







 文章介绍了如何利用TensorBoard的SummaryWriter类来跟踪训练过程中loss的变化以及模型在不同阶段的输出。通过add_scalar方法添加标量数据(如loss),add_image方法添加图像数据(如激活图或梯度)。这些工具帮助开发者理解模型行为并优化性能。
文章介绍了如何利用TensorBoard的SummaryWriter类来跟踪训练过程中loss的变化以及模型在不同阶段的输出。通过add_scalar方法添加标量数据(如loss),add_image方法添加图像数据(如激活图或梯度)。这些工具帮助开发者理解模型行为并优化性能。
1 用途
1、训练过程中loss是如何变化的,是否正常或是否按预想的变化,选择什么样的模型
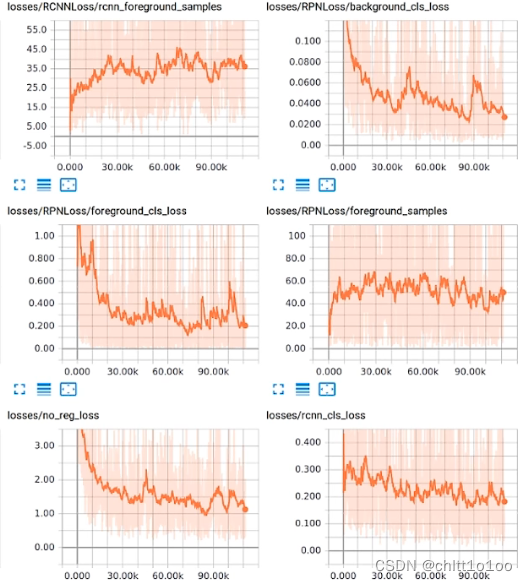
2、模型在不同阶段的输出
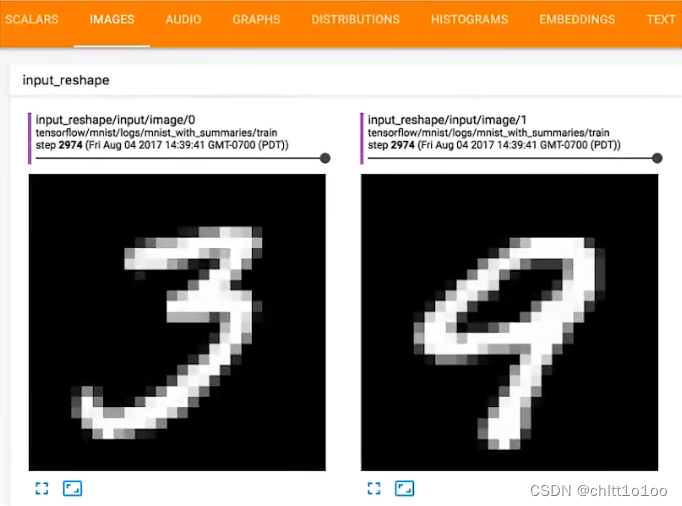
2 需要导入的类和常用的方法
from torch.utils.tensorboard import SummaryWriter
writer.add_image()
writer.add_scalar()查看SummaryWriter的官方文档
直接向log_dir文件夹写入事件文件,可以被TensorBoard进行解析
class SummaryWriter:
"""Writes entries directly to event files in the log_dir to be
consumed by TensorBoard.
The `SummaryWriter` class provides a high-level API to create an event file
in a given directory and add summaries and events to it. The class updates the
file contents asynchronously. This allows a training program to call methods
to add data to the file directly from the training loop, without slowing down
training.
"""实例化SummaryWriter类
writer = SummaryWriter("logs") # 把对应的事件文件存储到logs文件夹下2.1 add_scalar()
def add_scalar(
self,
tag,
scalar_value,
global_step=None,
walltime=None,
new_style=False,
double_precision=False,
):
"""Add scalar data to summary.
Args:
tag (str): Data identifier
scalar_value (float or string/blobname): Value to save
global_step (int): Global step value to record
walltime (float): Optional override default walltime (time.time())
with seconds after epoch of event
new_style (boolean): Whether to use new style (tensor field) or old
style (simple_value field). New style could lead to faster data loading.
Examples::
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
x = range(100)
for i in x:
writer.add_scalar('y=2x', i * 2, i)
writer.close()
Expected result:
.. image:: _static/img/tensorboard/add_scalar.png
:scale: 50 %
"""
torch._C._log_api_usage_once("tensorboard.logging.add_scalar")
if self._check_caffe2_blob(scalar_value):
from caffe2.python import workspace
scalar_value = workspace.FetchBlob(scalar_value)
summary = scalar(
tag, scalar_value, new_style=new_style, double_precision=double_precision
)
self._get_file_writer().add_summary(summary, global_step, walltime)参数:
- tag:类似于图标的标题title
- scalar_value:(y轴)对应的需要保存的数值
- global_step:(x轴)步数,训练到多少步
举例:
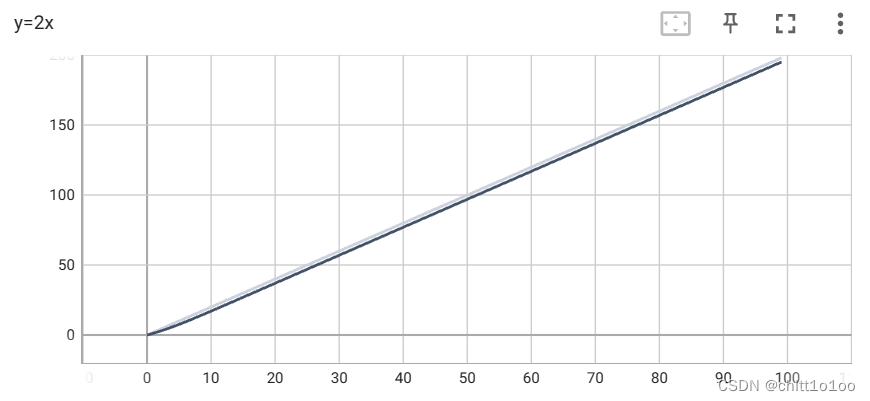
from torch.utils.tensorboard import SummaryWriter #导入SummaryWriter类
#创建实例
writer=SummaryWriter("logs") #把对应的事件文件存储到logs文件夹下
for i in range(100):
writer.add_scalar("y=2x",2*i,i)
writer.close()运行后多了一个logs文件夹,里面是TensorBoard的一些事件文件。
打开事件文件的方法:在Terminal里输入:tensorboard --logdir=logs
默认打开的都是6006端口,也可以指定端口:tensorboard --logdir=logs --port=6007

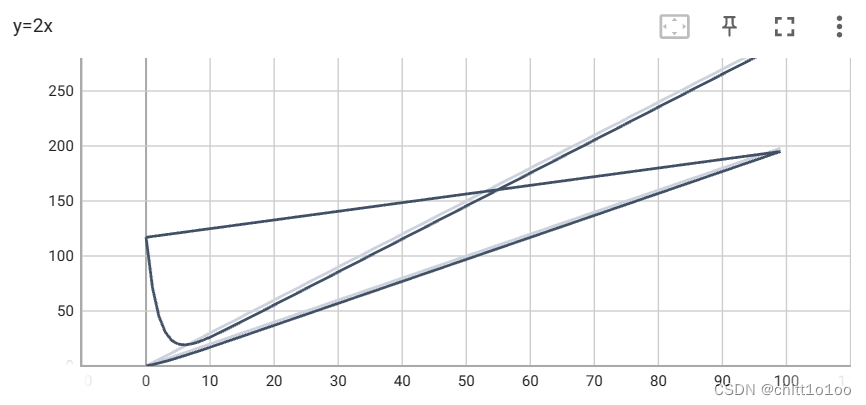
每向writer中写入新的事件,也记录了上一个事件,会出现过拟合现象,例如
解决方法:删除logs下的文件,重新运行代码
2.2 add_image()
def add_image(
self, tag, img_tensor, global_step=None, walltime=None, dataformats="CHW"
):
"""Add image data to summary.
Note that this requires the ``pillow`` package.
Args:
tag (str): Data identifier
img_tensor (torch.Tensor, numpy.ndarray, or string/blobname): Image data
global_step (int): Global step value to record
walltime (float): Optional override default walltime (time.time())
seconds after epoch of event
dataformats (str): Image data format specification of the form
CHW, HWC, HW, WH, etc.
Shape:
img_tensor: Default is :math:`(3, H, W)`. You can use ``torchvision.utils.make_grid()`` to
convert a batch of tensor into 3xHxW format or call ``add_images`` and let us do the job.
Tensor with :math:`(1, H, W)`, :math:`(H, W)`, :math:`(H, W, 3)` is also suitable as long as
corresponding ``dataformats`` argument is passed, e.g. ``CHW``, ``HWC``, ``HW``.
Examples::
from torch.utils.tensorboard import SummaryWriter
import numpy as np
img = np.zeros((3, 100, 100))
img[0] = np.arange(0, 10000).reshape(100, 100) / 10000
img[1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
img_HWC = np.zeros((100, 100, 3))
img_HWC[:, :, 0] = np.arange(0, 10000).reshape(100, 100) / 10000
img_HWC[:, :, 1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000
writer = SummaryWriter()
writer.add_image('my_image', img, 0)
# If you have non-default dimension setting, set the dataformats argument.
writer.add_image('my_image_HWC', img_HWC, 0, dataformats='HWC')
writer.close()
Expected result:
.. image:: _static/img/tensorboard/add_image.png
:scale: 50 %
"""
torch._C._log_api_usage_once("tensorboard.logging.add_image")
if self._check_caffe2_blob(img_tensor):
from caffe2.python import workspace
img_tensor = workspace.FetchBlob(img_tensor)
self._get_file_writer().add_summary(
image(tag, img_tensor, dataformats=dataformats), global_step, walltime
)
参数:
- tag:对应图像的title
- img_tensor:图像的数据类型,只能是torch.Tensor、numpy.array、string/blobname
- global_step:训练步骤,int 类型
举例:
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
writer = SummaryWriter("logs")
img_path = "dataset/train/ants/5650366_e22b7e1065.jpg"
#<class 'PIL.JpegImagePlugin.JpegImageFile'> 类型不符合要求
img_PIL = Image.open(img_path)
#把PIL类型的img变量转换为numpy类型(add_image() 函数所需要的图像的数据类型),重新赋值给img_array
img_array = np.array(img_PIL)
print(type(img_array)) #<class 'numpy.ndarray'>
print(img_array.shape) #(375, 500, 3) 即(H,W,C)(高度,宽度,通道)
writer.add_image("test",img_array,2,dataformats='HWC')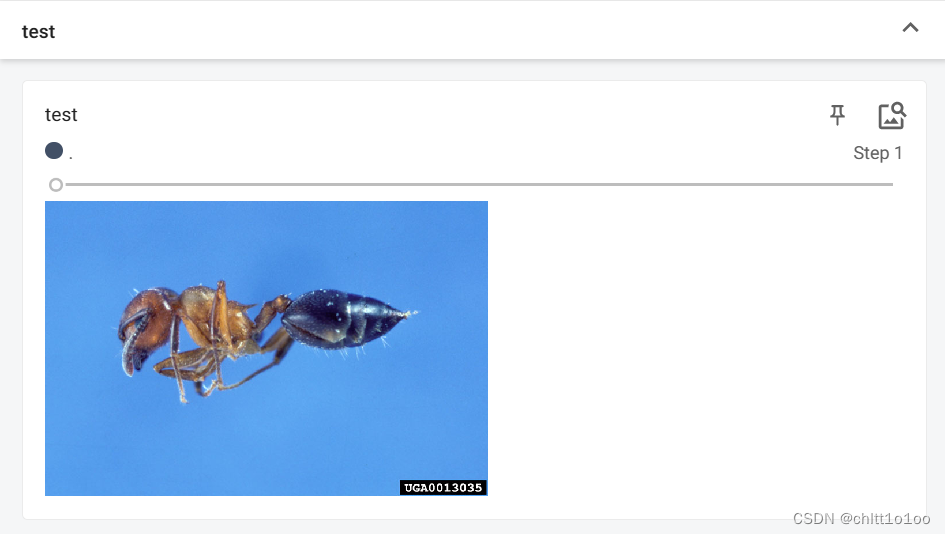
在一个title下,通过滑块显示每一步的图形,可以直观地观察训练中给model提供了哪些数据,或者想对model进行测试时,可以看到每个阶段的输出结果。如果想要单独显示,重命名一下title即可

















 2337
2337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









