






AI本地化部署:C++运行超分增强图像
前言
文章中包含部分Python部分,你只要会安装Python环境即可,如果不想要了解Python,可以直接进入到编写C++代码部分,我已经提供了一个示例工程。
环境准备
- 安装onnxruntime和opencv:
pip install onnxruntime opencv-python
- 安装百度飞浆环境,我这里是一CPU推理为示例(详细可以参考官网安装:https://www.paddlepaddle.org.cn/install/quick ):
python -m pip install paddlepaddle==2.6.2 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/
- 按照官方教程安装准备PPGAN, 连接如下:
https://aistudio.baidu.com/projectdetail/3205183
模型转换
- 新建一个Python脚本,运行下面代码,导出模型为onnx:
from ppgan.models.generators import RRDBNet
import paddle
import paddle.static as static
def export_onnx():
# 加载百度飞浆的模型
model = RRDBNet(3, 3, 64, 23)
# 下载后的模型路径,注意按照实际更改
state_dict = paddle.load("weight_params/DF2K_JPEG.pdparams")
model.load_dict(state_dict)
# 为模型指定输入的形状和数据类型,支持持 Tensor 或 InputSpec ,InputSpec 支持动态的 shape。
x_spec = paddle.static.InputSpec([None, 3, None, None], 'float32', 'x')
# 指定导出的onnx的保存路径
model_path = "./onnx_net/rrdbnet"
# 导出onnx模型
paddle.onnx.export(model, model_path, input_spec=[x_spec], opset_version=11)
if __name__ == "__main__":
export_onnx()
- 执行完成后,你应该会指定的路径下面看到一个ONNX后缀的文件,我们可以通过下面代码验证一下:
import onnxruntime
def test():
ort_sess = onnxruntime.InferenceSession("onnx_net/rrdbnet.onnx")
in_img = Image.open("./test.png").convert("RGB")
x = norm(in_img)
x = np.expand_dims(x,axis=0).astype('float32')
print(x.shape)
print(ort_sess.get_inputs()[0])
ort_outs = ort_sess.run(None,{
"x":x
})
y = ort_outs[0]
out_img = Image.fromarray(denorm(y[0]))
out_img.save("./test_out.png")
使用ONNX模型
C++项目准备
-
新建一个Visual Studio空白控制台工程:
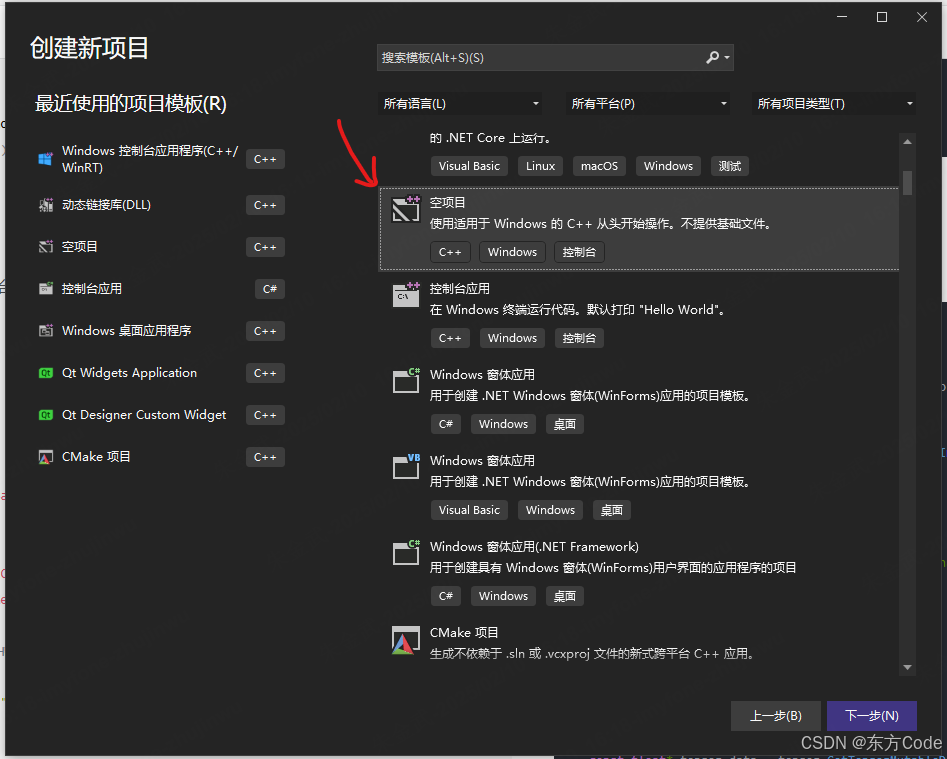
-
右键项目管理器的工程->管理NuGet程序包->搜索OnnxRuntime并下载
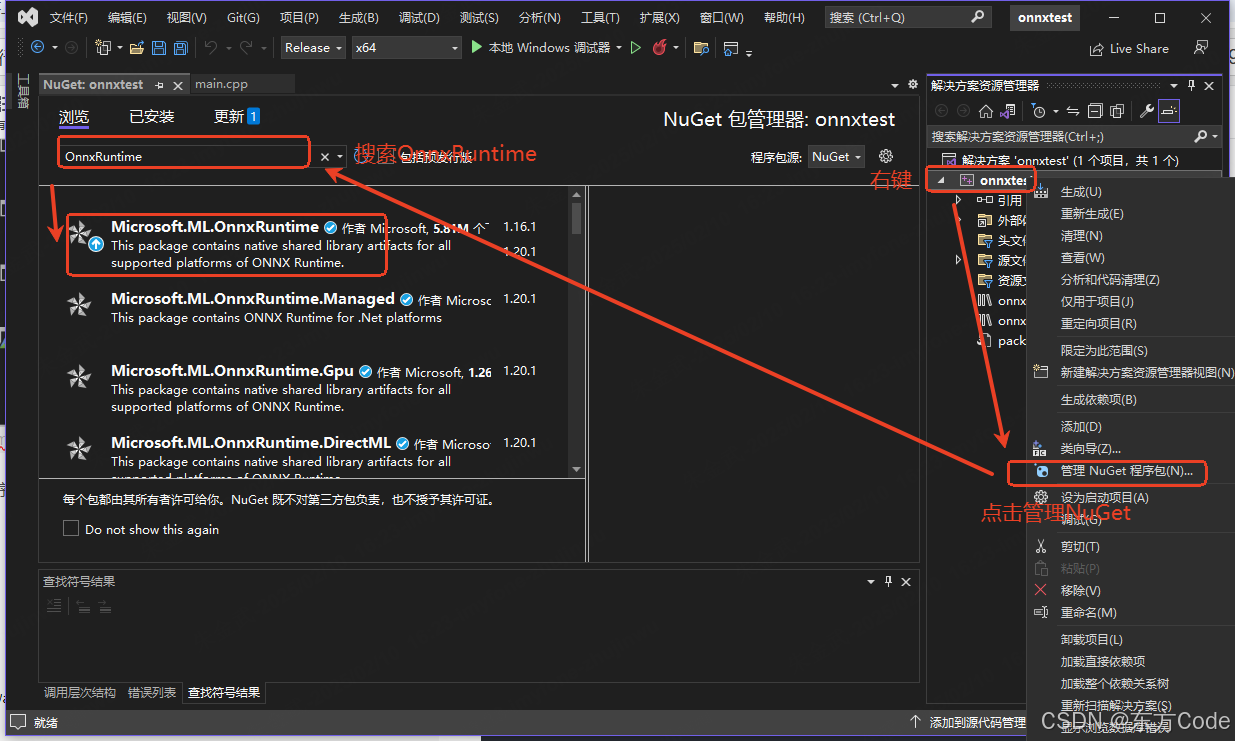
-
然后搜索OpenCV并下载
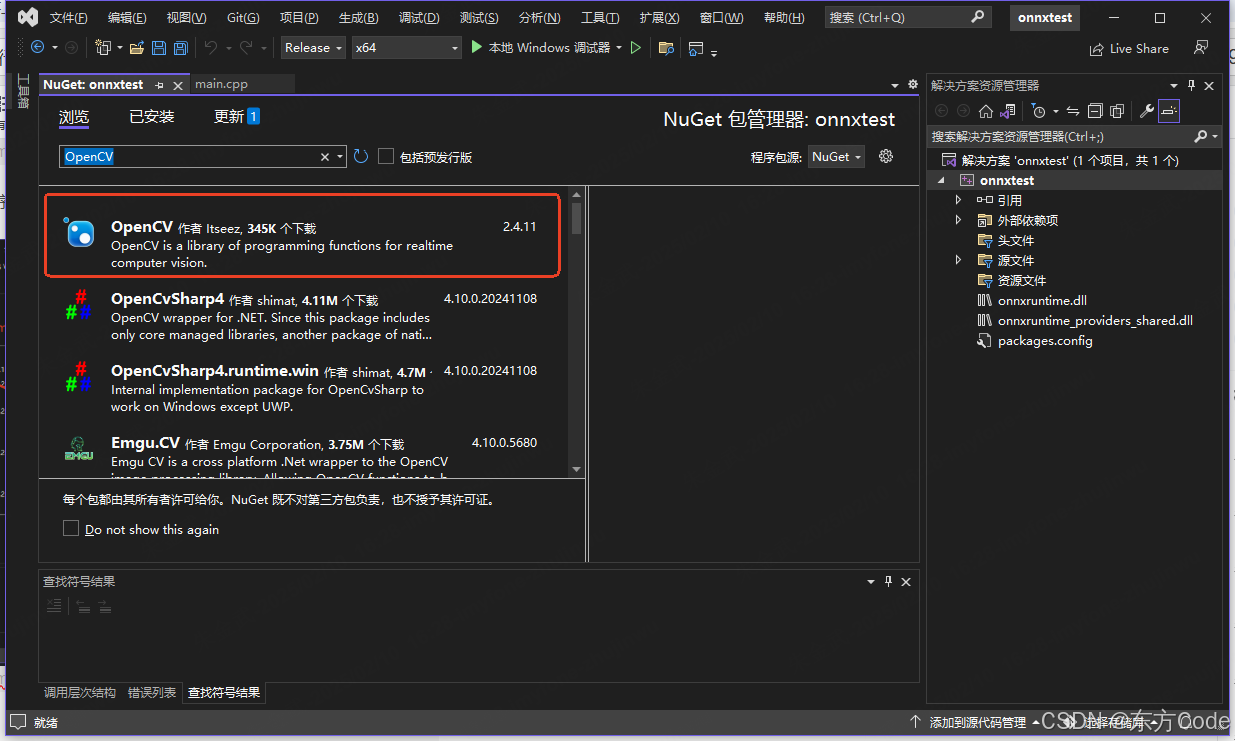
-
现在环境已经准备就绪了。
编写C++代码
示例工程可以直接从这里下载:
https://download.youkuaiyun.com/download/weixin_45809578/90364889
- 新建一个C++文件,粘贴如下代码:
#include <onnxruntime_cxx_api.h>
#include <opencv2/opencv.hpp>
void PrintTensorContent(Ort::Value& tensor)
{
// 获取张量类型和形状信息
auto type_and_shape = tensor.GetTensorTypeAndShapeInfo();
auto shape = type_and_shape.GetShape();
size_t total_size = type_and_shape.GetElementCount();
// 打印张量形状
std::cout << "Tensor Shape: [";
for (size_t i = 0; i < shape.size(); ++i) {
std::cout << shape[i];
if (i < shape.size() - 1) {
std::cout << ", ";
}
}
std::cout << "]\n";
// 获取张量数据指针并打印内容
const float* data = tensor.GetTensorMutableData<float>();
std::cout << "Tensor Content:\n";
for (size_t i = 0; i < total_size; ++i) {
std::cout << data[i] << " ";
if ((i + 1) % shape.back() == 0) { // 每行换行
std::cout << "\n";
}
if (i > 64) {
std::cout << "..." << std::endl;
break;
}
}
std::cout << std::endl;
}
std::vector<cv::Mat> TensorToMatBatch(Ort::Value& tensor)
{
// 获取张量类型和形状信息
auto type_and_shape = tensor.GetTensorTypeAndShapeInfo();
auto shape = type_and_shape.GetShape();
// 验证张量维度是否为 4D (NCHW)
if (shape.size() != 4) {
throw std::runtime_error("Unsupported tensor shape for conversion to cv::Mat. Expected 4D (N, C, H, W).");
}
size_t batch_size = shape[0]; // N
size_t channels = shape[1]; // C
size_t height = shape[2]; // H
size_t width = shape[3]; // W
// 获取张量数据指针
const float* tensor_data = tensor.GetTensorMutableData<float>();
std::vector<cv::Mat> result_images;
// 遍历每个图像批次
for (size_t n = 0; n < batch_size; n++) {
const float* batch_data = tensor_data + n * channels * height * width;
// 将批次数据转换为 cv::Mat
cv::Mat chw_mat(channels, height * width, CV_32F, const_cast<float*>(batch_data));
// 转换为 HWC 格式的 cv::Mat
std::vector<cv::Mat> channel_mats;
for (size_t c = 0; c < channels; ++c) {
cv::Mat channel(height, width, CV_32F, chw_mat.ptr<float>(c));
channel_mats.push_back(channel);
}
cv::Mat hwc_mat;
cv::merge(channel_mats, hwc_mat);
result_images.push_back(hwc_mat);
}
return result_images;
}
std::vector<cv::Mat> test(const std::vector<std::string>& image_paths,const ORTCHAR_T* model_path)
{
Ort::Env env(ORT_LOGGING_LEVEL_WARNING, "ONNXRuntimeExample");
// Create session options
Ort::SessionOptions session_options;
session_options.SetIntraOpNumThreads(4);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);
Ort::AllocatorWithDefaultOptions allocator;
//加载超分模型
//Ort::Session session(env, L"rrdbnet.onnx", session_options);
Ort::Session session(env, model_path, session_options);
std::string input_name = "";
std::string output_name = "";
//
//查询到输入输出的名称
for (size_t i = 0; i < session.GetInputCount(); i++)
{
auto name = session.GetInputNameAllocated(i, allocator);
input_name = name.get();
printf("input name: %s\n", input_name.c_str());
}
for (size_t i = 0; i < session.GetOutputCount(); i++)
{
auto name = session.GetOutputNameAllocated(i, allocator);
output_name = name.get();
printf("output name: %s\n", output_name.c_str());
}
std::vector<cv::Mat> images;
std::vector<float> batch_data;
int batch_size = image_paths.size();
for (const auto& path : image_paths) {
cv::Mat img = cv::imread(path, cv::IMREAD_COLOR);
if (img.empty()) {
std::cerr << "Failed to read image: " << path << std::endl;
continue;
}
img.convertTo(img, CV_32FC3);
img = img / 255.0f;
images.push_back(img);
// 将图像数据转换为 CHW 格式并追加到 batch_data
for (int c = 0; c < 3; c++) {
for (int h = 0; h < img.rows; h++) {
for (int w = 0; w < img.cols; w++) {
batch_data.push_back(img.at<cv::Vec3f>(h, w)[c]);
}
}
}
}
// 定义张量形状
std::vector<int64_t> shape = { batch_size, 3, images[0].rows, images[0].cols };
Ort::MemoryInfo memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(
memory_info, batch_data.data(), batch_data.size(), shape.data(), shape.size()
);
// 推理
const char* input_names[] = { input_name.c_str() };
const char* output_names[] = { output_name.c_str() };
std::chrono::system_clock::time_point start = std::chrono::system_clock::now();
auto output_tensors = session.Run(Ort::RunOptions{ nullptr }, input_names, &input_tensor, 1, output_names, 1);
std::chrono::system_clock::time_point end = std::chrono::system_clock::now();
std::cout << "inference time: " << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;
// 处理输出
std::vector<cv::Mat> output_mat_list = TensorToMatBatch(output_tensors[0]);
return output_mat_list;
}
int main()
{
std::vector<std::string> image_paths = {
"D:\\test\\1.jpg",
"D:\\test\\2.jpg",
"D:\\test\\3.jpg",
"D:\\test\\4.jpg"
};
// D:\\onnx_net\\rrdbnet.onnx 路径根据实际导出的位置更改
std::vector<cv::Mat> images = test(image_paths, L"D:\\onnx_net\\rrdbnet.onnx");
for (int i = 0; i < images.size(); i++)
{
auto& output_mat = images[i];
output_mat *= 255.0f;
output_mat.convertTo(output_mat, CV_8UC3);
cv::imshow("output", output_mat);
cv::waitKey(0);
std::string output_path = "D:/output_" + std::to_string(i) + ".png";
cv::imwrite(output_path, output_mat);
}
return 0;
}

















 3495
3495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









