




题目
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
每行的元素从左到右升序排列。
每列的元素从上到下升序排列。
示例 1:
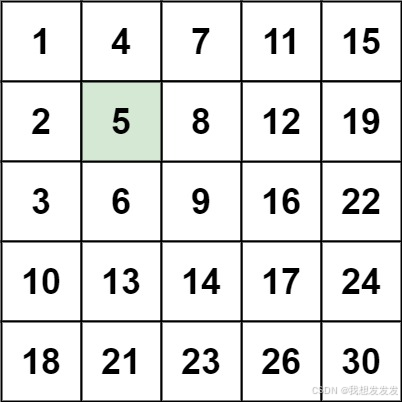
输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5
输出:true
示例 2:
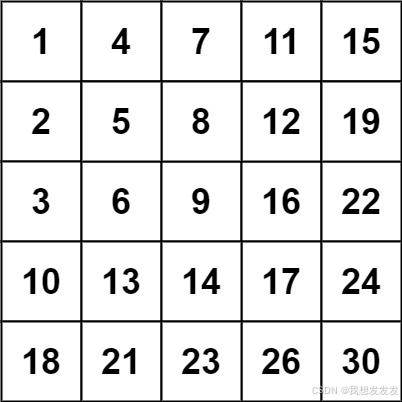
输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 20
输出:false
提示:
m == matrix.length
n == matrix[i].length
1 <= n, m <= 300
-109 <= matrix[i][j] <= 109
每行的所有元素从左到右升序排列
每列的所有元素从上到下升序排列
-109 <= target <= 109
题解
class Solution {
public:
bool searchMatrix(vector<vector<int>>& matrix, int target) {
int m = size(matrix);
int n = size(matrix[0]);
int row = 0;
int col = n - 1;
while(row < m && col >= 0){
int current = matrix[row][col];
if(current == target){
return true;
}else if(current > target){
col -= 1;
}else{
row++;
}
}
return false;
}
};
算法原理
选择起始位置
算法选择从矩阵的右上角开始搜索(当然,从左下角开始搜索也是可行的,原理类似)。假设矩阵为 matrix,行数为 m,列数为 n,起始位置的坐标为 (0, n - 1),即第一行的最后一列元素。选择这个位置的原因在于它具有独特的性质:
- 它是所在行的最大值。
- 它是所在列的最小值。
搜索过程中的比较与移动规则
从起始位置开始,将当前位置的元素 matrix[row][col] 与目标值 target 进行比较,根据比较结果进行不同的操作:
1. 找到目标值
如果 matrix[row][col] 等于 target,说明已经找到了目标值,直接返回 true。
2. 当前元素大于目标值
如果 matrix[row][col] 大于 target,由于当前列的元素是从上到下升序排列的,所以当前列中所有位于当前元素下方的元素都必然大于 target,可以直接排除当前列。因此,将列索引 col 减 1,向左移动一列,继续进行搜索。
3. 当前元素小于目标值
如果 matrix[row][col] 小于 target,因为当前行的元素是从左到右升序排列的,所以当前行中所有位于当前元素左侧的元素都必然小于 target,可以直接排除当前行。于是,将行索引 row 加 1,向下移动一行,继续搜索。
终止条件
搜索过程会一直持续,直到满足以下两个条件之一:
- 找到目标值,即
matrix[row][col]等于target,此时返回true。 - 超出矩阵边界,也就是
row >= m或者col < 0,说明在整个矩阵中都没有找到目标值,返回false。
复杂度分析
- 时间复杂度:在最坏的情况下,需要从矩阵的右上角移动到左下角,每次移动只能向上或向左移动一步。因此,最多需要移动
m + n次,其中m是矩阵的行数,n是矩阵的列数。所以,时间复杂度为 O ( m + n ) O(m + n) O(m+n)。 - 空间复杂度:算法只使用了常数级的额外空间,如几个用于记录行索引、列索引的变量,因此空间复杂度为 O ( 1 ) O(1) O(1)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









