






在日常的开发过程中,难免会遇到有两个list数据,第一:先要遍历出第一个来,获取到的每一个id然后去遍历第二个对比找对应的内容。
例如:有一个user数据,和 UserArticle数据,就想找出每一个用户在UserArticle里对应的内容是多少,一下就会想到双层for循环遍历,先遍历user然后找到每一个用户id 去遍历UserArticle判断对比找出内容
先创建两个实体类User和UserArticle
User类:
import lombok.Data;
@Data
public class User {
private Long userId;
private String userName;
}
UserArticle 类:
import lombok.Data;
@Data
public class UserArticle {
private Long userId;
private String content;
}
@Data注解:是 Lombok 库提供的一个注解
带来的几个主要好处:
-
自动生成 getter 和 setter 方法:对于类中所有的字段,Lombok 会自动为其生成标准的 getter 和 setter 方法。这样你就无需手动编写这些方法了。
-
toString() 方法:Lombok 会为你的类生成一个
toString()方法,默认情况下该方法将打印出对象的所有非静态字段及其值,这对于调试非常有用。 -
equals() 和 hashCode() 方法:这两个方法通常用于实现对象间的比较逻辑。Lombok 自动生成的
equals()和hashCode()方法遵循 Java 标准的做法,基于对象的属性进行比较和计算哈希码。 -
无参构造器:如果你没有定义任何构造器,Lombok 将为你添加一个默认的无参数构造器。这在很多场景下是非常有用的,比如在使用一些框架时(如 Spring),它们可能需要调用此类构造器来初始化对象。
-
全参数构造器:除了无参构造器外,Lombok 还会提供一个带有所有字段作为参数的构造器,方便直接通过所有属性创建实例。
-
提升开发效率:减少了大量的模板代码工作量,让开发者可以更专注于业务逻辑的实现,提高编码效率。
-
保持代码整洁:避免了大量的重复性代码,使得类文件看起来更为紧凑和清晰,易于维护。
在mian里面模拟一些数据
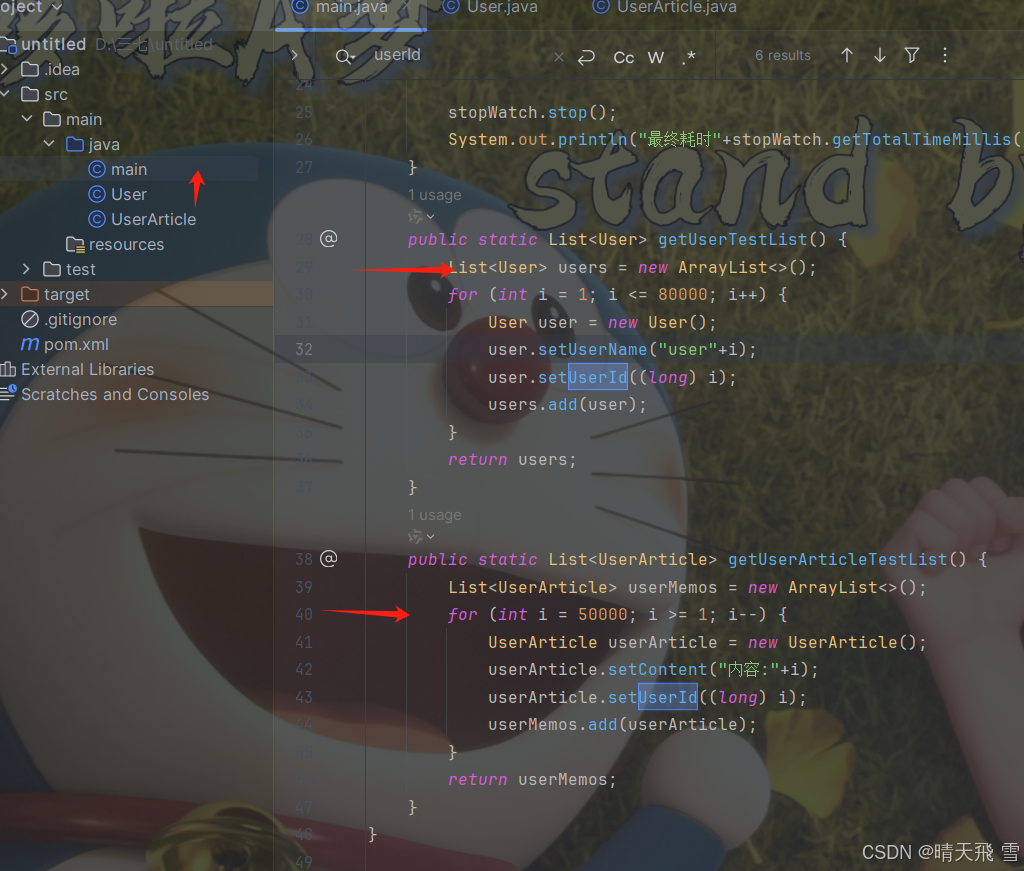
public static List<User> getUserTestList() {
List<User> users = new ArrayList<>();
for (int i = 1; i <= 80000; i++) {
User user = new User();
user.setUserName("user"+i);
user.setUserId((long) i);
users.add(user);
}
return users;
}
public static List<UserArticle> getUserArticleTestList() {
List<UserArticle> userMemos = new ArrayList<>();
for (int i = 50000; i >= 1; i--) {
UserArticle userArticle = new UserArticle();
userArticle.setContent("内容:"+i);
userArticle.setUserId((long) i);
userMemos.add(userArticle);
}
return userMemos;
}
接下来就是在主函数里执行查数据:
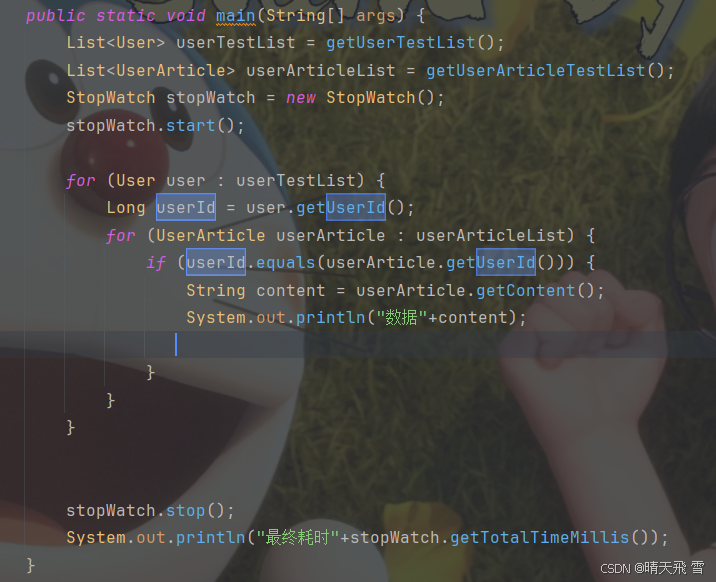
List<User> userTestList = getUserTestList();
List<UserArticle> userArticleList = getUserArticleTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
for (User user : userTestList) {
Long userId = user.getUserId();
for (UserArticle userArticle : userArticleList) {
if (userId.equals(userArticle.getUserId())) {
String content = userArticle.getContent();
System.out.println("数据"+content);
}
}
}
stopWatch.stop();
System.out.println("最终耗时"+stopWatch.getTotalTimeMillis());
来看看最终耗时:
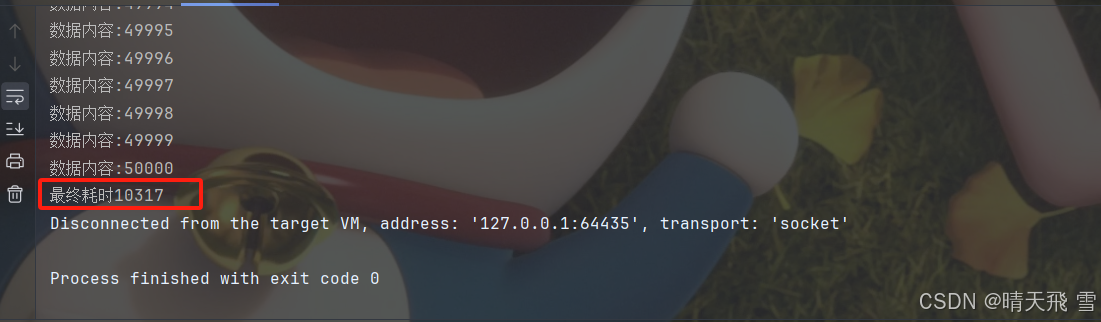
相当于迭代了 8W * 5W 次 ;数据量小还可以,那如果数据量更大呢?还能怎么优化一下
那再来来看看 加上 break 的一个耗时情况 :
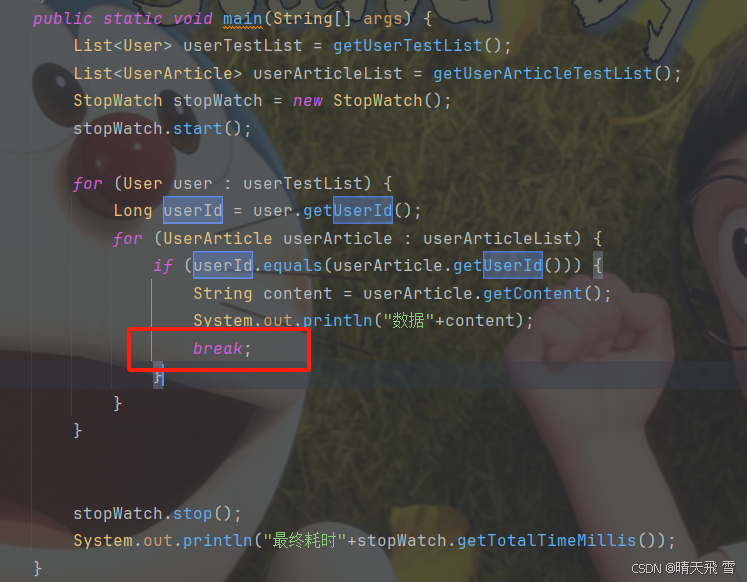
List<User> userTestList = getUserTestList();
List<UserArticle> userArticleList = getUserArticleTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
for (User user : userTestList) {
Long userId = user.getUserId();
for (UserArticle userArticle : userArticleList) {
if (userId.equals(userArticle.getUserId())) {
String content = userArticle.getContent();
System.out.println("数据"+content);
break;
}
}
}
stopWatch.stop();
System.out.println("最终耗时"+stopWatch.getTotalTimeMillis());
耗时:
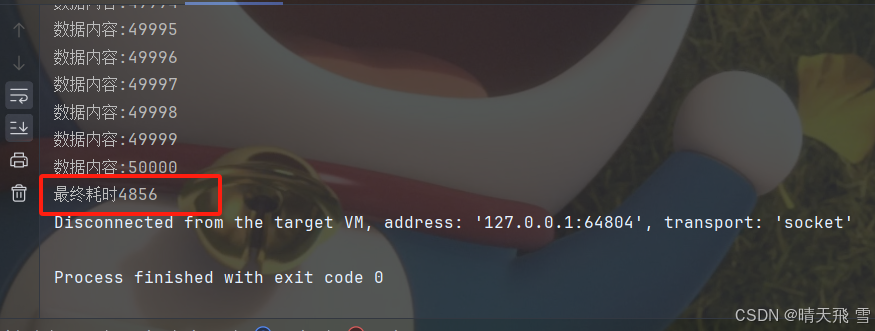
好像可以哎,耗时更少了,那还有没有其他优化的空间?
重点:转为Java8流来完成
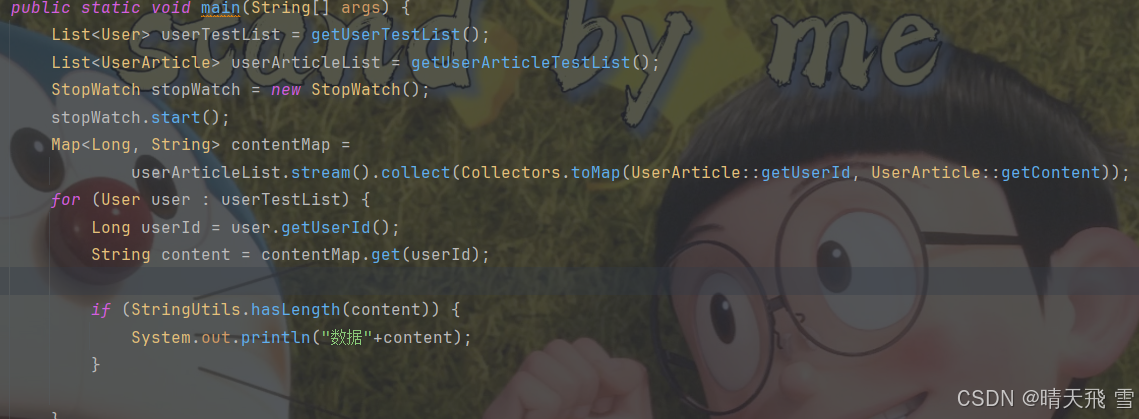
List<User> userTestList = getUserTestList();
List<UserArticle> userArticleList = getUserArticleTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
Map<Long, String> contentMap =
userArticleList.stream().collect(Collectors.toMap(UserArticle::getUserId, UserArticle::getContent));
for (User user : userTestList) {
Long userId = user.getUserId();
String content = contentMap.get(userId);
if (StringUtils.hasLength(content)) {
System.out.println("数据"+content);
}
}
stopWatch.stop();
System.out.println("最终耗时"+stopWatch.getTotalTimeMillis());
耗时:
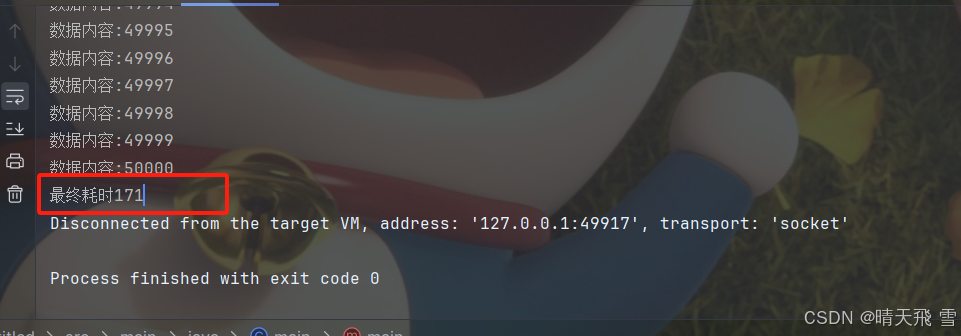
双层for相当于一个一个去对比找,就非常耗时,那如果弄成像数据库一样通过索引的方式,会不会更快一点。


















 5004
5004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











