







论文链接:https://arxiv.org/abs/2410.05779
项目链接:https://github.com/HKUDS/LightRAG
💡 文章信息
| Title | LightRAG: Simple and Fast Retrieval-Augmented Generation |
|---|---|
| Journal | (10.48550/arXiv.2410.05779) |
| Authors | Guo Zirui,Xia Lianghao,Yu Yanhua,Ao Tu,Huang Chao |
| Pub.date | 2024-11-07 |
📕 研究动机
当前RAG存在如下问题:
-
依赖于平面数据表示,难以捕捉实体间复杂的依赖关系
-
缺乏上下文感知能力,导致生成的回答片段化,无法完整表达复杂主题之间的关联
因此,本文提出一种基于图结构的RAG框架,即LightRAG,利用图结构的优势进行文本索引与双层检索,增强信息整合能力,同时通过增量更新机制提升动态数据适应性。
📜 研究目标
-
全面信息检索
-
增强检索效率
-
快速响应新数据
📊 研究方法
1. 实验设置
-
数据集
-
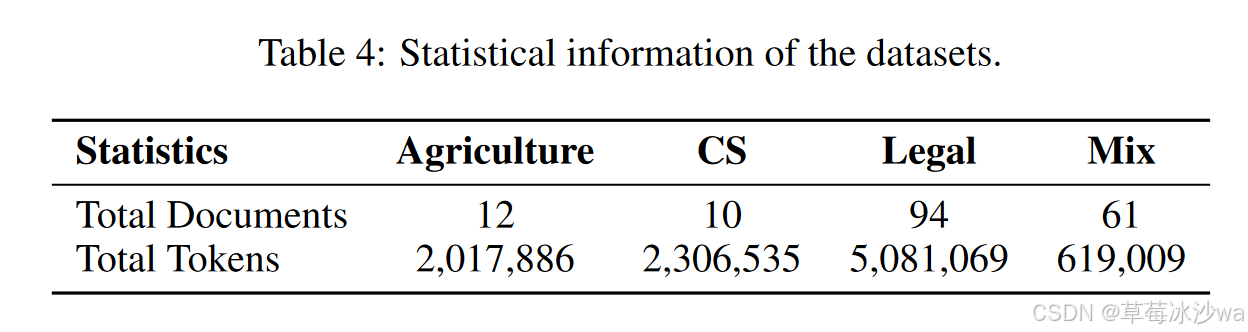
Agriculture:该领域侧重于农业实践,涵盖了一系列的主题,包括养蜂、蜂巢管理、作物生产和疾病预防。
-
CS:该领域侧重于计算机科学,并包括数据科学和软件工程的关键领域。它特别强调了机器学习和大数据处理,以推荐系统、分类算法和使用Spark的实时分析等内容为特色.
-
Legal:该领域以企业法律实践为中心,处理企业重组、法律协议、法规遵从性和治理,重点关注法律和金融部门。
-
Mixed:这个领域提供了丰富的文学、传记和哲学文本,跨越了广泛的学科范围,包括文化、历史和哲学研究。
-
像GraphRAG一样,利用LLM生成5个用户,每个用户生成5个任务,每个任务生成5个问题。因此,对于每个数据集,包括125个问题。
-
基线
-
Naive RAG
-
RQ-RAG
-
HyDE
-
GraphRAG
-
-
参数
-
LLM:GPT-4o-mini
-
chunk size:1200
-
-
评价指标
-
全面性:答案在多大程度上全面地覆盖了问题的所有方面和细节?
-
多样性:答案在提供与问题相关的不同观点和见解方面有多丰富和多样?
-
启发性:答案在多大程度上帮助读者理解主题并做出明智的判断?
-
总体上:该维度评估前三个标准的累积表现,以确定最佳的总体答案。
-
2. 实验模型
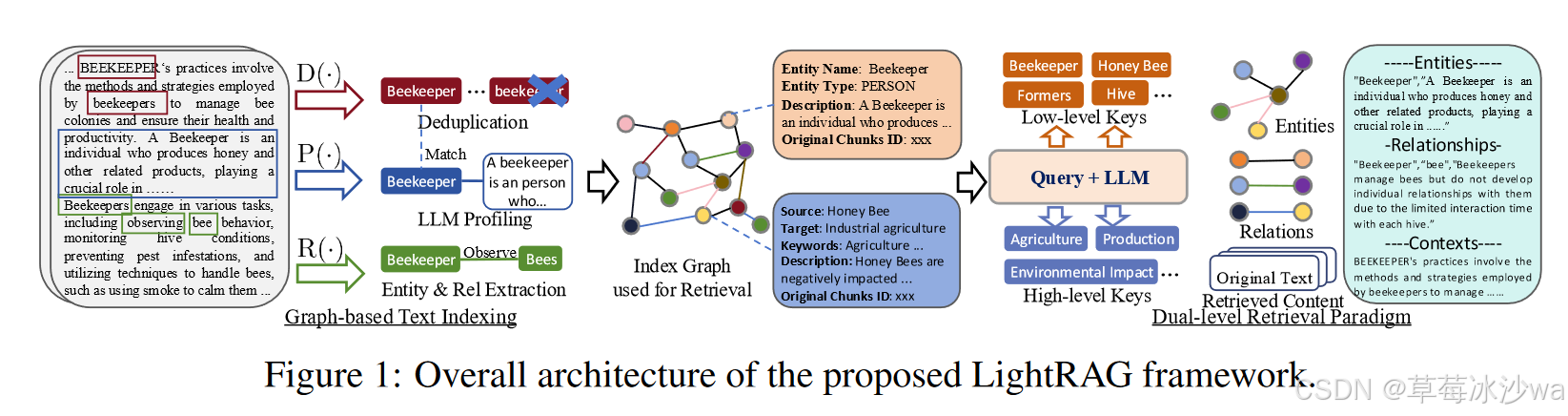
(1)基于图结构的文本检索
-
抽取实体和关系:R(·)提示LLM识别文本数据中的实体及其关系。
-
LLM对键值对生成的分析:P(·)是利用LLM的一个分析函数,为V中的每个实体节点和E中的关系边生成一个文本键值对(K,V)。每个索引键都是一个能够有效检索的单词或短语,而相应的值是一个文本段落,总结来自外部数据的相关片段,以帮助生成文本。
-
执行重复数据删除以优化图形操作:D(·)可以识别并合并来自原始文本中不同部分的相同实体和关系。
优点:
全局信息的理解:可以通过多跳子图提取全局信息
增强检索效果:从图中得到的K-V结构进行了优化,以实现快速、精确的检索。
(2)双层检索策略
-
低层检索:该层级主要集中于检索特定的实体及其关联的属性或关系。此层级的查询是面向细节的,其目的是提取关于图中特定节点或边的精确信息。
-
高层检索:该层级涉及更广泛的主题和总体框架。此层级的查询聚合了跨多个相关实体和关系的信息,提供了对更高层次概念和摘要的洞察,而非具体细节。
优点:
通过在向量数据库中匹配局部/全局关键词,可以高效检索相关实体和关系。
通过从构建的知识图谱中整合相关结构信息,增强了结果的全面性。
(3)检索增强答案生成
-
利用检索信息:利用LLM根据检索到的数据生成答案。这些数据包括相关实体和关系的V。
-
上下文集成和答案生成:将查询与多源文本统一起来,LLM可以根据用户的需求生成信息丰富的答案,确保与查询的意图保持一致。
(4)LightRAG框架的复杂性分析
-
基于图结构的文本检索:大模型需要调用total tokens/chunk size次
-
基于图结构的检索:对于每个查询,需要使用LLM去生成相关的关键词
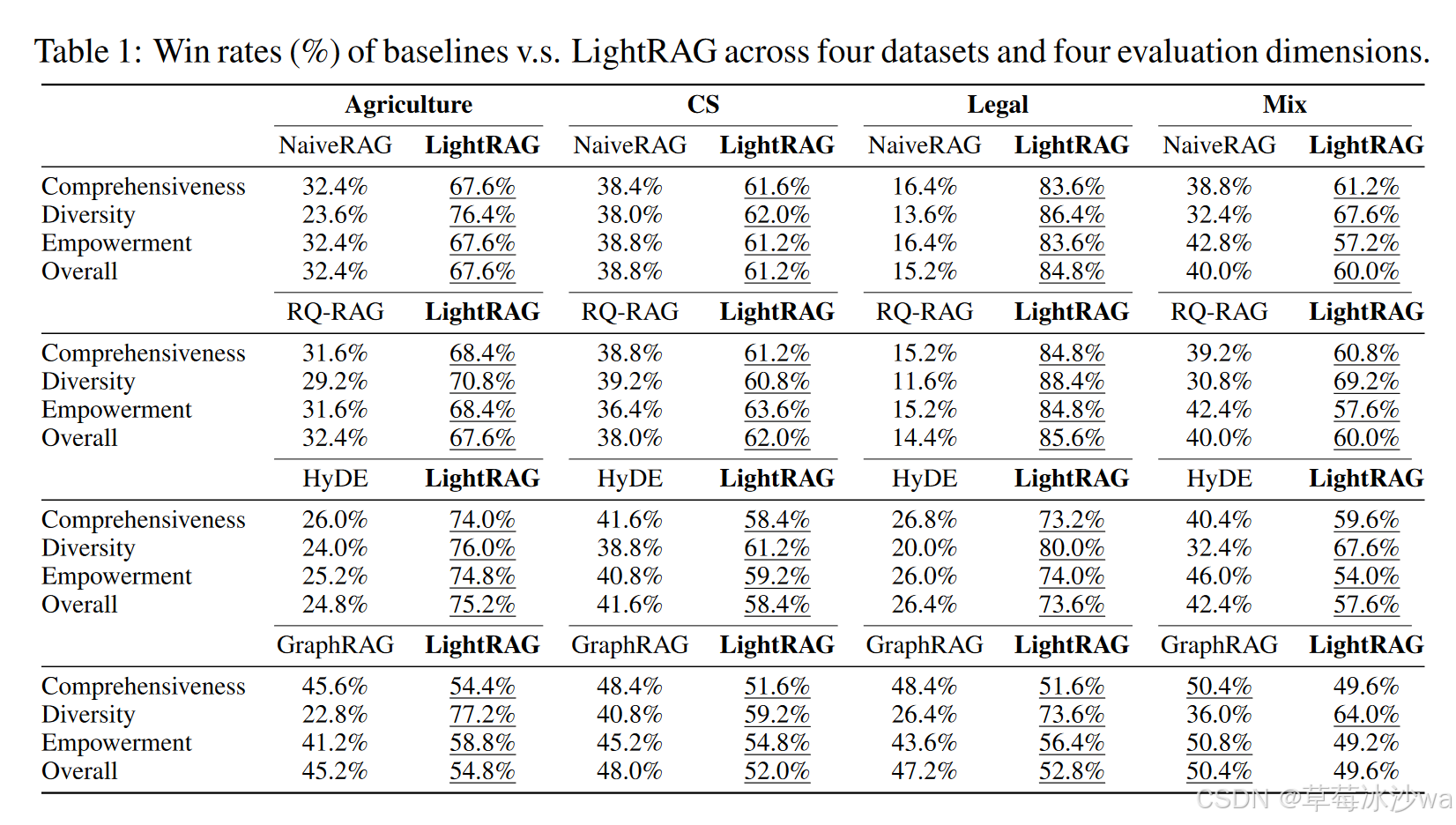
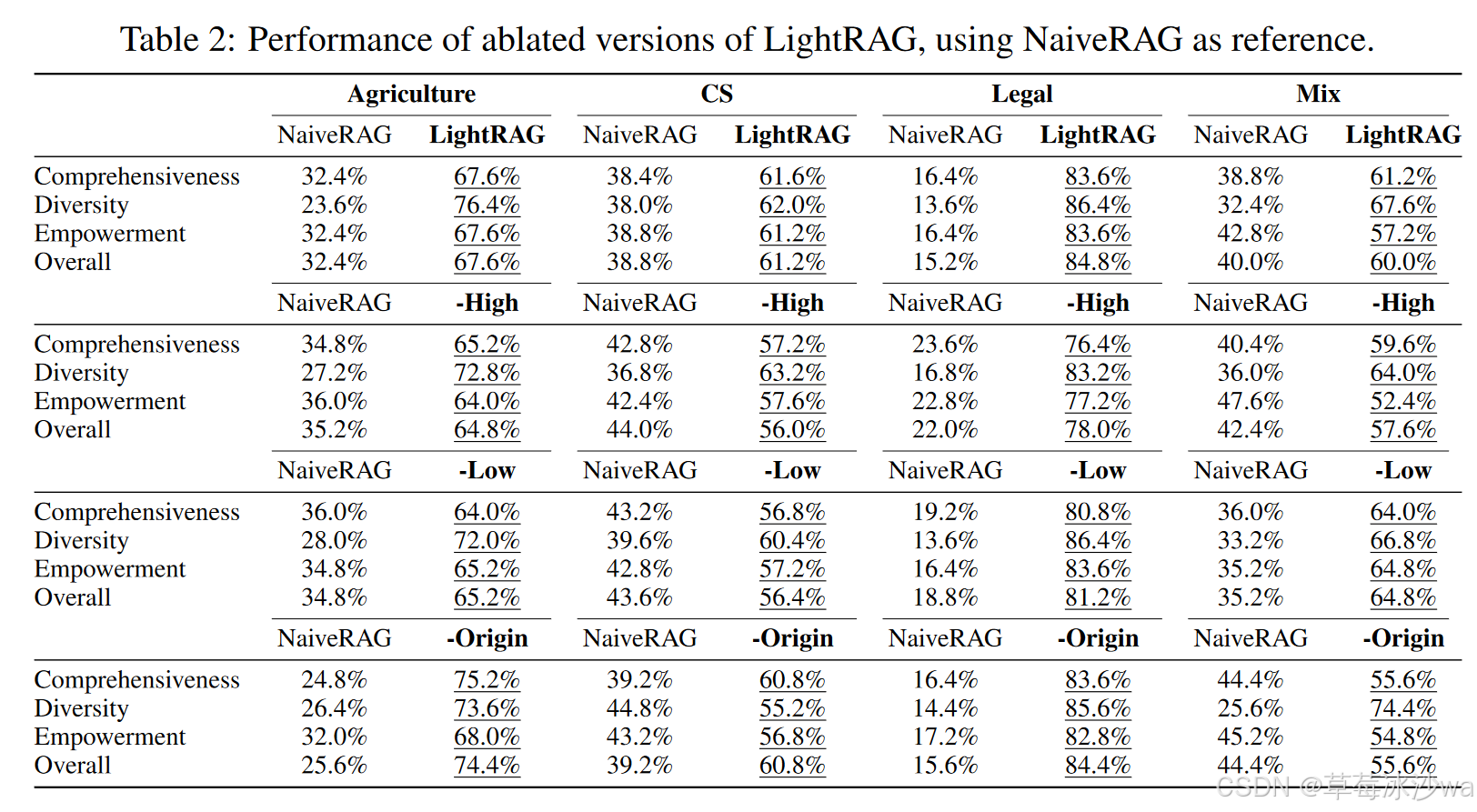
3. 实验结果
🚩 研究结论
-
图增强RAG系统在大规模语料库中具有优越性
-
LightRAG的双层检索机制有效解决了详细查询和抽象查询,增强了回答的多样性
-
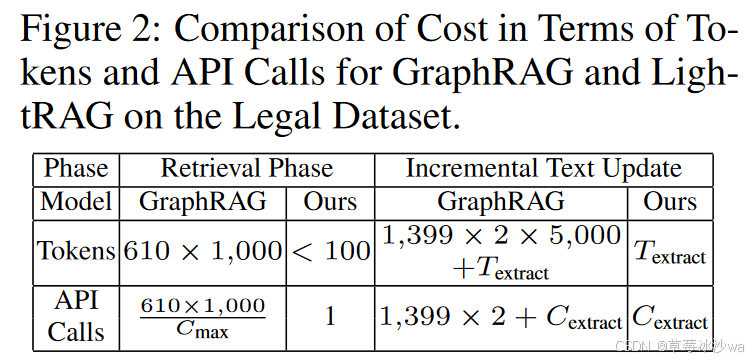
相较于GraphRAG,成本更低
📌 思考体会
创新点
-
引入图结构:结合知识图与向量表示,实现更精确、高效的检索,提升了对复杂语义依赖的理解能力。
-
双层检索策略:低层检索关注具体实体及其关系的精确信息,高层检索涵盖更广泛的主题和主题层次。因此,可以同时支持详细和抽象查询,能够应对多样化的用户需求。(GraphRAG中虽然也有分层,但层次较多,效率较低,成本较高)
-
增量更新算法:无需重建索引即可快速适应新数据,提高了系统的可扩展性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









