 HTTP请求数据要点及Python实现
HTTP请求数据要点及Python实现





请求数据最重要的三个要点
1. 请求URL
请求URL是客户端向服务器发出请求的目标地址。它指定了要访问的资源位置,并且可以包含路径和查询参数。URL不仅决定了请求的目标,还可以传递必要的信息给服务器;
- 格式:http(s)://域名/路径?查询参数(例如:https://api.example.com/search?q=keyword&page=2);
2. 请求方法 (Request Method)
- GET:请求读取数据,常用于获取网页内容或其他资源;
- POST:用于向服务器提交数据,常用于提交表单或上传文件;
3. 状态代码 (Status Code)
状态代码是服务器响应的一部分,用来告知客户端关于请求处理的结果。状态码是一个三位数字的代码,通常伴随着一个简短的原因短语(Reason Phrase),帮助解释状态码的具体含义;
我们先讨论类型的GET请求格式:
对于GET请求来说,根据HTTP协议规范,GET请求主要用于从服务器获取资源,而不用于向服务器发送大量数据。因此,GET请求的主要组成部分是:
- 请求URL:定义了请求的目标资源,包括协议、域名、路径和查询参数;
- 请求标头:提供了关于请求本身的额外信息,如客户端的身份、接受的内容类型、缓存控制等,帮助服务器更好地理解和处理请求;
标头:通常包括URL的连接,也就是目标资源的位置,负载:对于GET请求:负载通常是空的,因为所有参数都通过URL传递。对于POST请求:负载包含了要提交给服务器的数据,例如表单数据或JSON对象, 预览:指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段;

那么如何找到数据的存储位置呢?很多Web应用通过URL参数实现分页功能,常见的分页参数包括page、offset、limit等。首先我们先导航到“Network”标签,通过观察不同页面的URL变化,可以推测出数据的组织方式,如果页面内容随着page参数的变化而有序更新,则说明数据可能是按页存储,再通过预览来看是否保存有效数据;
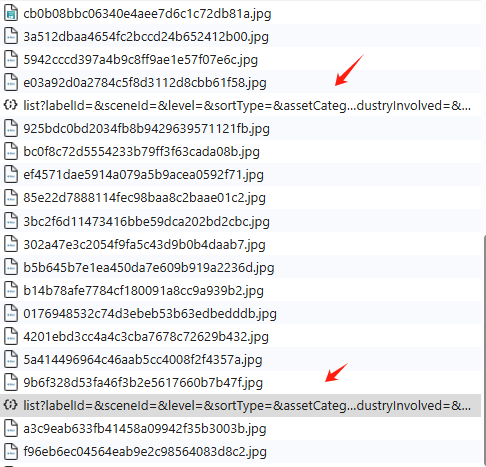
先讲一下方法思路,一共三个步骤;
方法思路
- 检查请求是否成功;
- 获取标签(提取数据);
- 写入翻页循环,并最终将所有提取的数据保存到CSV文件中;
第一步部分:对于GET请求,找到有效数据的URL之后,接下来,就是获取数据的步骤,先打印是否响应和响应内容;
完整代码#运行环境 Python 3.11
import requests
def fetch_data():
url = "https://api.example.com/search?q=keyword&page=2"
try:
response = requests.get(url)
response.raise_for_status() # 检查请求是否成功
# 打印原始响应内容
print("原始响应内容:", response.text)
except requests.exceptions.RequestException as e:
print("请求异常:", e)
if __name__ == "__main__":
fetch_data()
第二步部分:如果我们收到信息code = 200,意味着请求成功,接下来就可以开始分析响应内容,双击URL并查看字段,识别出所有感兴趣的字段,确认每个字段的数据类型(字符串、数字、布尔值等),如果响应是嵌套的JSON对象或数组,注意其层次结构 ,有助于后续保存csv;

第三步部分:通过for 函数进行遍历,比如for page in range(1, total_pages + 1)将遍历多页数据,调用检查请求和提取数据的功能,并最终将所有提取的数据保存到CSV文件中;
我们再讨论类型的POST请求格式:
一样,我们通过先看Request Method,来确定请求方法,这里是POST请求;
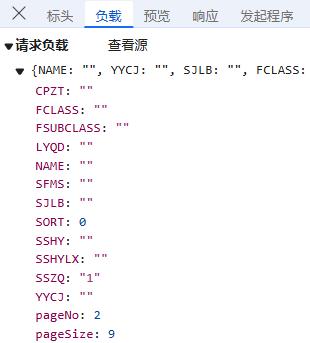
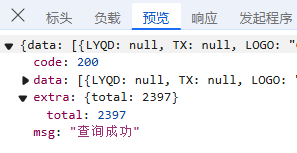
接下来,我们来审视负载,负载通常包含若干参数信息,通过调整这些参数,我们可以改变请求所获取的内容,进而遍历整个数据集。如下图,我们就可以看到一些数据标签,当前页码,每页包含多少条记录;
有些网站负载是加密的,这时候,我们把整个负载一起引用上即可,只是当数量量大的时候需要遍历所有负载,这个比较费时费力;
最后,我们来看预览,就可以知道我们要获取的数据包含哪些标签,数据量是多少的相关信息;
先讲一下方法思路,一共三个步骤;
方法思路
- 检查请求是否成功,这里需要在请求的时候包含(请求URL,请求表头,负载);
- 获取标签(提取数据);
- 写入翻页循环,并最终将所有提取的数据保存到CSV文件中;
对于POST请求来说,根据HTTP协议规范,POST请求主要用于向指定资源提交数据,以供处理(例如,提交表单、上传文件等)。因此,POST请求的主要组成部分是:
- 请求URL:定义了请求的目标资源,包括协议、域名、路径和查询参数;
- 请求标头:提供了关于请求本身的额外信息,如客户端的身份、接受的内容类型、缓存控制等,帮助服务器更好地理解和处理请求;
- 负载:包含了要发送给服务器的数据。它可以是任何形式的数据,只要客户端和服务器都同意如何解释这些数据。常见的格式包括JSON、XML、表单数据;
完整代码#运行环境 Python 3.11
import requests
import json
# 定义API URL
url = 'https://api.example.com/v1/data'
# 构建POST请求的有效负载
payload = {
"page": 1, # 当前页码
"pageSize": 10, # 每页大小
"tags": ["featured", "urgent"] # 数据标签
}
# 设置请求头
headers = {
'Accept': 'application/json',
'Authorization': 'Bearer YOUR_ACCESS_TOKEN', # 替换为实际的访问令牌
'Content-Type': 'application/json'
}
# 发送POST请求
response = requests.post(url, data=json.dumps(payload), headers=headers)
# 检查响应状态码
if response.status_code == 200:
data = response.json()
# 展示预览信息
print("预览信息:")
print(f" - 当前页码: {data.get('page', '未知')}")
print(f" - 每页条目数: {data.get('pageSize', '未知')}")
print(f" - 总条目数: {data.get('total', '未知')}")
print(f" - 可用标签: {payload.get('tags', [])}") # 或者从响应中提取标签信息
第一步部分:对于POST请求,找到有效的请求URL,请求表头,负载之后,接下来,就是获取数据的步骤,先打印是否响应和响应内容;
第二步部分:如果我们收到信息code = 200,意味着请求成功,接下来就可以开始分析响应内容,通过预览查看字段,识别出所有感兴趣的字段,确认每个字段的数据类型(字符串、数字、布尔值等),如果响应是嵌套的JSON对象或数组,注意其层次结构 ,有助于后续保存csv;
第三步部分:通过for 函数进行遍历,比如for page in range(1, total_pages + 1)将遍历多页数据,调用检查请求和提取数据的功能,并最终将所有提取的数据保存到CSV文件中;
就像上篇文章说的,无论是GET还是POST请求,它们仅仅是HTTP协议中的两种不同请求方法,所以在脚本的整体逻辑实现上其实除了在开始请求的有区别,其他的别无二致,当然为了避免频繁访问,可以引入time.sleep()来控制请求频率,以及使用代理池来分散请求源。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。


















 1581
1581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











