






之前小新在进行数据预处理时,要先从维基百科上下载一些数据资源,在这里记录一下从维基百科下载的大致流程:
1、维基百科:是一个基于维基技术的多语言百科全书式的协作计划,是用多种语言编写而成的网络百科全书。维基百科由非营利组织维基媒体基金会负责营运,维基百科接受捐赠。特点是自由内容、自由编辑。它是全球网络上最大且最受大众欢迎的参考工具书,名列全球十大最受欢迎的网站。Wikipedia是一个混成词,取自网站核心技术“wiki”和英文中百科全书之意的“encyclopedia”。
2、数据集下载:
我需要的是英文的文章,所以用选的是articles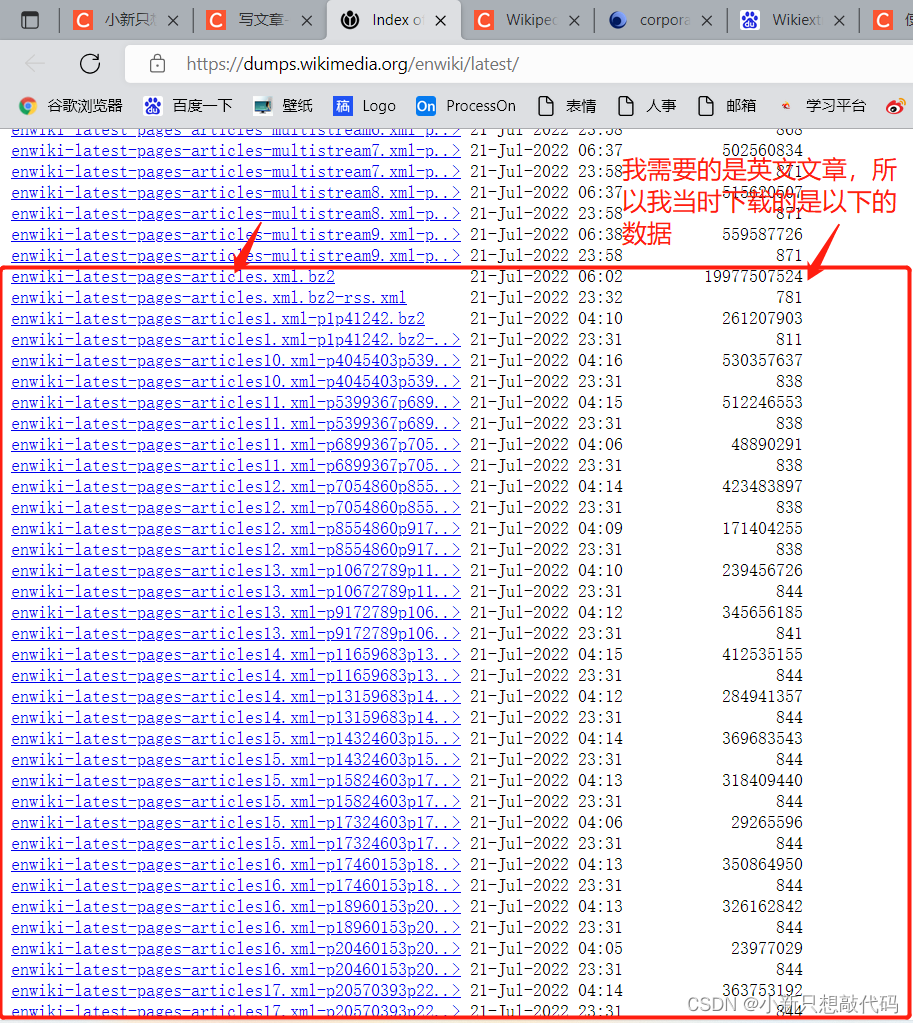
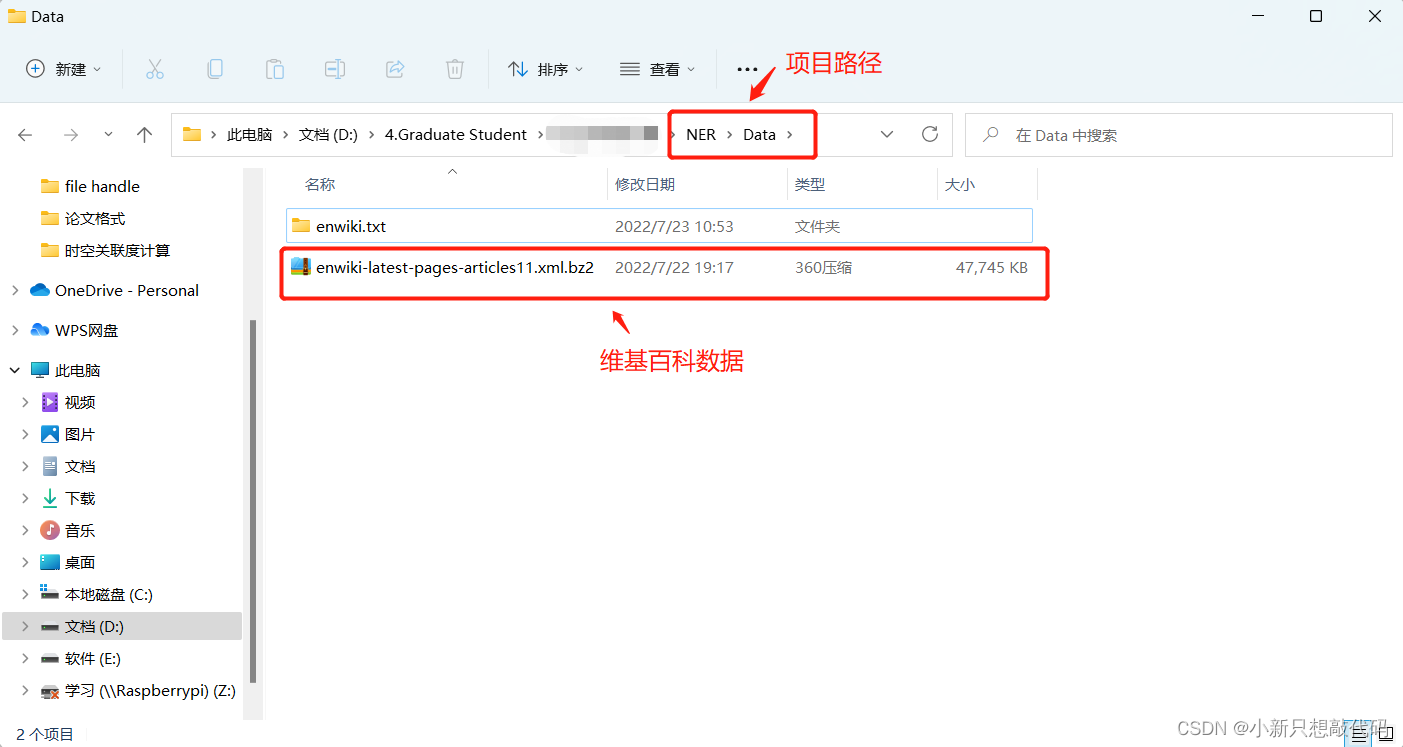
(1)下载完之后,得到的是一个.xml.bz2的文件(注意:下载完之后不要先解压,将其复制到你项目的Data文件夹下)
(2)使用Wikiextractor提取维基百科.xml.bz2的文本数据
(Wikiextractor 是一个提取维基百科语料的一个工具,在国内很受欢迎,它可以提取从维基下载下来的带.bz结尾语料的主要文章内容)
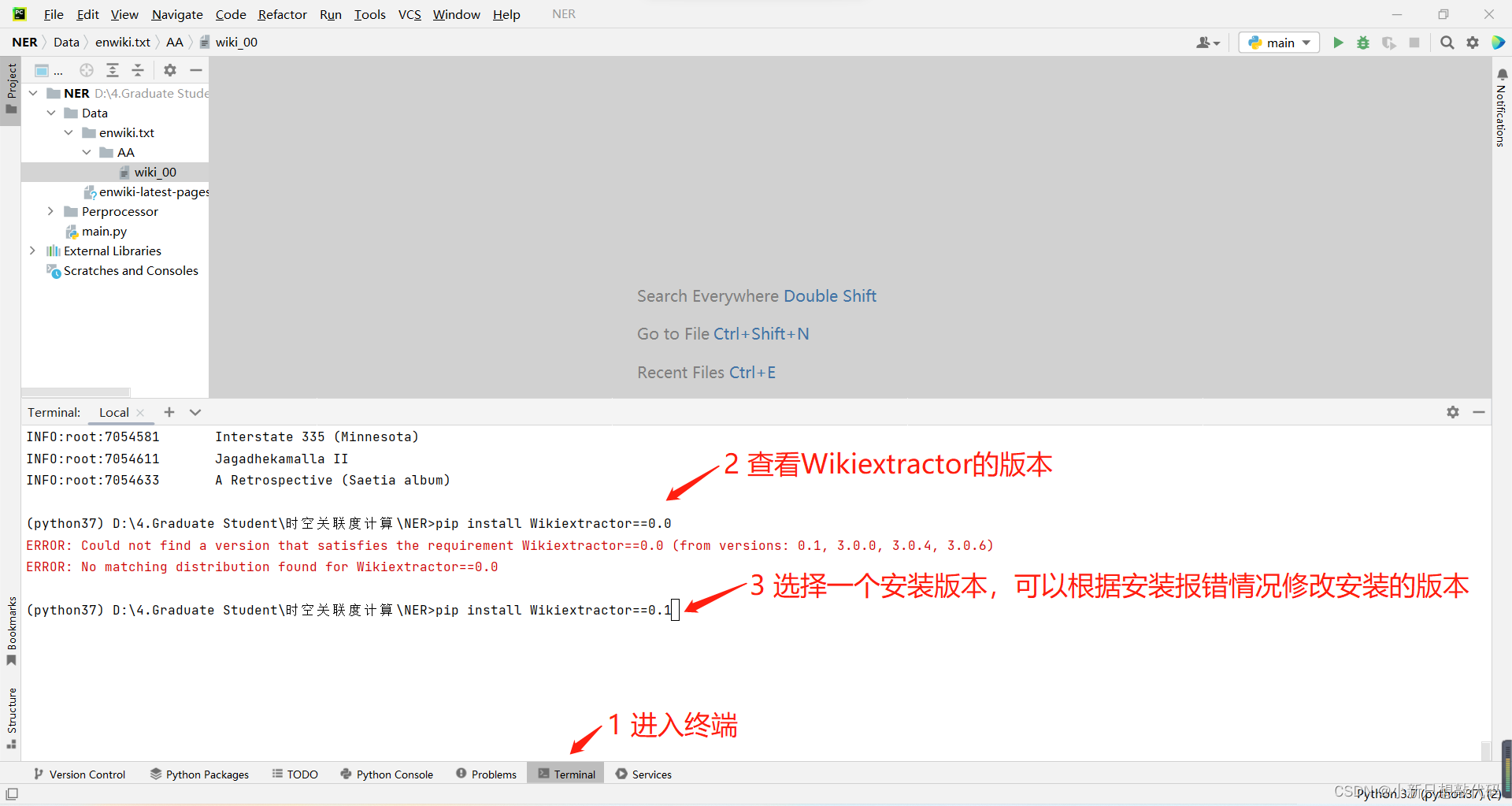
- 在你的项目中安装Wikiextractor:
pip install Wikiextractor
- 安装完后,查看是否安装成功:
pip list
- 安装成功后,就可以使用Wikiextractor对文本进行处理:
python -m wikiextractor.WikiExtractor -b 1024M -o 输出文件存放路径 源文件存放路径
注:
这里有些命令需要介绍一下:python -m (在python -m文章中有详细介绍)、-b 文件容量(例如:-b 1024M ,即当文件容量超过1024M时,在解析过程中,会自动新增文件,则解析完成后可能产生多个文件)、-o 输出文件路径
例如:我解析的代码如下
python -m wikiextractor.WikiExtractor -b 1024M -o Data/enwiki Data/enwiki-latest-pages-articles11.xml.bz2

3、数据处理(在这一部分对于数据集的处理,需要用到正则表达式,后续还会对数据处理进行更新修改)
-
解析之后的文本含有<>这样的标签,在我们后续的文本处理是不需要的,所以要先去除掉
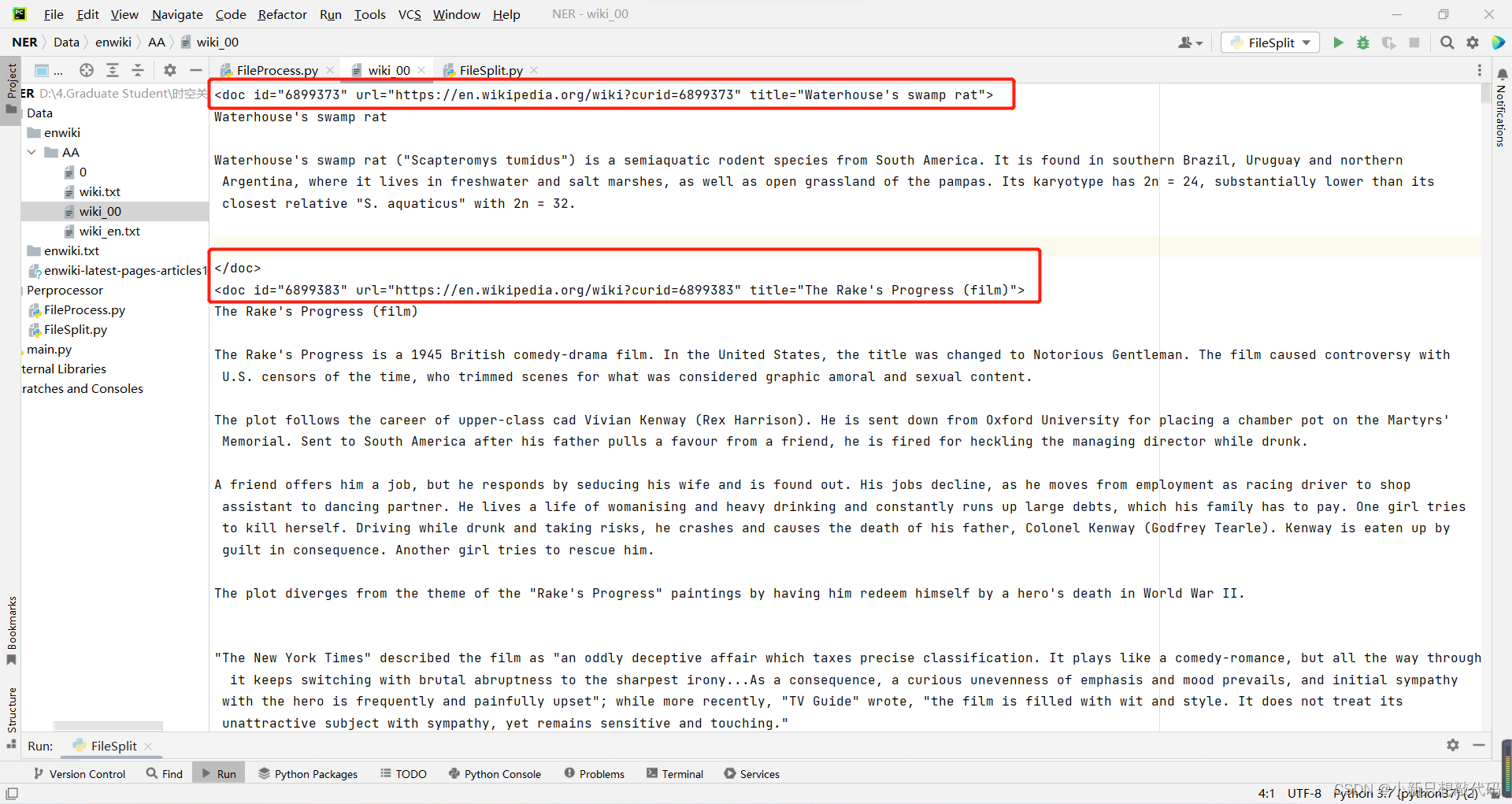
-
处理的代码以及文件的位置如下:
import re
import os
#文本处理
def fileprocess(infile,outfile):
out_afile = open(outfile,'w',encoding='utf-8')
with open(infile,'r',encoding='utf-8') as f:
articles = f.readlines() #读取文本中的所有行
articlesList = list()
a_nums = len(articles)
for idx in range(a_nums):
article = articles[idx] #依次读取每一行
if article == '\n':
del article #删除多余的空行
else:
article = article.strip() #删除每行首尾的空格或回车
if article.endswith('.') == False and article.endswith('>') == False: #判断字符串最后一个字符是不是以.结尾
article = article+'. '
articlesList.append(article)
outarticles = ' '.join(articlesList) #将列表中的字符串元素按照 空格 进行拼接
re_out = re.findall(r'<doc.*?>(.*?)</doc>',outarticles) #list类型 ,使用re.findall 标签中间不能有回车,不然无法识别
# for ido in range(len(re_out)):
# out_afile.write(re_out[ido])
out_afile.writelines(re_out) #使用writelines的效果与上面的循环效果一样,向文件中写入一序列的字符串。
out_afile.close()
data_infile = os.path.join('../Data/enwiki/AA', "wiki_00") #路径拼接
data_outfile = os.path.join('../Data/enwiki/AA','wiki.txt')
fileprocess(data_infile,data_outfile)
注意:
(1)要处理的文件(data_infile)必须存在,而处理完成写入的文件(data_outfile)不用创建,会自动生成
(2)使用os.path.join进行路径拼接时,前面的路径部分需要存在,即存在Data/enwiki/AA文件夹,注意文件位置,如果脚本根目录与文件根目录在同一文件夹下,则要用“…/”
处理结果如下:(已经不含有标签,而且对文章的标题也添加了句号)
- 第二次处理:将每一个句子,放在一行,并除去多余的空格,代码如下
import os
import logging
def filesplit(infile,outfile,resfile):
in_wiki = open(infile,'r',encoding='utf-8')
out_wiki = open(outfile,'w',encoding='utf-8')
wiki_lines = in_wiki.read()
out_wiki.write(wiki_lines.replace('. ','.\n').strip())
in_wiki.close()
out_wiki.close()
read_wiki = open(outfile,'r',encoding='utf-8')
res_wiki = open(resfile,'w',encoding='utf-8')
read_wiki_line = read_wiki.readlines()
line_len = len(read_wiki_line)
for idx in range(line_len):
line = read_wiki_line[idx].strip(' ')
res_wiki.write(line)
logger.info("wiki数据:"+str(line_len)+'条')
logging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
in_wikifile = os.path.join('../Data/enwiki/AA','wiki.txt')
out_wikifile = os.path.join('../Data/enwiki/AA','wiki_en2.txt')
res_wikifile = os.path.join('../Data/enwiki/AA/res_wiki','wiki_en2.txt')
filesplit(in_wikifile,out_wikifile,res_wikifile)
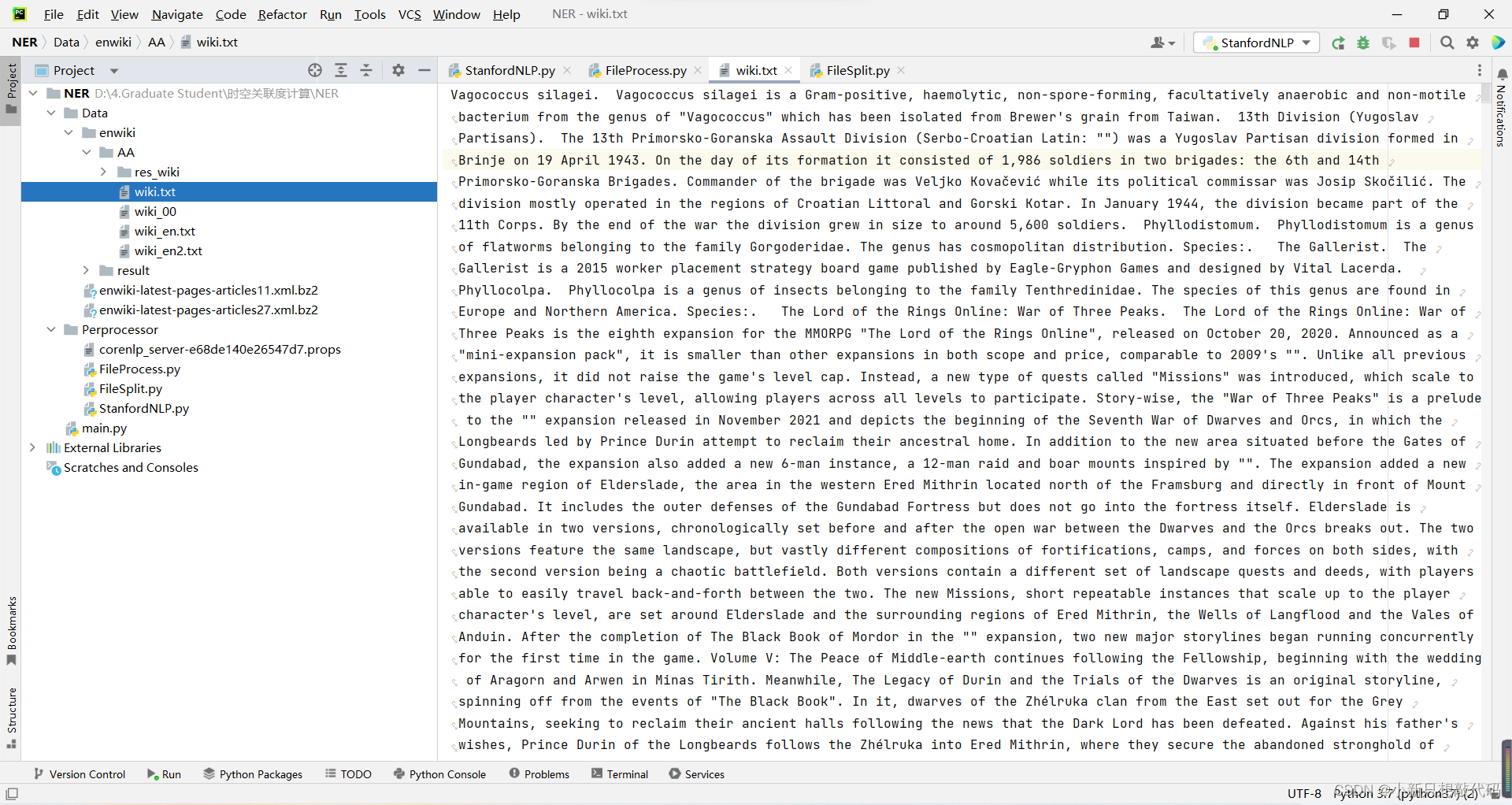
处理完成的结果如下:
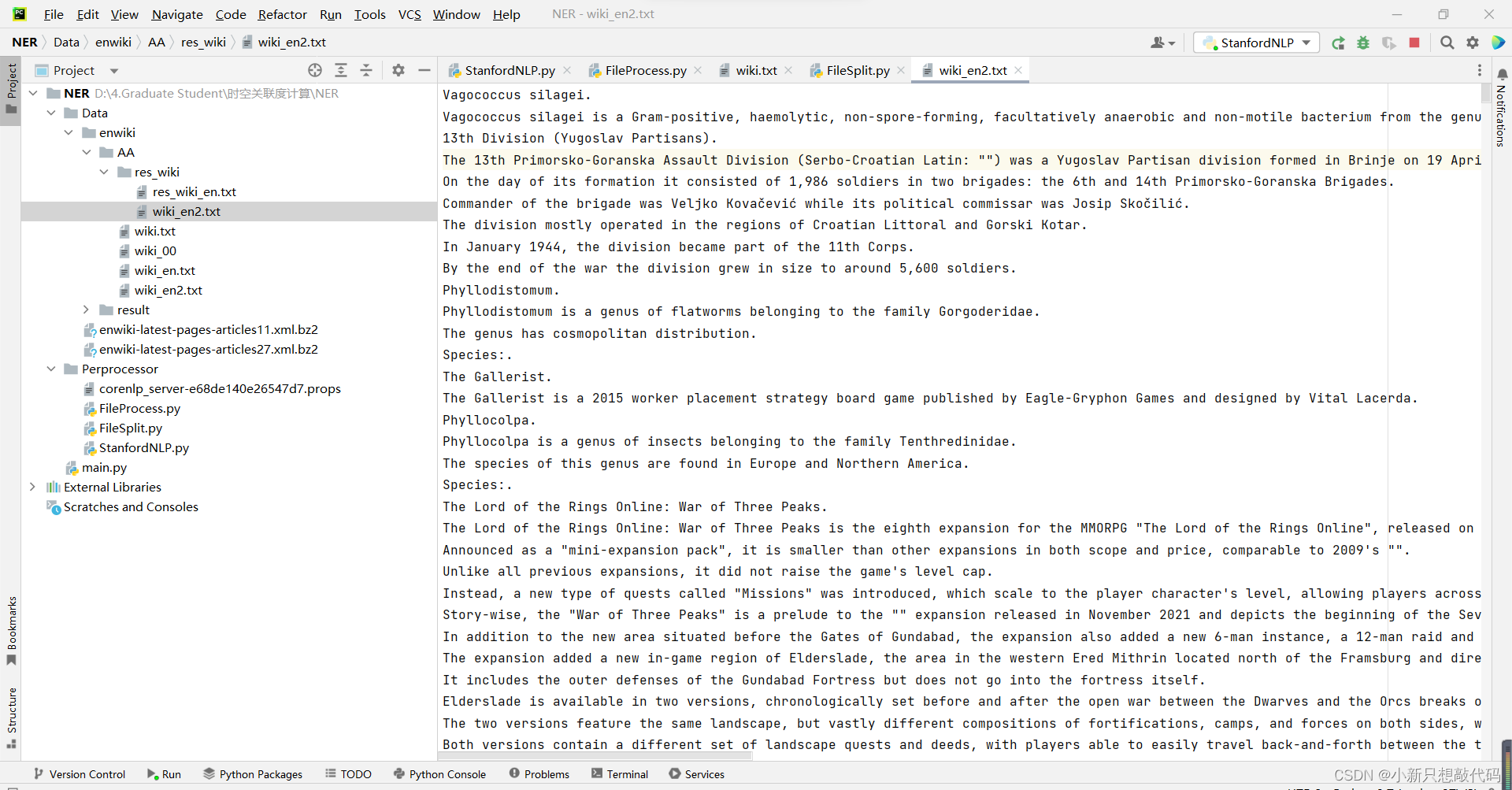
注:其实这部分的数据处理,还存在很多问题。这篇文章(自然语言处理(NLP)中英语文本分句的几个问题解决与思考)总结的很详细,所以后续还需要对其使用更完整的正则表达式进行处理
这是小新学习的小记录,有不对的地方希望UU们批评指正


















 182
182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









