







 本文详细介绍了C++中Lambda表达式的由来及其基本写法,深入探讨了Lambda表达式的语法构成,包括如何通过捕获列表传递变量以及如何正确使用mutable关键字等高级特性。
本文详细介绍了C++中Lambda表达式的由来及其基本写法,深入探讨了Lambda表达式的语法构成,包括如何通过捕获列表传递变量以及如何正确使用mutable关键字等高级特性。
目录
1. 为什么要有lambda表达式
lambda表达式的由来:C++中的每一个语法的创建都一定是有有需求才提出并创建的,要想了解lambda表达式我们首先来看一个例子:
#include <algorithm>
#include <functional>
int main()
{
int array[] = { 4, 1, 8, 5, 3, 7, 0, 9, 2, 6 };
// 默认按照小于比较,排出来结果是升序
std::sort(array, array + sizeof(array) / sizeof(array[0]));
// 如果需要降序,需要改变元素的比较规则
std::sort(array, array + sizeof(array) / sizeof(array[0]), greater<int>());
return 0;
}
我们可以看到上面要想换一种排序方式我们直接传入库函数中的仿函数即可,但是对于下面这种情况,对于我们自定义类型的排序我们就需要自己给出比较方法,虽然说也简单,但是我们可以发现我们自己写的比较方式就只在此处用一次然后基本就无用武之地了,而且还要给类型起名字,那么多的名字难免难起,所以使用仿函数是有诸多不便的。那么要是我们可以直接把我们的比较方式也写成一个匿名的函数直接写到要要传入的参数列表处那么将为我们省下大部分时间。所以为了实现这一便捷操作lambda表达式就诞生了。
struct Goods
{
string _name;
double _price;
};
struct Compare
{
bool operator()(const Goods& gl, const Goods& gr)
{
return gl._price <= gr._price;
}
};
int main()
{
Goods gds[] = { { "苹果", 2.1 }, { "相交", 3 }, { "橙子", 2.2 }, { "菠萝", 1.5 } };
sort(gds, gds + sizeof(gds) / sizeof(gds[0]), Compare());
return 0;
}2. lambda表达式
2.1 lambda表达式的基本写法
这里我们先来给出用lambda表达式来解决上面的问题:
struct Goods
{
string _name;
double _price;
};
int main()
{
Goods gds[] = { { "苹果", 2.1 }, { "相交", 3 }, { "橙子", 2.2 }, { "菠萝", 1.5 } };
sort(gds, gds + sizeof(gds) / sizeof(gds[0]),[](Goods g1,Goods g2)->bool
{
return g1._price <= g2._price;
});
return 0;
}这里的这里被红框框起来的就成为lambda表达式: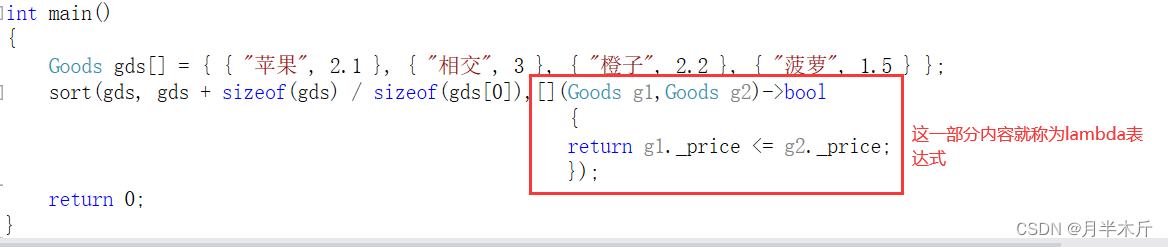
运行结果:我们可以看到这里lambda表达式和反函数起到了相同的作用都将我们自定义类型中的价格从小到大排序了。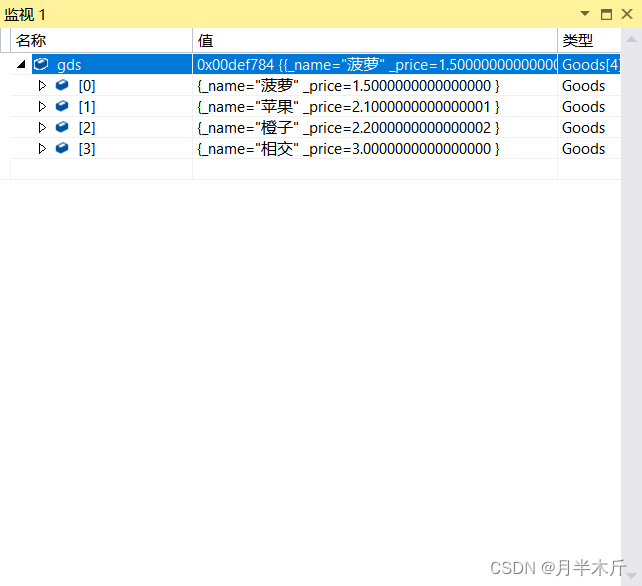
2.2 lambda表达式的语法
上面我们写了一个基本的lambda表达式那么我们接下来看看lambda表达式的语法,从而了解它的构成以及书写的主要事项。
首先我们来看lambda表达式的五大构成部分: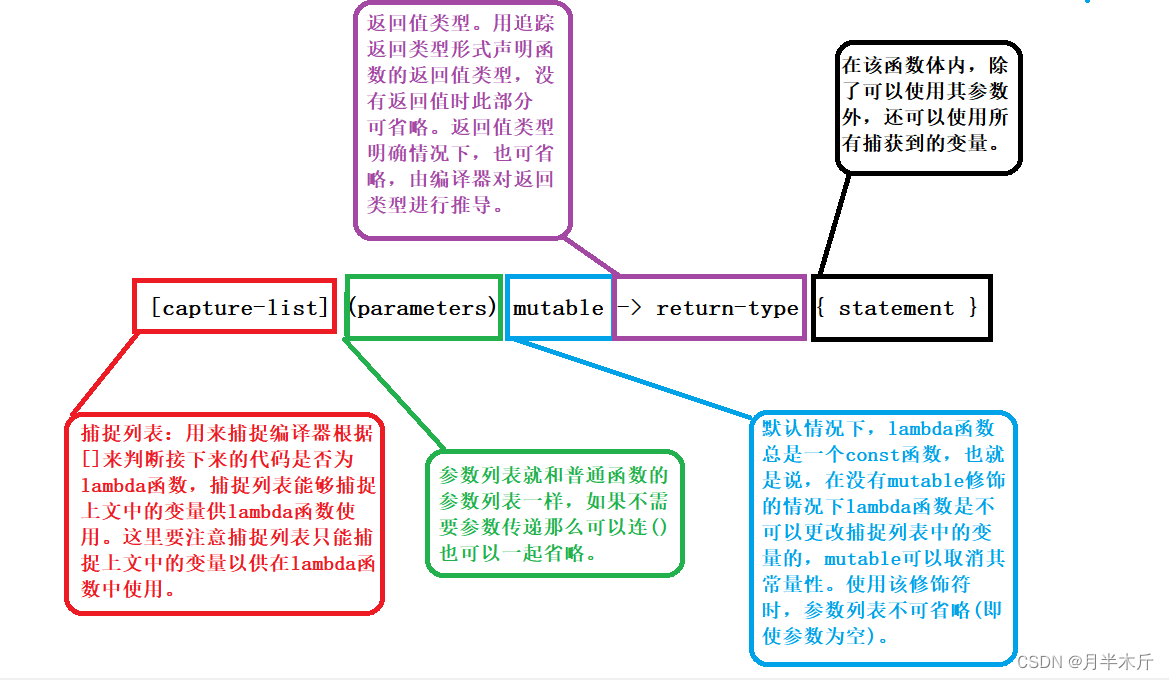
这五大部分有些是可以省略的如:mutable和参数列表和返回值都可以省略,剩下的捕捉列表和函数体都不可以省略但是可以为空。最简单的lambda表达式可以写为[]{}。
几种常见的lambda函数写法:
int main()
{
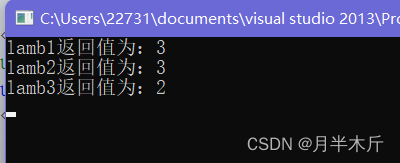
auto lamb1 = [](int a, int b){return a + b; };//省略了返回值的lambd函数
cout << "lamb1返回值为:" << lamb1(1, 2) << endl;
//auto lamb2 = []->int{return 1 + 2; };//这里这样省略参数列表但是不省略返回值的写法是不正确的会直接报错
auto lamb2 = []()->int{return 1 + 2; };//如果想要带上返回值类型那么就必须要加参数列表
cout << "lamb2返回值为:" << lamb2() << endl;
auto lamb3 = []{return 1 + 1; };//省略了参数列表和返回值的lambda函数
cout << "lamb3返回值为:" << lamb3() << endl;
auto lamb4 = []{};//无意义的lambda函数
return 0;
}运行结果:
注意全局作用域是不可以写lambda表达式的
2.2.1. 捕捉列表
捕获列表的使用注意:
int main()
{
int a = 1, b = 2;
auto lamb1 = [a, b]{return a + b; };//捕获列表中直接写参数也就是:[val],表示值传递方式捕捉变量var
cout << "lamb1返回值为:" << lamb1() << endl;
auto lamb2 = [=]{return a + b; };//捕获列表中写"="也就是:[=],表示值传递的方式捕获上文中的全部变量
//auto lamb2 = [=]{return c; };//这种写法是编译不同过的因为变量c在下文中即使用"="捕获全部变量但是也不可以捕获c
int c = 3;
//auto lamb2 = [=, a]{return a; };//注意捕捉列表是不可以重复捕捉同一个变量的,因为这里"="已经就代表捕捉全部变量
//所以就不可以在捕捉a变量了。
//auto lamb2 = [=]{a = 10; }//这里用"="和普通的值传递捕捉的变量在lambda函数中是不可以修改的
auto lamb3 = [=]()mutable{a = 10; return a; };//这里加上了mutable才可以修改变量的值,但是只是在lambda函数中作用域
//修改的值才有效,并不会对父作用域中的变量影响,而且在加mutable的时候
//和加返回值一样都需要带上参数列表才可以加mutable
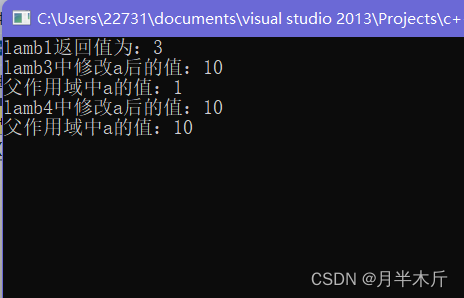
cout << "lamb3中修改a后的值:" << lamb3() << endl;
cout << "父作用域中a的值:" << a << endl;
auto lamb4 = [&a]{a = 10; return a; };//[&val]以引用的方式来捕捉上文中的变量,这里捕捉后在lambda函数中修改变量是会
//修改父作用域中变量的值的
cout << "lamb4中修改a后的值:" << lamb4() << endl;
cout << "父作用域中a的值:" << a << endl;
auto lamb5 = [&]{a = 11, b = 12; return a + b; };//[&]代表以引用的方式捕获上文中全部的变量
auto lamb6 = [&, a]{};//表示以值传递方式来捕获a,以引用的方式来捕获其他所有变量
auto lamb7 = [=, &a]{};//表示以引用的方式来捕获a,以值传递的方式来捕获其他所有变量
return 0;
}上面代码测试运行结果:
捕获列表传递this,[this]以值传递的方式来捕获当前对象的this,我们可以看到类对象的this指针只能用捕获列表来捕获,是不可以用参数列表来传递的。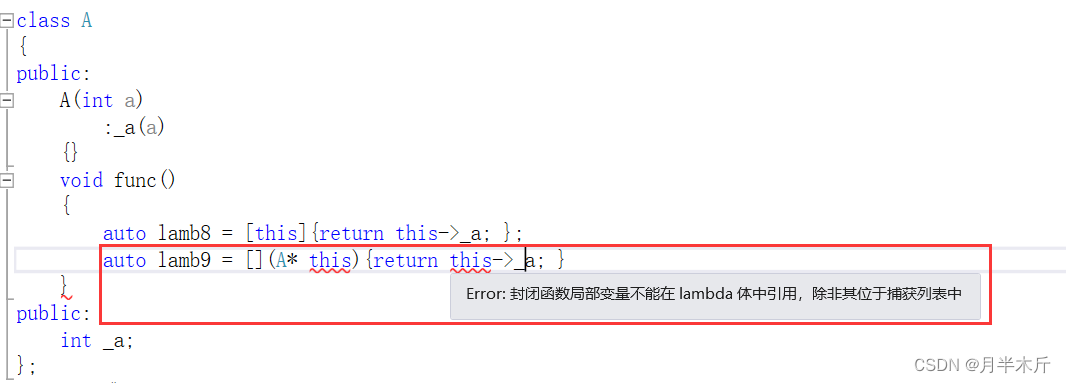
对于上面提到的父作用域的理解:
一般是指的是lambda表达式所在的函数作用域,这里lambda表达式所在父作用域可以访问到的所
所有变量都是可以被捕获列表捕获到的,例如说全局变量。

注意:lambda表达式之间不能相互赋值,即使看起来类型相同
void (*PF)();
int main()
{
auto f1 = []{cout << "hello world" << endl; };
auto f2 = []{cout << "hello world" << endl; };
//f1 = f2; // 编译失败--->提示找不到operator=()//从这里也足以可以看出lambda表达式其实最后就是被编译器解释为一个类了
// 允许使用一个lambda表达式拷贝构造一个新的副本
auto f3(f2);
f3();
// 可以将lambda表达式赋值给相同类型的函数指针
PF = f2;
PF();
return 0; }2.3 浅谈lambda表达式的原理:
这里lambda表达式的原理:这里就不具体来证明了直接给出结论:
其实lambda表达式最终就被编译器解释为一个类了,lambda表达式中的捕获列表当中捕获的变量最后被当为生成类中的成员变量。lambda表达式的函数体中的内容其实就是被重载为一个lambda表达式当中的一个operator=()函数了而且这个函数还是一个const类型的重载函数,所以这也就解释了为什么我们要想改变lambda表达式捕获的参数要加mutable的原因。用一句话总结就是我们在sort中传入的仿函数需要我们自己来实现,而lambda表达式我们写好之后编译器帮我们生成一个类。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











