




 本文详细介绍了HBase WAL的工作原理,包括客户端操作如何通过protobuf RPC发送到RegionServer,以及WAL在数据写入过程中的关键步骤,如加锁、写入MemStore和刷盘策略。重点展示了MultiRowMutationEndpoint在实现行事务中的作用。
本文详细介绍了HBase WAL的工作原理,包括客户端操作如何通过protobuf RPC发送到RegionServer,以及WAL在数据写入过程中的关键步骤,如加锁、写入MemStore和刷盘策略。重点展示了MultiRowMutationEndpoint在实现行事务中的作用。
2021SC@SDUSC
一、简述
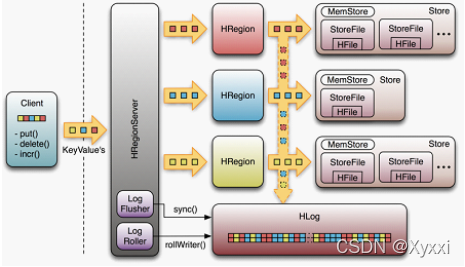
WAL(Write-Ahead-Log)是HBase的RegionServer在处理数据插入和删除的过程中用来记录操作内容的一种日志。大致过程如下图所示,首先客户端启动一个操作来修改数据,每一个修改都封装到KeyValue对象实例中,并通过RPC调用发送到含有匹配Region的HRegionServer。一旦KeyValue到达,它们就会被发送管理相应行的HRegion实例。数据被写到WAL,然后被放入到实际拥有记录的存储文件的MemStore中。同时还会检查MemStore是否满了,如果满了就会被刷写到磁盘中去。
二、实现
首先client端先把put/delete等api操作封装成List,然后使用protobuf协议使用rpc服务发送到对应的HRegionServer,HRegionServer调用execRegionServerService()方法解析发送过来的protobuf协议二进制包,通过serviceName找到相应的service并调用callMethod方法执行:
try {
ServerRpcController serviceController = new ServerRpcController();
CoprocessorServiceCall call = serviceRequest.getCall();
String serviceName = call.getServiceName();
com.google.protobuf.Service service = coprocessorServiceHandlers.get(serviceName);
if (service == null) {
throw new UnknownProtocolException(null, "No registered coprocessor executorService found for " +
serviceName);
}
com.google.protobuf.Descriptors.ServiceDescriptor serviceDesc =
service.getDescriptorForType();
CoprocessorServiceResponse execRegionServerService(
@SuppressWarnings("UnusedParameters") final RpcController controller,
final CoprocessorServiceRequest serviceRequest) throws ServiceException {
try {
ServerRpcController serviceController = new ServerRpcController();
CoprocessorServiceCall call = serviceRequest.getCall();
String serviceName = call.getServiceName();
com.google.protobuf.Service service = coprocessorServiceHandlers.get(serviceName);
if (service == null) {
throw new UnknownProtocolException(null, "No registered coprocessor executorService found for " +
serviceName);
}
com.google.protobuf.Descriptors.ServiceDescriptor serviceDesc =
service.getDescriptorForType();
String methodName = call.getMethodName();
com.google.protobuf.Descriptors.MethodDescriptor methodDesc =
serviceDesc.findMethodByName(methodName);
if (methodDesc == null) {
throw new UnknownProtocolException(service.getClass(), "Unknown method " + methodName +
" called on executorService " + serviceName);
}
com.google.protobuf.Message request =
CoprocessorRpcUtils.getRequest(service, methodDesc, call.getRequest());
final com.google.protobuf.Message.Builder responseBuilder =
service.getResponsePrototype(methodDesc).newBuilderForType();
service.callMethod(methodDesc, serviceController, request, message -> {
if (message != null) {
responseBuilder.mergeFrom(message);
}
put/delet等“写”操作会使用MultiRowMutationService这个service来作用,在service中将会调用mutateRows()方法去处理List,真正调用mutateRows()的是MultiRowMutationService的一个实现类MultiRowMutationEndpoint,MultiRowMutationEndpoint类实现了hbase的行事务。从MultiRowMutationEndpoint类文档可以看出其主要作用:
/**
* This class demonstrates how to implement atomic multi row transactions using
* {@link HRegion#mutateRowsWithLocks(Collection, Collection, long, long)}
* and Coprocessor endpoints.
*
* Defines a protocol to perform multi row transactions.
* See {@link MultiRowMutationEndpoint} for the implementation.
* <br>
mutateRows()方法会row所找到对应的Region,并调用其对应实例HRegion的mutateRowsWithLocks方法具体实现写入过程。
在HRegion类中mutateRowsWithLocks方法查看有没执行器(RowProcessor),如果没有则创建一个再调用processRowsWithLocks()方法。processRowsWithLocks方法是整个“写”操作最核心的方法:把写wal,刷wal以及写memstore流程都在这里流转。
/**
* Performs atomic multiple reads and writes on a given row.
*
* @param processor The object defines the reads and writes to a row.
* @param nonceGroup Optional nonce group of the operation (client Id)
* @param nonce Optional nonce of the operation (unique random id to ensure "more idempotence")
* @deprecated As of release 2.0.0, this will be removed in HBase 3.0.0. For customization, use
* Coprocessors instead.
*/
// TODO Should not be exposing with params nonceGroup, nonce. Change when doing the jira for
// Changing processRowsWithLocks and RowProcessor
@Deprecated
void processRowsWithLocks(RowProcessor<?,?> processor, long nonceGroup, long nonce)
throws IOException;
processRowWithLocks方法的关键几步:
// STEP 3. Region lock
lock(this.updatesLock.readLock(), acquiredRowLocks.isEmpty() ? 1 : acquiredRowLocks.size());
locked = true;
HRegion将会对Region加锁,加锁的方式是把所有写row相关的行锁都拿到的二阶段锁方式。
// STEP 7. Apply to memstore
long sequenceId = writeEntry.getWriteNumber();
for (Mutation m : mutations) {
// Handle any tag based cell features.
// TODO: Do we need to call rewriteCellTags down in applyToMemStore()? Why not before
// so tags go into WAL?
rewriteCellTags(m.getFamilyCellMap(), m);
for (CellScanner cellScanner = m.cellScanner(); cellScanner.advance();) {
Cell cell = cellScanner.current();
if (walEdit.isEmpty()) {
// If walEdit is empty, we put nothing in WAL. WAL stamps Cells with sequence id.
// If no WAL, need to stamp it here.
PrivateCellUtil.setSequenceId(cell, sequenceId);
}
applyToMemStore(getStore(cell), cell, memstoreAccounting);
}
}
List放入,但是这里并不是真正的放到了memstore,真正的执行会等sync()方法把日志或者说WALEdite真正刷入磁盘后,通过mvcc版本号异步通知再把数据写到memstore。
// STEP 8. call postBatchMutate hook
processor.postBatchMutate(this);
// STEP 9. Complete mvcc.
mvcc.completeAndWait(writeEntry);
writeEntry = null;
// STEP 10. Release region lock
if (locked) {
this.updatesLock.readLock().unlock();
locked = false;
}
// STEP 11. Release row lock(s)
releaseRowLocks(acquiredRowLocks);
if (rsServices != null && rsServices.getMetrics() != null) {
rsServices.getMetrics().updateWriteQueryMeter(this.htableDescriptor.
getTableName(), mutations.size());
}
}
success = true;
} finally {
// Call complete rather than completeAndWait because we probably had error if walKey != null
if (writeEntry != null) mvcc.complete(writeEntry);
if (locked) {
this.updatesLock.readLock().unlock();
}
// release locks if some were acquired but another timed out
releaseRowLocks(acquiredRowLocks);
在这里HRegion会把封装好的WALEdit使用FSHLog的append方法追加到日志文件,但是由于文件本身在内存中有缓存的原因,还需要调用sync刷入磁盘。这里只是把WALEdit数据放到一个LMAX Disrutpor RingBuffer中。这个RingBuffer是一个线程安全的消息队列,在wal中主要用于有效且安全的协调多个生产者一个消费者模型。其中多个生产者就是这个append方法,将会有很多client产生数据都放到这个消息队列中,但是只有一个消费者从这个队列中取数据并调用sync方法把数据从缓存刷到磁盘,这样能保证WAL日志并发写入时日志的全局唯一顺序。
在这步中会会调用syncOrDefer方法,除了metaRegion,syncOrDefer将根据client设置的持久化等级选择是否调用wal(FSHLog)的sync方法
private void sync(long txid, Durability durability) throws IOException {
if (this.getRegionInfo().isMetaRegion()) {
this.wal.sync(txid);
} else {
switch(durability) {
case USE_DEFAULT:
// do what table defaults to
if (shouldSyncWAL()) {
this.wal.sync(txid);
}
break;
case SKIP_WAL:
// nothing do to
break;
case ASYNC_WAL:
// nothing do to
break;
case SYNC_WAL:
this.wal.sync(txid, false);
break;
case FSYNC_WAL:
this.wal.sync(txid, true);
break;
default:
throw new RuntimeException("Unknown durability " + durability);
}
}
}
三、总结
利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









