







 本文深入探讨了JVM(Java Virtual Machine)的工作原理,包括其与JRE、JDK的关系。JVM作为Java运行环境的一部分,负责将字节码转换为机器码执行。讲解了类加载、执行引擎、运行时数据区等核心组件,并阐述了JVM内存的堆和栈管理。重点讨论了垃圾回收机制,如标记-清除、复制、标记-整理算法,以及如何通过减少GC频率、优化内存分配等方式提升性能。此外,还提到了监控和分析CPU、内存、I/O以进行性能调优的方法。
本文深入探讨了JVM(Java Virtual Machine)的工作原理,包括其与JRE、JDK的关系。JVM作为Java运行环境的一部分,负责将字节码转换为机器码执行。讲解了类加载、执行引擎、运行时数据区等核心组件,并阐述了JVM内存的堆和栈管理。重点讨论了垃圾回收机制,如标记-清除、复制、标记-整理算法,以及如何通过减少GC频率、优化内存分配等方式提升性能。此外,还提到了监控和分析CPU、内存、I/O以进行性能调优的方法。
JVM虚拟机,啥是jvm?jvm和jre,jdk的关系是什么?jvm原理是什么?
JVM是Java Virtual Machine(Java虚拟机)的缩写,JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的。
Java 虚拟机 (JVM)是提供运行时环境来驱动 Java 代码或应用程序的引擎。它将 Java 字节码转换为机器语言。JVM 是
Java 运行环境 (JRE) 的一部分。在其他编程语言中,编译器为特定系统生成机器代码。但是,Java编译器为称为Java
虚拟机的虚拟机生成代码
JDK是整个JAVA的核心,包括了Java运行环境JRE,一堆Java工具和Java基础的类库。通过JDK开发人员将源码文件(java文件)编译成字节码文件(class文件)。
JRE是Java运行环境,不含开发环境,即没有编译器和调试器。将class文件加载到内存准备运行
在JRE中就自带了JVM虚拟机,在操作系统上独立出了一个虚拟的操作系统JVM实现跨平台,JAVA代码的运行是运行在JVM虚拟机上,从而达到与操作系统无关
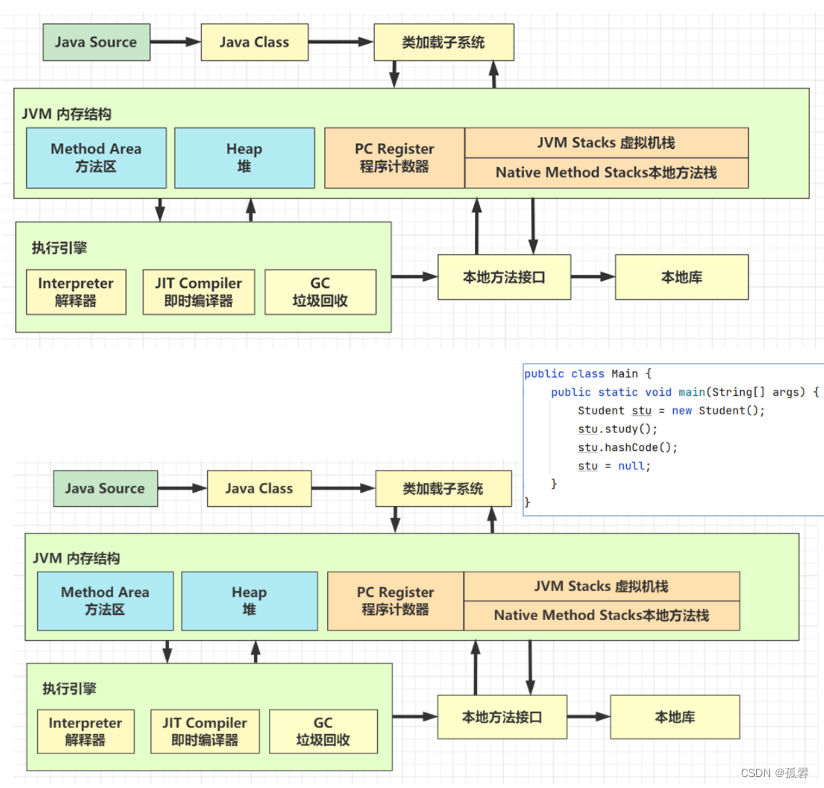
- 执行 javac 命令编译源代码为字节码
- 执行 java 命令
- 创建 JVM,调用类加载子系统加载 class,将类的信息存入方法区
- 创建 main 线程,使用的内存区域是 JVM 虚拟机栈,开始执行 main 方法代码
- 如果遇到了未见过的类,会继续触发类加载过程,同样会存入方法区
- 需要创建对象,会使用堆内存来存储对象
- 不再使用的对象,会由垃圾回收器在内存不足时回收其内存
- 调用方法时,方法内的局部变量、方法参数所使用的是 JVM 虚拟机栈中的栈帧内存
- 调用方法时,先要到方法区获得到该方法的字节码指令,由解释器将字节码指令解释为机器码执行
- 调用方法时,会将要执行的指令行号读到程序计数器,这样当发生了线程切换,恢复时就可以从中断的位置继续
- 对于非 java 实现的方法调用,使用内存称为本地方法栈(见说明)
- 对于热点方法调用,或者频繁的循环代码,由 JIT 即时编译器将这些代码编译成机器码缓存,提高执行性能
1 在java中,哪些内存会被回收?如何判断对象是否可以被回收?
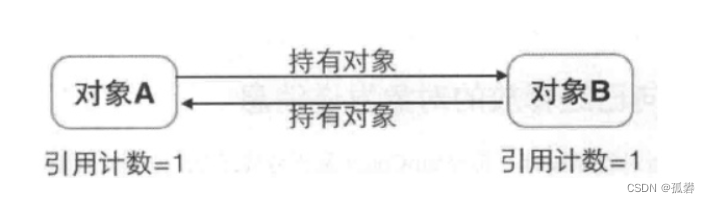
1.1 引用计数法:
引用计数法是为对象添加一个引用计数器,然后用一块额外的内存区域来存储每个对象被引用的次数,当对象每有一个地方引用它时,那我们对该对象的引用计数就会加1,反之每有一个引用失效时,我们对该对象的引用计数就会减1, 当对象的被引用次数为0时,那么我们可以认为这个对象是不会被再次使用了,通过这种方式我们能快速直观的定位到这些可回收的对象,从而进行清理。
引用计数法缺陷:
1、无法解决循环引用的问题
引用计数法虽然很直观高效,但是通过引用计数法是没办法扫描到一种特殊情况下的“可回收”对象,这种特殊情况就是对象循环引用的时候,比如A对象引用了B,B对象引用了A,除此之外他们两个没有被任何其他对象引用,那么其实这部分对象也属于“可回收”的对象,但是通过引用计数法是没办法定位的。
2.JVM包含那些组件
JVM的主要组成部分包括:类加载引擎,运行时数据区,执行引擎,本地库接口
· 两个子系统为Class loader(类装载)、Execution engine(执行引擎); · 两个组件为Runtime data
area(运行时数据区)、Native Interface(本地接口)。 · Class
loader(类装载):根据给定的全限定名类名(如:java.lang.Object)来装载class文件到Runtime data
area中的method area。 · Execution engine(执行引擎):执行classes中的指令。 · Native
Interface(本地接口):与native libraries交互,是其它编程语言交互的接口。 · Runtime data
area(运行时数据区域):这就是我们常说的JVM的内存。
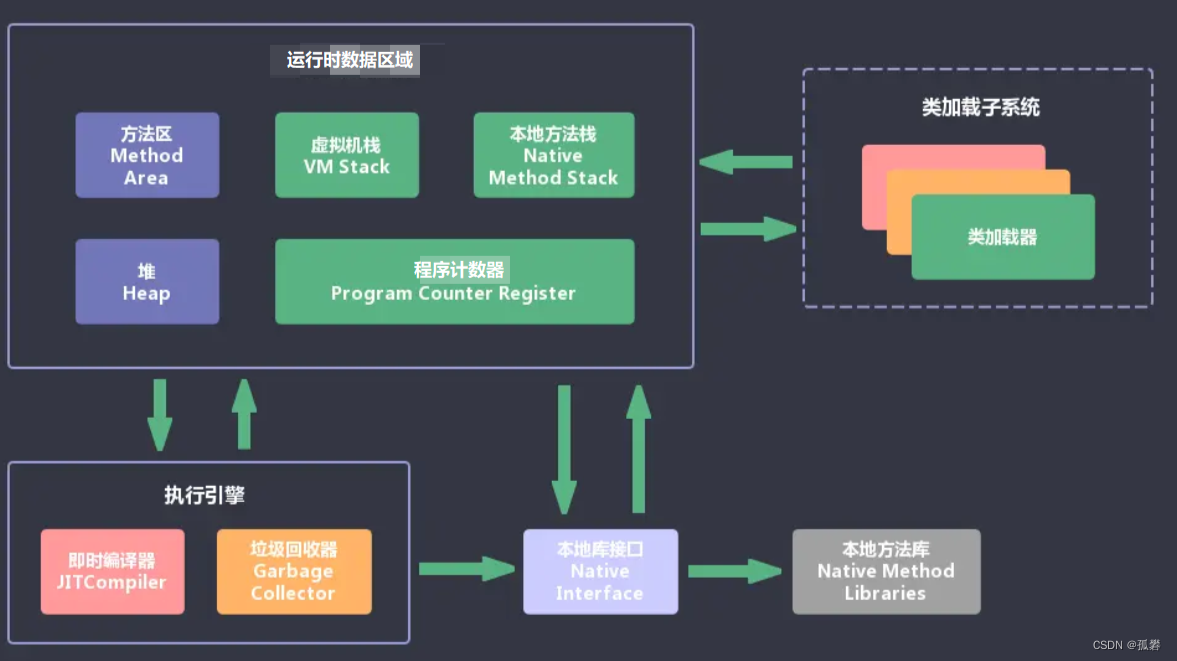
首先,通过类加载器(ClassLoader)会把 Java 代码转换成字节码; 其次,运行时数据区(Runtime Data
Area)再把字节码加载到内存中,而字节码文件只是 JVM 的一套指令集规范,并不能直接交给底层操作系统去执行;
于是,需要特定的命令解析器执行引擎(Execution Engine),将字节码翻译成底层系统指令,再交由 CPU 去执行;
最后,此过程中需要调用其他语言的本地库接口(Native Interface)来实现整个程序的功能。
栈:存放一些局部变量 没有默认初始化值
基本数据类型 和 对象的引用
堆:存放new 的对象 数组 有初始值 有地址值 方法区:是各个线程共享的内存区域 存储已被Java虚拟机加载的类信息、常量池、静态变量、以及编译器编译后的代码。
程序计数器:用于存储下一条指令的地址。
记住下一条jvm指令的执行地址 本地方法栈: 给本地方法提供内存空间,存放被native修饰的方法
3.JVM如何优化?
1. 减少GC的频率和Full GC次数,STW(stop the world)的停顿时间和次数 避免使用大对象和数组的使用
2.根据自己的业务需求调整堆的内存分配比例
3.分配新生代和老年代的比例(默认1:2)
4.分配新生代里伊甸区和s0,s1的分配比例(默认8:1:1)
**
性能监控:问题没有发生,你并不知道你需要调优什么。此时需要一些系统、应用的监控工具来发现问题。
性能分析:问题已经发生,但是你并不知道问题到底出在哪里。此时就需要使用工具、经验对系统、应用进行瓶颈分析,以求定位到问题原因。
性能调优:经过上一步的分析定位到了问题所在,需要对问题进行解决,使用代码、配置等手段进行优化。 对于jvm我们是使用os诊断
CPU、Memory、I/O 三个方面
**
Cpu: 对于 CPU 主要关注平均负载(Load Average),CPU 使用率,上下文切换次数
当程序响应变慢的时候,首先使用top、vmstat、ps等命令查看系统的cpu使用率是否有异常,从而可以判断出是否是cpu繁忙造成的性能问题。其中,主要通过us(用户进程所占的%)这个数据来看异常的进程信息。当us接近100%甚至更高时,可以确定是cpu繁忙造成的响应缓慢。一般说来,cpu繁忙的原因有以下几个
线程中有无限空循环、无阻塞、正则匹配或者单纯的计算 发生了频繁的gc 多线程的上下文切换内存:这个地方我们主要关注内存是否够用 而对于java来说内存问题主要在 堆内内存跟堆外内存
创建的对象:这个是存储在堆中的,需要控制好对象的数量和大小,尤其是大的对象很容易进入老年代 频繁gc
全局集合:全局集合通常是生命周期比较长的,因此需要特别注意全局集合的使用 oom导致内存溢出
缓存:缓存选用的数据结构不同,会很大程序影响内存的大小和gc ClassLoader:主要是动态加载类容易造成永久代内存不足
多线程:线程分配会占用本地内存,过多的线程也会造成内存不足Io:`I/O 包括磁盘 I/O 和网络 I/O,一般情况下磁盘更容易出现 I/O 瓶颈。通过 iostat 可以查看磁盘的读写情况,通过
CPU 的 I/O wait 可以看出磁盘 I/O 是否正常。如果磁盘 I/O
一直处于很高的状态,说明磁盘太慢或故障,成为了性能瓶颈,需要进行应用优化或者磁盘更换。大量的随机读写 设备慢 文件太大
4.有哪些垃圾回收算法?
标记-清除
统一标记出需要回收的对象,标记完成之后统一回收所有被标记的对象,而由于标记的过程需要遍历所有的GC ROOT,清除的过程也要遍历堆中所有的对象,所以标记-清除算法的效率低下,同时也带来了内存碎片的问题。
复制算法
它将内存分为大小相等的两块区域,每次使用其中的一块,当一块内存使用完之后,将还存活的对象拷贝到另外一块内存区域中,然后把当前内存清空,这样性能和内存碎片的问题得以解决。但是同时带来了另外一个问题,可使用的内存空间缩小了一半!
标记-整理
针对老年代再用复制算法显然不合适,因为进入老年代的对象都存活率比较高了,这时候再频繁的复制对性能影响就比较大,而且也不会再有另外的空间进行兜底。所以针对老年代的特点,通过标记-整理算法,标记出所有的存活对象,让所有存活的对象都向一端移动,然后清理掉边界以外的内存空间。
垃圾回收回收的是堆内存中的垃圾还是栈内存中的垃圾?
堆

















 1157
1157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









