







目录
1.lz77算法原理
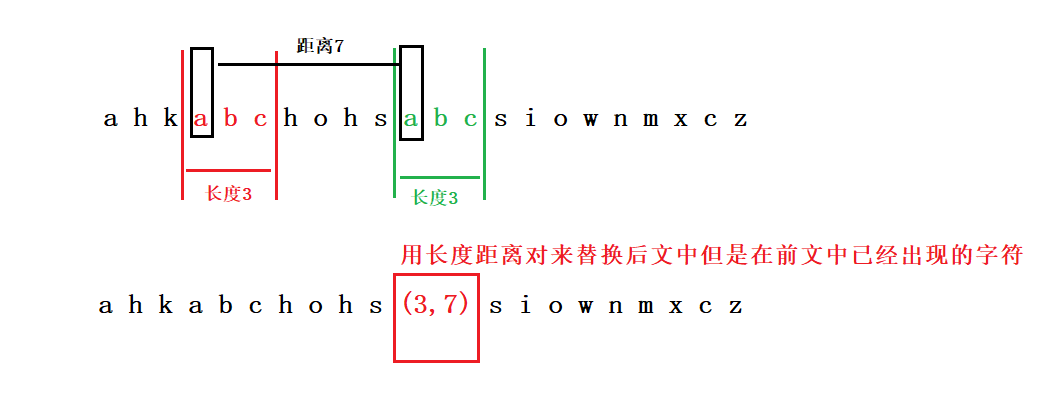
- lz77算法就是在文中找到重复的子串然后用长度距离对来替换重复的子串。(长度距离对:表示在前文中当前字符串在前文中出现,长度表示当前长度的字符串在前文中出现的长度,距离表示两个字符串相距的距离。)以达到将文件中重复出现的字符串减少压缩个数。
2.lz77夺命问题
-
2.1.在前文中找到多少个字符才需要替换?
- 我们要替换重复出现的字符,那么不得不考虑一个问题就是当前字符串在前文中重复出现多少个字符才要将其替换为长度距离对。要明白这个问题我们就首先要知道一个问题,那么就是长度距离对中的长度用多少个字符来表示,距离用多少个字符来表示。
- 长度:长度我们采用一个字符来表示,这是因为一般重复出现的字符长度都是少于255的。因为超过255长度的词语或者重复语句是很少出现的。这里如果用多个字节来表示长度,那么多数的长度短的字符串就对长度这几个字节利用不到位。重复语句超过长度范围那么我们就用两个或多个距离对来表示。这里我们在实际中长度表示范围是从3~258的。这里当解压缩读取的时候只需要将读取到的重复长度+3就可以得到最终的匹配长度。在压缩的时候可以将找到的匹配长度-3。这里长度最小匹配长度是3和下面的哈希地址计算有关,在计算的时候要用三个字符中的15个bite位参与。
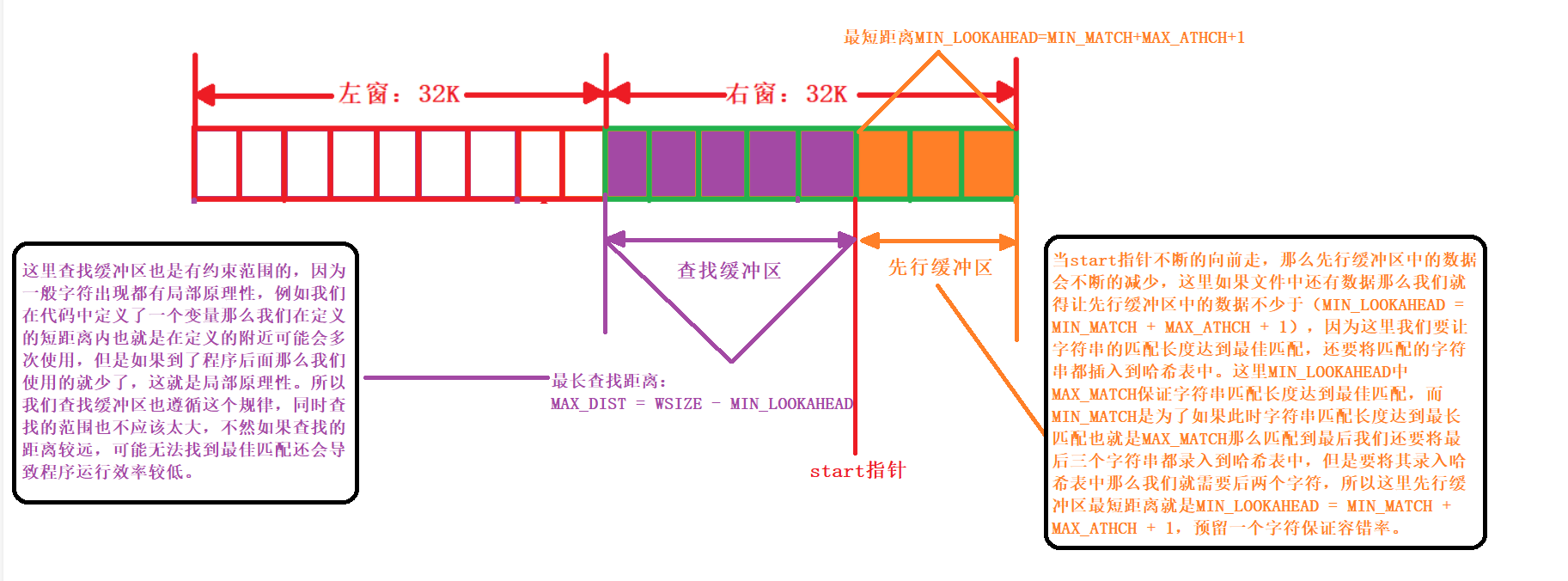
- 距离:距离我们采用两个字节来表示,lz77算法中读取信息涉及到一个窗口的概念。lz77在读取文件中的数据先将数据读到一个空间中,也就是我们的窗口中。(由窗口大小和哈希地址决定)
- 窗口:
-
1.查找缓冲区和前向缓冲区
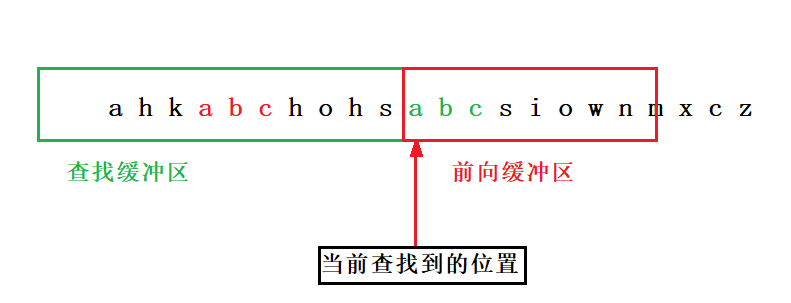
- 前向缓冲区:查找指针指向的位置就是前向缓冲区的开始,随着指针向后移动,我们找当前指针指向的字符以及指针后面的字符在查找缓冲区中出现的最大长度。
- 查找缓冲区:查找缓冲区就是我们已经查找过的区域,我们从查找缓冲区的开始来查找当前字符的匹配。(这里查找缓冲区大小为32K)
-
2.左窗口和右窗口
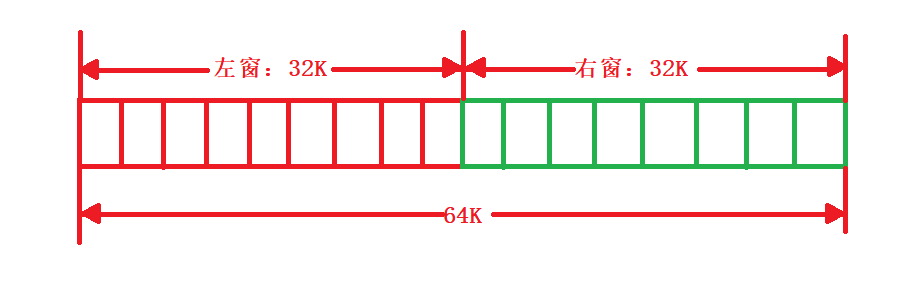
- 这里的左窗口和右窗口和上面的查找缓冲区和前向缓冲区并没有关系,这里的左右窗口是用来存放是数据的。也就是从文件中读取到的数据会存储到这里的左右窗口当中,然后在左右窗口中操作,当前向缓冲区中数据过少时就会将前向缓冲区中和后向查找缓冲区移到左窗,然后将新读取的数据放到右窗内。这里设置左右窗口是为了读取大文件而设计。
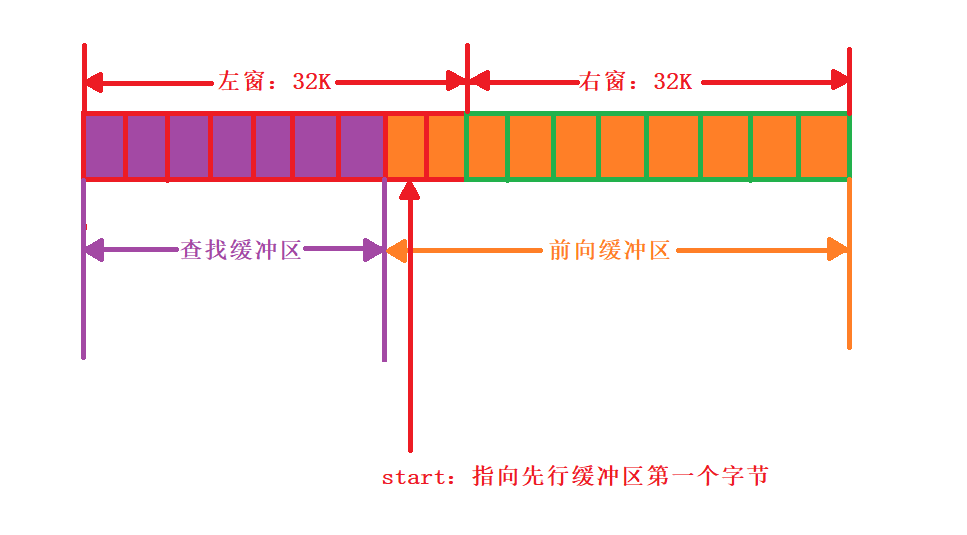
- 前向缓冲区不断的减小查找缓冲区不断的增大。

- 那么这里我们知道了左右窗口的总大小那么两个重复出现的字符串的最远距离就是64K那么也就是两个字节可以表示的范围,所以上面我们的长度距离对中的距离用两个字节来表示。
-
2.2如何快速查找重复出现的字符?
- 上面我们知道了当字符重复多少次才进行替换,那么问题是如何快速查找重复的字符,首先我们想到的就是用暴力查找直接在前文中查找重复出现的字符串,这样的方法一定是可行的,但是lz77算法怎么可能使用这么没有效率的算法呢?这里lz77在查找重复出现的字符串时采用的是哈希的思想。
- 哈希表:这里的哈希表是由两个数组组成的,head维护的数组空间用来存放当前要插入的元素。prev用来解决哈希冲突。
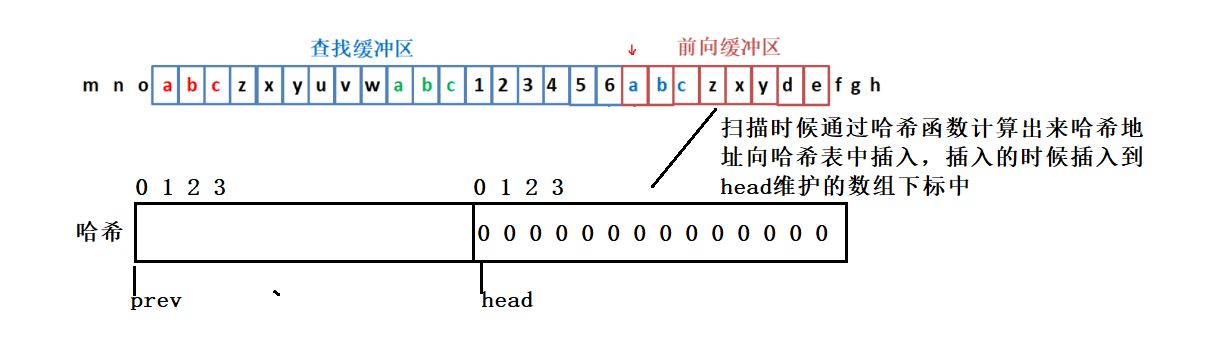
- 这里在缓冲区中扫描的时候我们一次性向哈希中存入三个字符。下面我们来举个例子来具体说明哈希的插入过程。
- 1.当扫描到第一个abc时:
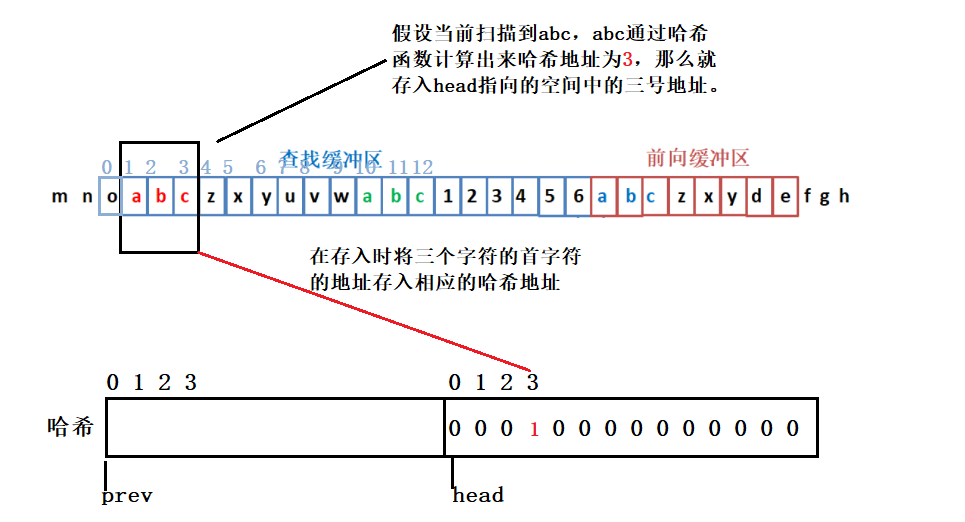
- 2.当扫描到第二个abc时:
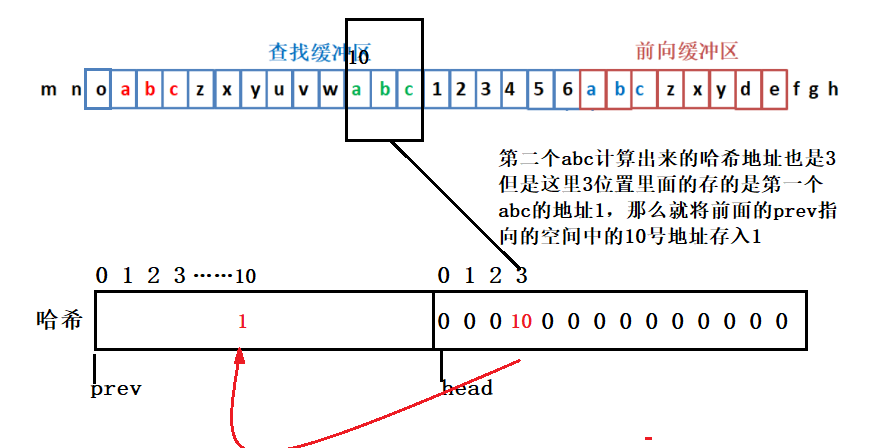
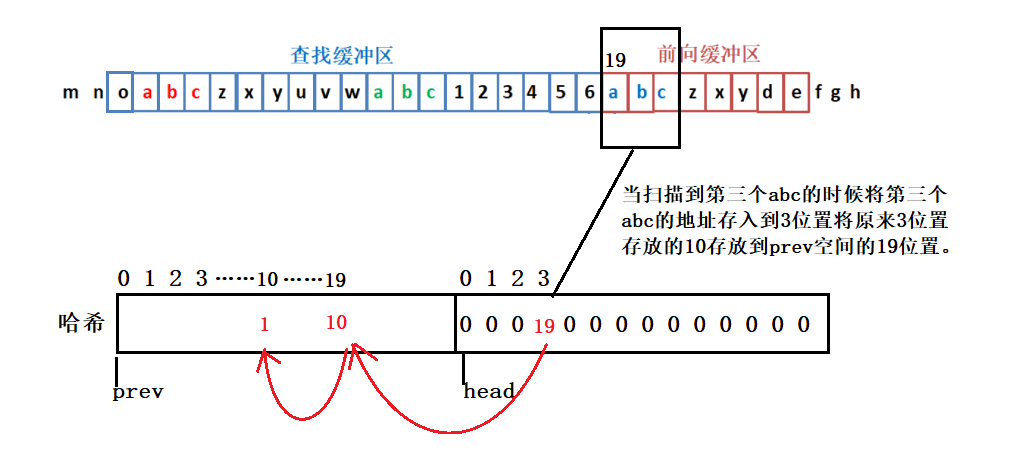
- 3.当扫描到第三个abc时:
- 大致的知道了哈希的存储过程,那么这里如何通过哈希表来查找最长重复出现的字符呢?
- 用上面的扫描abc的例子我们来说明:当第一次扫描到abc时,在3位置在哈希中存放的是0,所以在abc之前没有出现过abc,那么也就无法将第一个abc替换为长度距离对。当扫描到第二个abc的时候在哈希表中存放的是1,那么将当前3号空间中存放的1存放到prev空间中的10号位置,此时查看prev中的10位置存放的字符是否是0,这里10位置存放的1那么我们就匹配当前abc字符串后面的字符和1位置abc后面的字符,记录最长匹配长度。然后再查找prev1号位置存放地址是多少发现是0那么此次匹配结束。我们可以将当前abc字符替换为长度距离对。(这里存储在相同位置的字符串也不一定是同一个字符串,所以这里我们查找的时候需要判断,判断前一个字符串是否是与当前字符串相匹配。)
-
2.3 哈希函数如何实现?
- 我们这里为了使哈希冲突尽可能的少,那么应当使每个字符都参与到哈希地址的计算当中,也就是2^24个哈希地址,而哈希表中用来存储地址的位置占两个字节,那么需要的哈希表大小就要32M。维护这么大的哈希表无疑会让程序的运行效率降低。而且对于当时设计lz77的年代来说32M是一个很大的开销,所以这里哈希函数计算哈希哈希地址的时候让让三个字节的15个比特位来参与哈希地址的计算。那么也就是2^15个地址也就是32K。

-
2.4 如何区分是原字符还是我们替换的长度距离对呢?
- 在具体的lz77的实现中压缩文件中保存的压缩信息在长度距离对两边并其实是并没有括号的,那么我们怎么来区分是原字符还是长度距离对呢?
- 这里其实使用比特位来标记当前字符到底是压缩字符还是长度距离对。

- 为什么
3.LZ77模拟实现
-
3.1 哈希的模拟实现
-
<common.h>文件 #pragma once #include<iostream> #include<string> //用来重命名要在工程中用到的类型和定义常量 using std::cout; using std::endl; using std::cin; using std::string; typedef unsigned char uch; typedef unsigned short ush; typedef unsigned long long ull; //加上static防止多个文件同时包含而导致变量重复定义 static const int MAX_ATHCH = 258;//最大匹配长度 static const int MIN_MATCH = 3;//最小匹配长度 static const ush WSIZE = 32 * 1024;//窗口大小 static const ush MIN_LOOKAHEAD = MIN_MATCH + MAX_ATHCH + 1;//先行缓冲区至少要预留长度 static const ush MAX_DIST = WSIZE - MIN_LOOKAHEAD;//查找缓冲区最大距离:向左侧查找的最远距离。<HashTable.h>文件 //用来声明哈希 #include "common.h" //哈希表:底层维护的两个空间一个是存储当前字符下标的head指向的空间,另一个是存储哈希冲突的空间 //prev指向的空间。 class HashTable { public: HashTable(); ~HashTable(); //插入: void InsertString(ush& hashAddr, uch ch, ush pos, ush& macthHead); //获取前一个匹配串 ush GetPrevMatch(ush &MathcHead); //更新哈希表: void updatahash(); private: //哈希函数: void HashFunc(ush& hashAddr, uch ch); ush H_SHIFT(); ush* _prev; ush* _head; // 哈希桶的个数为2^15=32*1024:就是head或者prev空间的大小 const ush HASH_BITS = 15; // 哈希表的大小=32K const ush HASH_SIZE = (1 << HASH_BITS); // 哈希掩码:主要作用是将右窗数据往左窗搬移时,用来更新哈希表中数据 //当文件超过32k才会用到 const ush HASH_MASK = HASH_SIZE - 1; };<HushTable.cpp>文件 //实现哈希 #include "HashTable.h" //构造函数 //哈希表:底层维护的两个空间一个是存储当前字符下标的head指向的空间,另一个是存储哈希冲突的空间 //prev指向的空间。 HashTable::HashTable() :_prev(new ush[2 * WSIZE]) ,_head(_prev+WSIZE) { memset(_prev, 0,sizeof(ush)* 2 * WSIZE); } //析构函数 HashTable::~HashTable() { delete[] _prev; _prev = _head = nullptr; } // hashAddr: 上一个字符串计算出的哈希地址 // ch:当前字符 // 本次的哈希地址是在前一次哈希地址基础上,再结合当前字符ch计算出来的 // HASH_MASK为WSIZE-1,&上掩码主要是为了防止哈希地址越界 void HashTable::HashFunc(ush& hashAddr, uch ch) { hashAddr = (((hashAddr) << H_SHIFT()) ^ (ch)) & HASH_MASK; } ush HashTable::H_SHIFT() { return (HASH_BITS + MIN_MATCH - 1) / MIN_MATCH; } //插入: // hashAddr:上一次哈希地址 //ch:当前要插入的三个字符的第三个字符,因为我们将上一个哈希地址传入,那么上一个哈希地址的计算是通过当前三个 //字符的前两个字符和上一个三个字符的第一个字符计算得出,那么这里我们只需要将当前的三个字符的最后一个字符传入 //然后计算出当前三个字符的哈希地址即可。//那假如要插入的字符串是第一个字符串那么第一个哈希地址从哪里来????? // pos:当前三个字符的首字符的地址。 //matchHead:如果匹配,保存上一个在存储在当前哈希地址的三个元素的首地址。例如当前三号位置保存的是19当前要插入3号位置的 //三个字符串首地址是24那么macthhead保存的就是19。//这里为啥要保存???????????因为这里要在后面文件压缩的时候 //获取macthHead通过判断macthHead是否为0判断当前字符串是否有匹配串。 void HashTable::InsertString(ush& hashAddr, uch ch, ush pos, ush& macthHead) { //1.计算当前要插入的三个字符串的哈希地址: HashFunc(hashAddr, ch); //2.将hashaddr位置存储的前文中的匹配字符串的位置搬移到prev的pos的位置 _prev[pos & HASH_MASK] = _head[hashAddr]; //3.保存当前将前文中找到的最近一个匹配串通过macthhead带出去 macthHead = _head[hashAddr];///这里取hashaddr中的macthhead的时候要不要给macthead与上掩码????????????这里其实不用与因为我们在获取上一个match的时候就对macthhead与掩码处理过。 //4.将当前哈希地址存入当前字符串的首地址 _head[hashAddr] = pos; } ush HashTable::GetPrevMatch(ush &MathcHead) { MathcHead = _prev[MathcHead & HASH_MASK]; return MathcHead; } //将数据搬移之后我们需要将哈希表更新:因为右窗的数据都搬移到了左窗那么此时哈希表中存放的地址都改变了 //所以我们需要将哈希表中的每个地址都减去WSIZE,对于哈希表中小于WSIZE的数据就相当于被覆盖了属于无效地址 //那么我们就将其置为0 void HashTable::updatahash() { //更新head for (ush i = 0; i < HASH_SIZE; i++) { if (_head[i] < WSIZE) { _head[i] = 0; } else { _head[i] -= WSIZE; } } //更新prev for (ush i = 0; i < HASH_SIZE; i++) { if (_prev[i] < WSIZE) { _prev[i] = 0; } else { _prev[i] -= WSIZE; } } } -
3.2 LZ77的模拟实现
<LZ77.h>文件 //用来声明LZ77 #pragma once #include "HashTable.h" #include "common.h" class LZ77 { public: LZ77(); ~LZ77(); void CompressFile(const string& filename); void UNCompressFile(const string& filename); string Getfilename(const string& filename); string Getfilepostfix(const string& file_name); ush maxlenth(ush start, ush match_head, ush& matchdis); void WriteFlaginfo(FILE* fp, ush match_head, uch& bitinfo, uch& bitcount); void Filldata(ush &start, FILE* fin, size_t &looksize); private: uch* _pWin;//用来读取文件的窗口大小 HashTable _ht; };<LZ77.cpp>文件 //用来实现LZ77 #define _CRT_SECURE_NO_WARNINGS #include "LZ77.h" LZ77::LZ77() :_pWin(new uch[2*WSIZE]) ,_ht() {} LZ77::~LZ77() { if (_pWin) { delete[] _pWin; } } //压缩文件 void LZ77::CompressFile(const string& filename) { //首先要打开一个文件: FILE* fin = fopen(filename.c_str(), "rb"); if (fin == nullptr) { cout << "待压缩文件打开失败" << endl; return; } //当文件大小为3个字节的时候那么就没有必要对文件进行压缩了 //获取文件大小: fseek(fin, 0, SEEK_END); ull filesize = ftell(fin);//对于二进制文件返回从开始到当前文件流指针的字节数对于文本流,数值可能没有意义,但仍然可以用于在以后使用fseek将位置恢复到相同的位置(如果使用ungetc放回的字符仍在等待读取,则行为未定义)。 fseek(fin, 0, SEEK_SET); //如果文件大小小于等于MIN_MATCH则不进行压缩 if (filesize <= MIN_MATCH) { cout << "文件大小小于等于3个字节,不进行压缩" << endl; fclose(fin); return; } //文件压缩: //1.首先打开文件: string compressfilename = Getfilename(filename); compressfilename += ".lz"; FILE* fout = fopen(compressfilename.c_str(),"wb"); //2.先读取一个窗口的数据: size_t looksize = fread(_pWin, 1, 2 * WSIZE, fin); //3.在处理窗口数据循环插入之前我们要先获取前两个bit位的编码也就是前两个哈希编码 ush hash_addr = 0; ush match_head = 0; for (int i = 0; i < MIN_MATCH-1; i++) { _ht.InsertString(hash_addr, _pWin[i], i, match_head); } //这里我们不将标志位文件和压缩文件放在一起,而是分开,将标志位放到另一个文件当中 compressfilename = Getfilename(filename); compressfilename += ".flag"; FILE* flag = fopen(compressfilename.c_str(), "wb"); //将文件后缀名称也写入到标志位文件: string filepostfix = Getfilepostfix(filename); fwrite(filepostfix.c_str(), 1, filepostfix.size(), flag); fputc('\n', flag); uch bitinfo = 0;//要写入标志位文件的比特位 uch bitcount = 0;//写入比特位计数计数够8位就向文件中写入一次 ush start = 0;//当前字符插入的地方 ush matchdis = 0;//最长匹配距离//防止越界 ush matchlenth = 0;//最长匹配长度 while (looksize)//这里looksize是窗口的数据个数,这里我们将窗口中的数据全部处理完成那么我们的压缩也就结束了。 { match_head = 0; matchlenth = 0; //1.首先将每个字符插入哈希表: _ht.InsertString(hash_addr, _pWin[start + 2], start, match_head); if (match_head) {//这里如果match_head不为0的话那么就代表在前面找到了匹配串: matchlenth = maxlenth(start,match_head,matchdis); } if (matchlenth < MIN_MATCH) {//没有找到最长匹配:那么此时就将字符原封不动的写入到压缩文件 fputc(_pWin[start], fout); WriteFlaginfo(flag, 0, bitinfo, bitcount); start++; looksize--; } else {//找到了最长匹配:那么此时就将字符替换为长度距离对写入到压缩文件中 matchlenth -= 3;//因为这里matchlenth要表示3-258范围的匹配字节 fputc(matchlenth, fout);//长度写入 //fwrite(&matchlenth, 1, sizeof(matchlenth), fout); fwrite(&matchdis, sizeof(matchdis), 1, fout);//距离写入 WriteFlaginfo(flag, 1, bitinfo, bitcount);//将标志位写入 matchlenth += 3; looksize -= matchlenth; matchlenth--;//因为当前的字符已经插入到了哈希表中后面只需要将匹配的字符全部插入到哈希表中即可 start++; while (matchlenth--) {//将匹配区间内的元素都插入哈希表中因为匹配区间内的元素有可能是后文中的匹配串 _ht.InsertString(hash_addr, _pWin[start + 2], start, match_head); start++; } } //处理大文件:在处理大文件的时候当先行缓冲区中的数据少于最佳匹配元素个数的时候那么我们就要进行数据填充 if (start >= WSIZE + MAX_DIST) { Filldata(start,fin,looksize); } } if (bitcount > 0)//将最后一位没有写入到标志位文件当中的bit位信息写入 { bitinfo <<= (8 - bitcount); fputc(bitinfo, flag); } //将文件大小信息写入到文件的最后: fwrite(&filesize, 1, sizeof(filesize), flag); fclose(fin); fclose(fout); fclose(flag); } //数据填充: void LZ77::Filldata(ush &start, FILE* fin, size_t &looksize) { //1.将右窗中的数据都搬移到左窗 start -= WSIZE; memcpy(_pWin, _pWin + WSIZE, WSIZE); //2.那么向右窗中写入数据 if (!feof(fin))//如果文件走到末尾那么feof返回一个非0值 { looksize += fread(_pWin + WSIZE, 1, WSIZE, fin); } //3.更新哈希表: _ht.updatahash(); } //写标志位函数: void LZ77::WriteFlaginfo(FILE* fp, ush match_head, uch& bitinfo, uch& bitcount) { bitinfo <<= 1; if (match_head) { bitinfo |= 1; } bitcount++; if (bitcount == 8) { fputc(bitinfo,fp); bitcount = 0; bitinfo = 0; } } //求前后文最长匹配长度: //在这个函数中我们要求出从match_head开始和从start开始两者最长匹配长度和距离: ush LZ77::maxlenth(ush start,ush match_head,ush& matchdis) { //这里因为大文件加入了哈希掩码可能会导致哈希表成链状,所以这里我们要控制匹配次数最多匹配255次就够了 ush MaxMachthcount = 255; //这里因为匹配距离也就是查询距离还不可以超过MAX_DIST所以这里我们也要有所限制: ush limit = start >= MAX_DIST ? start - MAX_DIST : 0; ush max_lenth = 0;//这里最长匹配如果到了255之后如果再++那么就会加到0,1,2所以用ush来定义max_lenth do { ush pstart = start; ush pend = start + MAX_ATHCH;//最大匹配长度//这里因为最大匹配长度为255所以有可能会超出长度范围所以用ush来表示 ush curmatch_head = match_head;//当前的match_head uch cur_lenth = 0;//当前的匹配长度 while (pstart < pend &&_pWin[pstart] == _pWin[curmatch_head]) { pstart++; curmatch_head++; cur_lenth++; } if (cur_lenth>max_lenth) { matchdis = start - match_head; max_lenth = cur_lenth; } } while ((_ht.GetPrevMatch(match_head)>limit)&&(MaxMachthcount--)); //这里如果最大匹配距离大于MAX_DIST那么我们就舍弃本次匹配: if (matchdis > MAX_DIST) { max_lenth = 0; } return max_lenth; } void LZ77::UNCompressFile(const string& filename) { //打开待解压缩压缩文件: FILE* fin1 = fopen(filename.c_str(), "rb"); //打开标志位文件: string file_name = Getfilename(filename);//获取当前文件的文件名 file_name += ".flag"; FILE* fin2 = fopen(file_name.c_str(), "rb");//这里将标志位文件写死了??????????? //读取要还原的文件后缀: string filenamepostfix; while (true) { char ch = fgetc(fin2); if (ch == '\n') { break; } filenamepostfix.push_back(ch); } //打开要还原的文件: string recoverfilename = Getfilename(filename) + "lzun." + filenamepostfix; FILE* fout1 = fopen(recoverfilename.c_str(), "wb"); //FILE* fout1 = fopen("222.txt", "wb"); if (fout1==nullptr) { perror("fopen"); cout << "解压缩文件打开失败" << endl; return; } //用另一个文件指针打开压缩文件当我们要用长度距离对来进行还原压缩文件的时候那么我们就可以用当前文件指针偏移相应的距离来读取 FILE* fout2 = fopen(recoverfilename.c_str(), "rb"); //FILE* fout2 = fopen("222.txt", "rb"); if (fout2 == nullptr) { perror("fopen"); cout << "解压缩文件打开失败" << endl; return; } //向文件中写:读一个标志位写一个 //1.首先读取文件的大小:因为在文件的最后八个字节所以我们将文件指针移动到倒数第八个字节处 fseek(fin2, -8, SEEK_END); ull filesize = 0; fread(&filesize, 1, sizeof(filesize), fin2); fseek(fin2, 0, SEEK_SET); while (true) { char ch = fgetc(fin2); if (ch == '\n') { break; } } uch bit=0; uch bitcount=0; while (filesize) { if (bitcount == 0) {//当bitcount为0时候代表当前字节的八个bit标志位都读取完成,那么再从文件中读取一个字节: bit = fgetc(fin2); bitcount = 8; } if (bit & 0x80) { fflush(fout1);//在用匹配还原前先将文件缓冲区中的数据刷新出去。 //如果当前位置为1那么就利用长度距离对来读取数据: ush matchlenth = fgetc(fin1) + 3;//长度 filesize -= matchlenth; ush matchdis = 0;//距离,读取两个字节 fread(&matchdis, sizeof(matchdis), 1, fin1); fseek(fout2, 0 - matchdis, SEEK_END);//将文件指针偏移到匹配字符串的位置 while (matchlenth--) {//这里我们在前文中读取一个匹配字符就向后文中写一个匹配字符 char ch=fgetc(fout2);//从解压缩文件中读取 fputc(ch, fout1); fflush(fout1);//这里注意要及时刷新缓冲区,因为如果前文匹配字符串与后文匹配字符串又重叠那么就会造成 //还原不完整例如abc abc abc这里当前文匹配读取到第二个abc的时候后文写入的abc还在文件缓冲区中那么后文还原 //的字符就不完整。 } } else {//将压缩文件中的字符原封不动的写入到还原文件当中 char ch=fgetc(fin1); fputc(ch,fout1); filesize--; } bit <<= 1; bitcount--; } fclose(fin1); fclose(fin2); fclose(fout1); fclose(fout2); } //获取文件名 string LZ77::Getfilename(const string& filename) { return filename.substr(0, filename.find('.')); } //获取文件后缀名 string LZ77::Getfilepostfix(const string& file_name) { return file_name.substr(file_name.find_first_of('.') + 1); }
4.模拟实现中的问题
-
4.1还原的时候不及时刷新文件缓冲区中的内容导致出错。
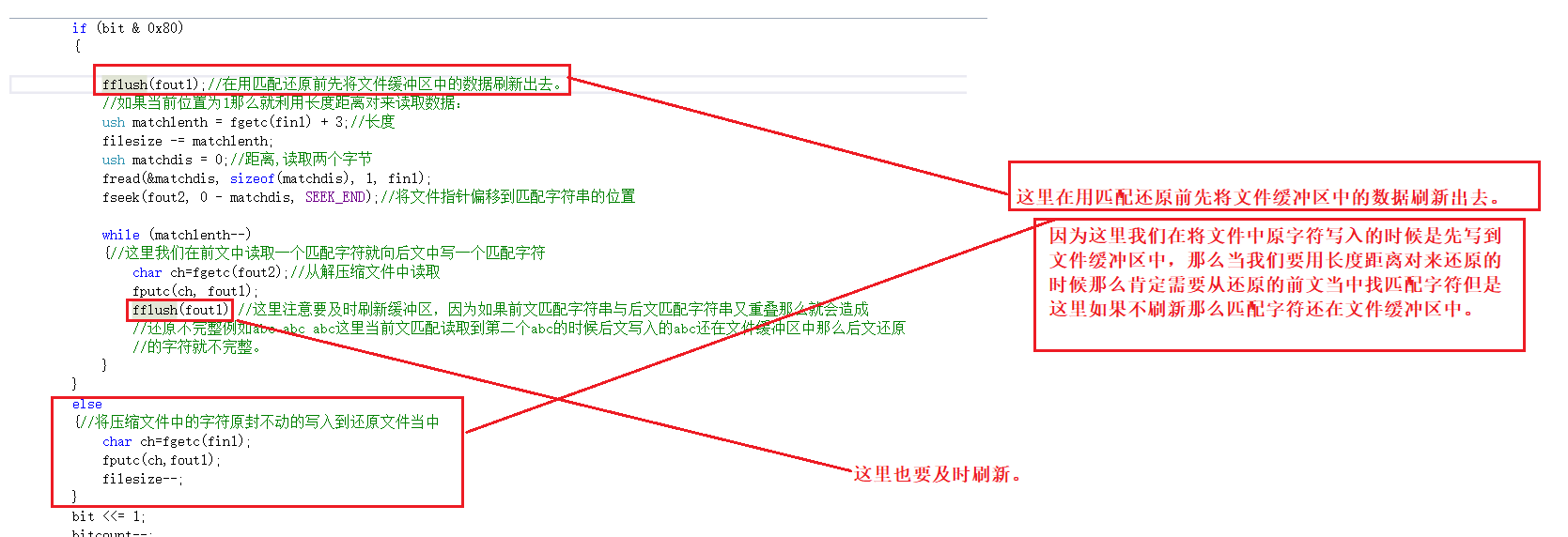
-
4.2处理大文件
- 处理方式:

-
4.3哈希函数处理右窗数据越界问题
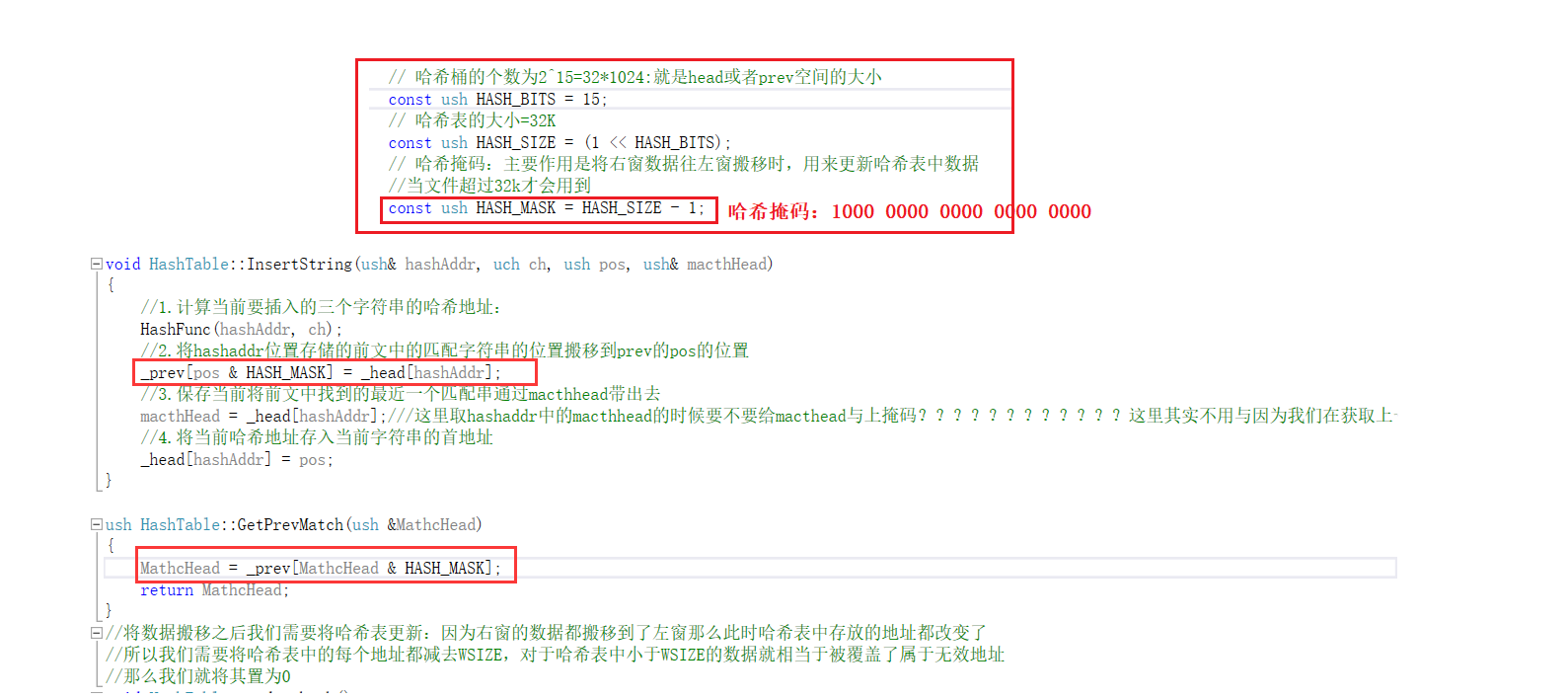
- 因为我们在构造哈希表的时候我们的哈希表中有两个指针head和prev。分别指向一块WSIZE大小的空间,那么当我们处理右窗的数据的时候,数据的下标都是大于WSIZE的那么我们在插入哈希表的的时候就会越界。

- 解决方式:这里会越界是因为,访问下标超过WSIZE,也就是超过WSIZE,那么采用哈希掩码来解决访问越界。其实就是和网络掩码一样,哈希掩码就是将1左移15位,那么除了最高位为1其余的比特位都为1,我们用哈希掩码和地址下标来进行&操作那么就可以将最高位去掉从而达到了解决了访问越界的问题。
-
4.4哈希掩码造成的问题
- 通过掩码计算出出来的地址可能会造成哈希表中数据覆盖,使链断开或者形成环状链。
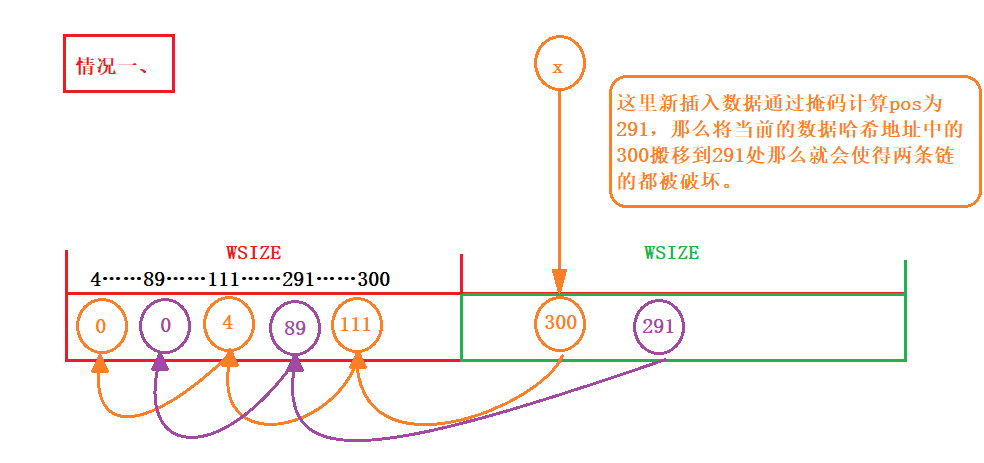
- 环状链:
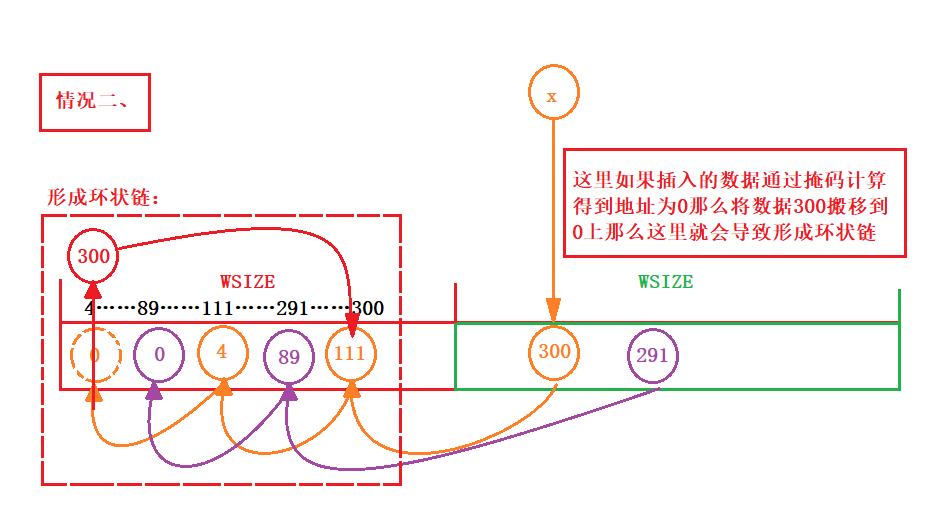
- 解决方式:
- 这是无法避免的!!!一个人有优点那么一定也有缺点。
5.LZ77文件压缩的测试
5.1首先我们先来压缩一个文本文件
- 当前这个文件是我对于程序的复制,所以会有许多的重复出现字符。
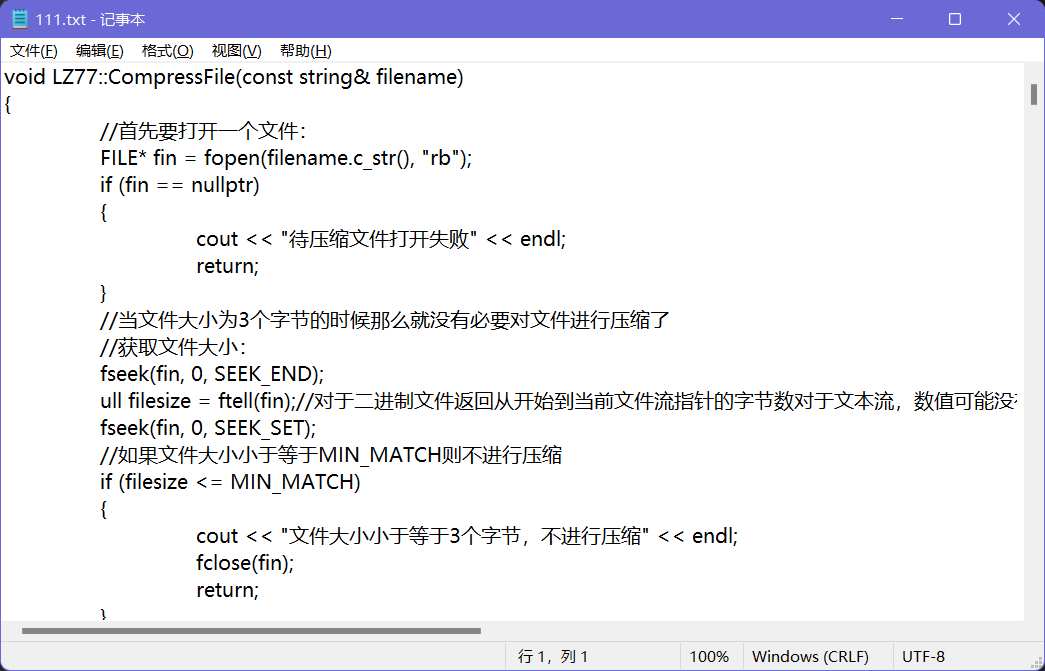
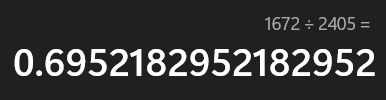
- 首先来看压缩率:
- 这是对于文本文件的压缩结果。

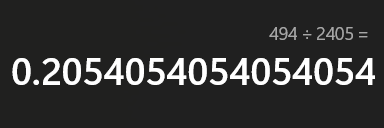
- 可以看到压缩率接近70%
- 同样的文件用Huffman压缩我们来看一下结果
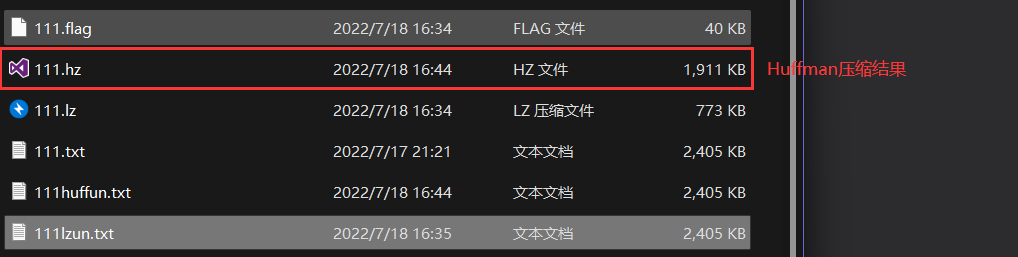
- 压缩率:可以看到压缩率才接近20%
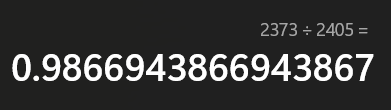
- 我们来看zip压缩

- 压缩率达到了惊人的98%确实NB。
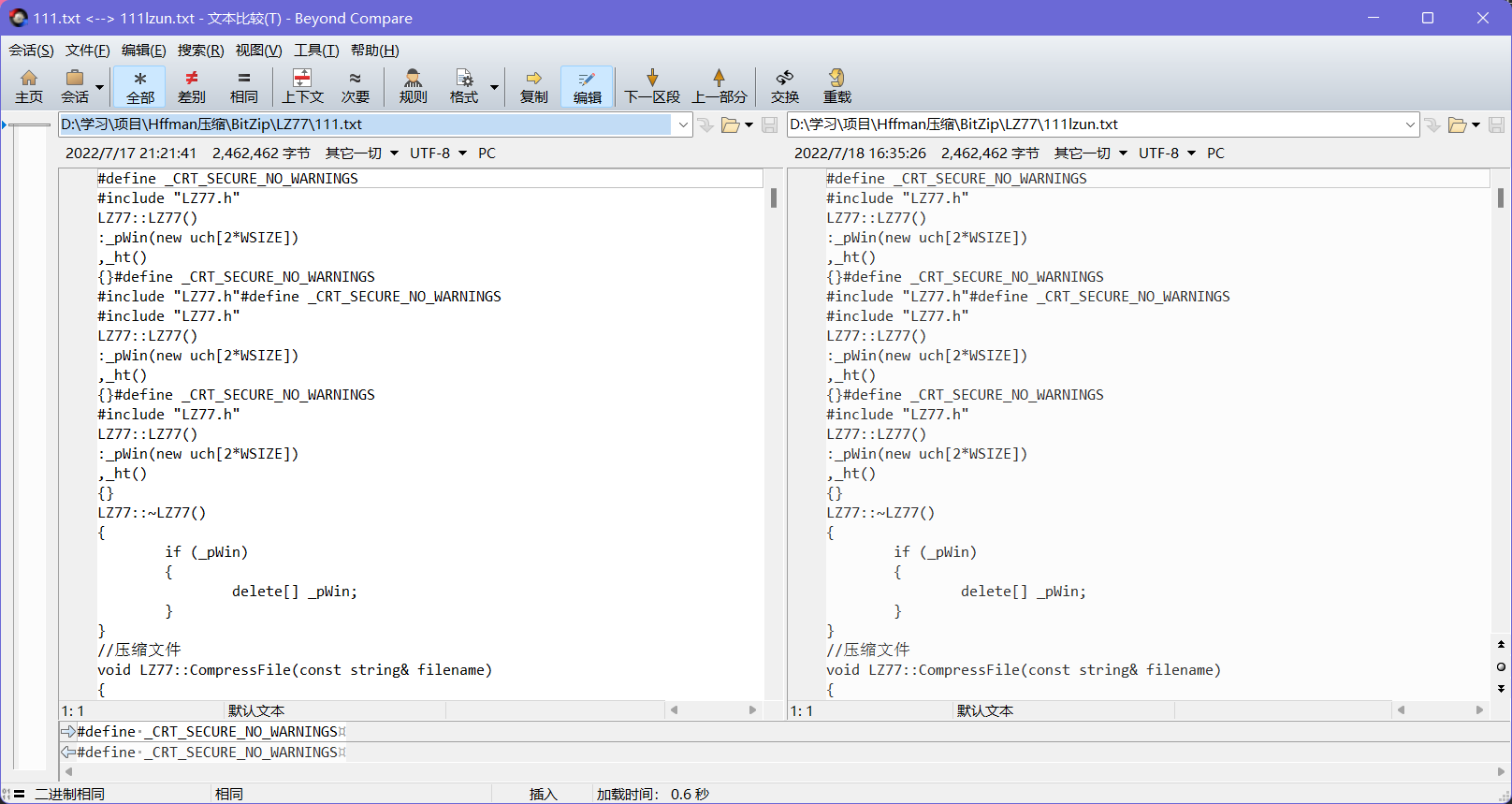
- 我们再来看文件的还原率:
- 我们用compare来比较可以看到完全相同
5.2压缩图片
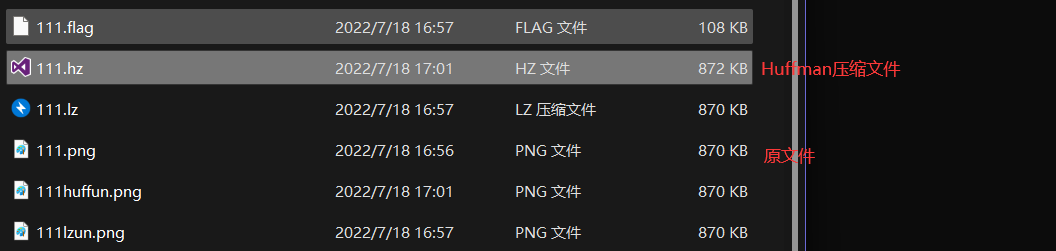
待压缩图片
我们来压缩:可以看到压缩结果是惨不忍睹。不仅没有变小反而还变大了。

在来看还原度:可以看到是100%还原
我们再来看Huffman压缩,可以看到也是压缩完之后文件变大了但是比LZ77要好一点。
我们再来看zip压缩可以看到zip压缩也是将文件变大了。

6.对于LZ77的总结
首先对于文件中有大量重复出现字符的文件具有理想的压缩效果,缺点保存的标志位信息几乎占文件大小的1/8,那么如果我们文件中出现的重复字符少的话,那么就会多出来许多没有实际用处的标志位信息。不仅不会使压缩文件减小而且还会使压缩文件增大。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











