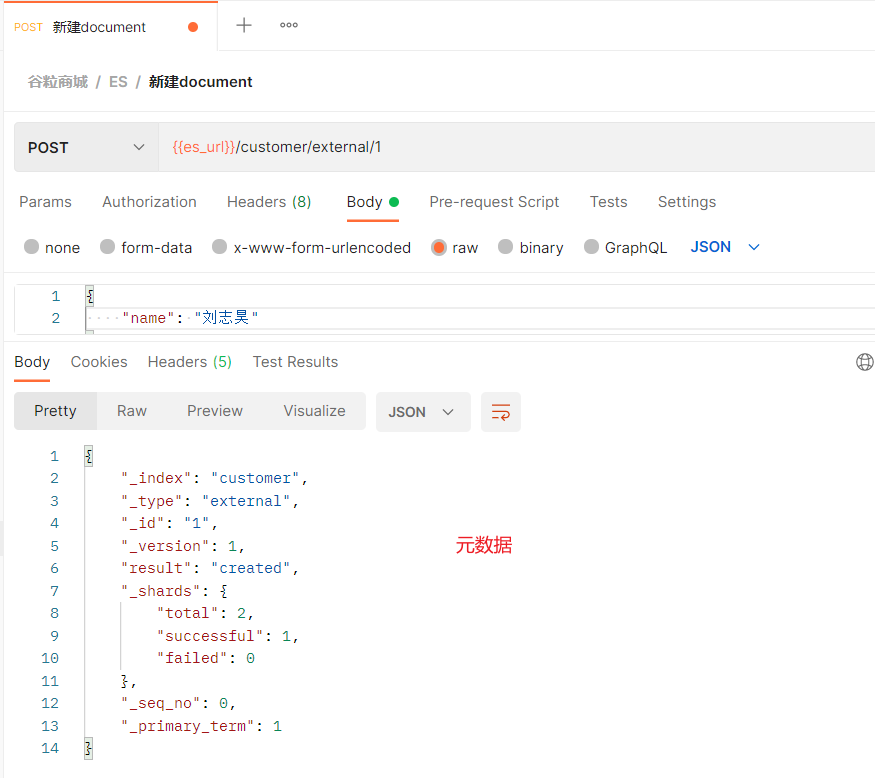
2、新增文档
post/put 必须指定索引跟类型
put时:必须指定id,第一次状态为created 以后为updated
post时:如果指定id,与put作用相同;
如果不指定id,那么会自动生成随机id,并且状态永远都是created
发送的参数为json格式
3、查看文档&乐观锁
GET /索引名/类型名/文档id
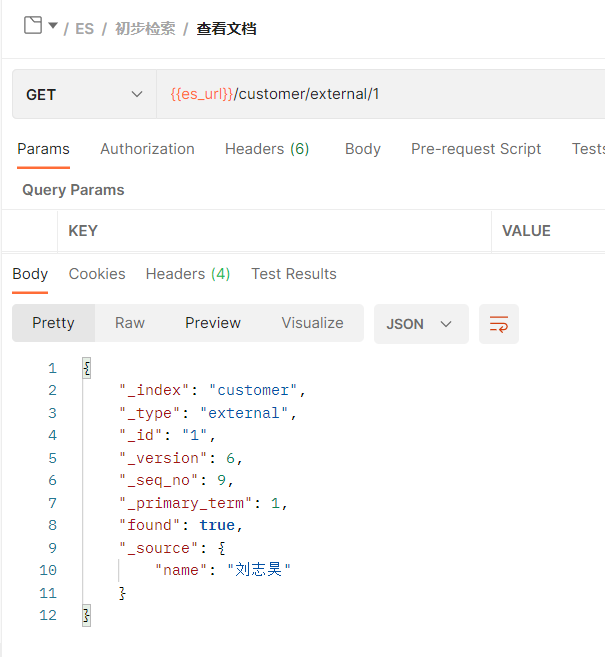
乐观锁用法
增加if_seq_no=xxx&if_primary_term=xxx参数
当seq_no匹配的时候才会修改 否则不会修改
模拟这个操作
1、查看id=6的文档,得到seq_no和primary_trem
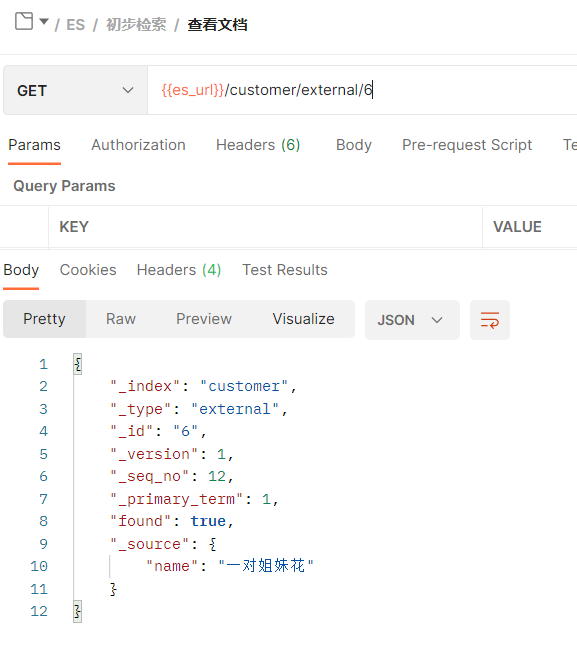
2、有两个请求查到了这条记录 并且想修改


假设1号修改先发出
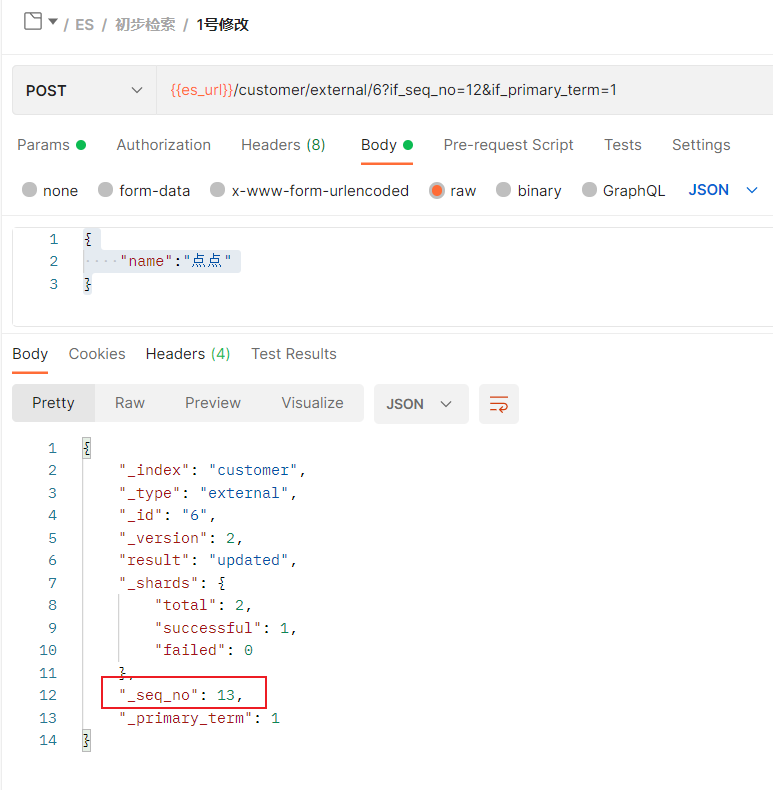
由于seq_no已经改变 所有2号修改失败
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[6]: version conflict, required seqNo [12], primary term [1]. current document has seqNo [13] and primary term [1]",
"index_uuid": "PfpeoFkmRwms3i8hpOj5IQ",
"shard": "0",
"index": "customer"
}
],
"type": "version_conflict_engine_exception",
"reason": "[6]: version conflict, required seqNo [12], primary term [1]. current document has seqNo [13] and primary term [1]",
"index_uuid": "PfpeoFkmRwms3i8hpOj5IQ",
"shard": "0",
"index": "customer"
},
"status": 409
}
如果2号修改想要成功,必须重新获取seq_no
4、更新文档
前面创建的时候介绍了两种方法,还有另一种方法
POST /索引名/类型名/id/_update
{
"doc":{
"name":"111"
}
}
与之前两种方法的区别:会将当前数据和发来的参数进行对比,如果相同,那就什么都不做。
5、删除文档或者索引
不能删除类型
DELETE customer/external/1
DELETE customer
删除文档后,查询:“found”:false
批量操作–bulk
POST /索引/分类/_bulk
两行为一个整体
{"index":{"_id":"1"}}
{"name":"a"}
{"index":{"_id":"2"}}
{"name":"b"}
注意格式json和text均不可,要去kibana里Dev Tools
{action:{metadata}}\n
{request body }\n
{action:{metadata}}\n
{request body }\n
不同于数据库的事务,某一条执行失败是,其它该成功的也会成功
POST /_bulk
对整个索引执行操作,因为没有在url中指定索引和分类,所以需要在requestbody中指定,"_index"和"_type"等等
POST /_bulk
{"delete":{"_index":"website","_type":"blog","_id":"123"}}
{"create":{"_index":"website","_type":"blog","_id":"123"}}
{"title":"my first blog post"}
{"index":{"_index":"website","_type":"blog"}}
{"title":"my second blog post"}
{"update":{"_index":"website","_type":"blog","_id":"123"}}
{"doc":{"title":"my updated blog post"}}
测试样本数据模板:
POST /bank/account/_bulk
https://gitee.com/xlh_blog/common_content/blob/master/es%E6%B5%8B%E8%AF%95%E6%95%B0%E6%8D%AE.json
{
"account_number": 1,
"balance": 39225,
"firstname": "Amber",
"lastname": "Duke",
"age": 32,
"gender": "M",
"address": "880 Holmes Lane",
"employer": "Pyrami",
"email": "amberduke@pyrami.com",
"city": "Brogan",
"state": "IL"
}

















 7078
7078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









