









这篇文章用来接着介绍该音乐播放器的后端部分,因为涉及爬虫不知道会不会被限同时也为了阅读者不会觉得过于繁杂所以分开两篇发。这里是上一篇关于前端部分的介绍。
后端
这里使用的后端是由python的flask框架进行搭建的,数据是通过爪巴qq音乐进行获取的,接下来就浅析一下实现思路,以及实现过程。
分析
我的思路是登录之后对其进行抓包,对其中所需的元素进行筛选,赋值从而动态的获取其数据。说干就干!
我这演示的是随便找的歌曲。
获取歌曲地址
先找首能听的歌点击播放然后检查元素,像我这样

对内容进行分析一下可以发现这个请求就是可以获取歌曲播放音频地址的请求了。
而我们只需要拿到midurlinfo中的purl加上http头即为获取到音频地址

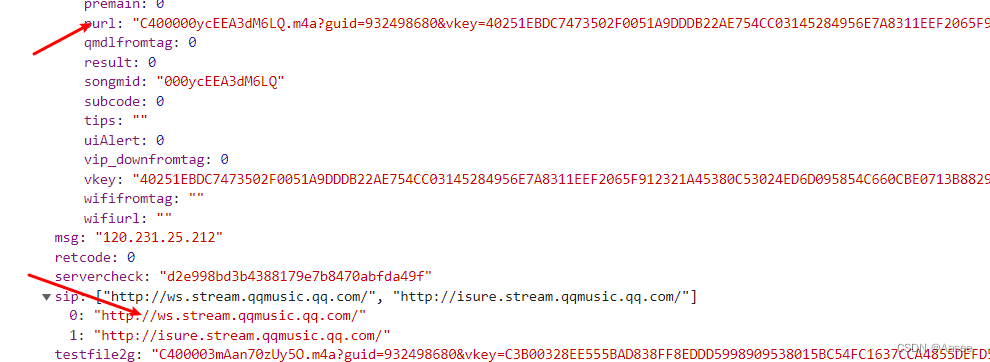
这样我们对其进行拼接一下就会发现可以播放了,而这些数据是怎么来的呢,让我们看回payload,就是所需参数的位置。(请确保你对前端有所了解!)
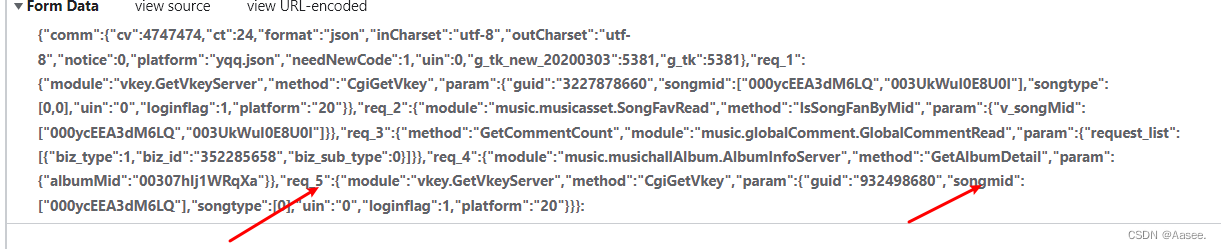
可以看到这里是由于传回了歌曲所需的mid所以才能拿到她所需要的音频地址。而其他参数则是作用不大,这里我已经验证过了,当然大家也可以自行尝试,至少对拿到音频地址来说其他要素是不重要的。
这时我们的需求就变成了怎么拿到这个mid,其实也很简单。抓包嘛,我们去搜索框一样检查元素然后抓取network变化,我以搜索“我们”为例
导库
import requests
import time
import base64
代码
这里url是我看了一下这篇文章发现可以直接get请求,这直接让我少干了很多逆向工程。
def get_full(self,mid):
headers = {
"authority": "u.y.qq.com",
"method": "GET",
"scheme": "https",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"cookie": 'pgv_pvid=6074896270; RK=DhRR3BNuGu; ptcz=e4e2a34b15b2d14e5f799a9994e6af4f8f926af30aec961b549f5559510856f7; tvfe_boss_uuid=045e9df33d0970e8; fqm_pvqid=827b2bc8-24fd-48bc-840f-049ec2e0f80d; fqm_sessionid=8fdc8a8c-3720-4bfa-a5b4-03755c6ee9f3; pgv_info=ssid=s6714276410; _qpsvr_localtk=0.4830583784858622; tmeLoginType=2; euin=oKCzoeCl7i4z7n**; _tc_unionid=702697cb-a27a-4f85-9a56-6743e2b43f37; ts_uid=3782629684; midas_openkey=80370324C861E7B2D7521C097A4C89F5; midas_openid=5C9866EEF90592E1F3BBD881E181AA03; ptui_loginuin=1600677504; ts_refer=i.y.qq.com/; login_type=1; psrf_access_token_expiresAt='+str(time.time())+'; wxopenid=; psrf_qqopenid=5C9866EEF90592E1F3BBD881E181AA03; qm_keyst=Q_H_L_5J91MGUHh60zipHRg9x3wIYjFLzrLrmi2WPpldBs34ysBOQ36VLSUXg; psrf_qqunionid=0420F54F469B6EE95618140CAF0208EE; uin=1600677504; wxrefresh_token=; qm_keyst=Q_H_L_5J91MGUHh60zipHRg9x3wIYjFLzrLrmi2WPpldBs34ysBOQ36VLSUXg; psrf_qqrefresh_token=FB5E3D2C371559A055C3050744AD1067; wxunionid=; psrf_musickey_createtime='+ str(time.time()) +'; psrf_qqaccess_token=80370324C861E7B2D7521C097A4C89F5; qqmusic_key=Q_H_L_5J91MGUHh60zipHRg9x3wIYjFLzrLrmi2WPpldBs34ysBOQ36VLSUXg; ts_last=y.qq.com/n/ryqq/songDetail/'+str(mid)+'',
"pragma": "no-cache",
"sec-ch-ua": '" Not A;Brand";v="99", "Chromium";v="100", "Google Chrome";v="100"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "Windows",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36",
}
url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?data={"comm":{"cv":4747474,"ct":24,"format":"json","inCharset":"utf-8","outCharset":"utf-8","notice":0,"platform":"yqq.json","needNewCode":1,"uin":1600677504,"g_tk_new_20200303":1745233772,"g_tk":1745233772},"req_1":{"method":"GetCommentCount","module":"GlobalComment.GlobalCommentReadServer","param":{"request_list":[{"biz_type":1,"biz_id":"330621483","biz_sub_type":0}]}},"req_2":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"9225513112","songmid":["'+ mid +'"],"songtype":[0],"uin":"1600677504","loginflag":1,"platform":"20"}}}'
res = requests.get(url=url, headers=headers)
headUrl = "http://ws.stream.qqmusic.qq.com/" # http://isure.stream.qqmusic.qq.com/
assUrl = res.json()['req_2']['data']['midurlinfo'][0]['purl']
# 拼接一下头和屁股就可以了
获取歌曲mid
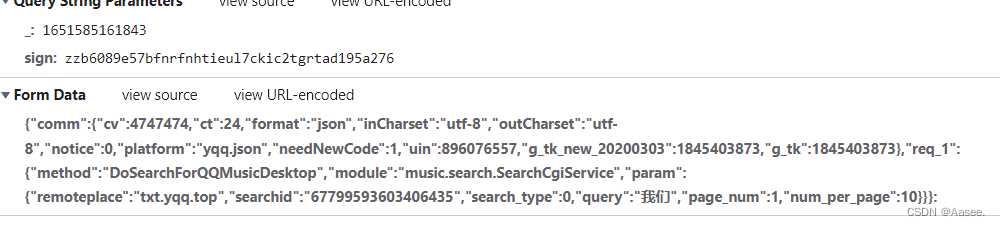
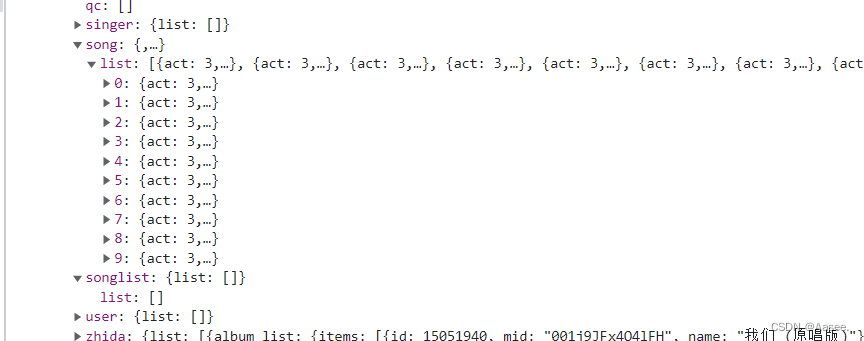
可以看到没错我们拿到了数据。但是pc网页端限制太多,所以我所在项目中抓取的是手机端的。使用的是fiddler,感兴趣的小伙伴也可以自己试试。
对比发现其实就是payload中的请求类型发生了变化只需将这个换成DoSearchForQQMusicMobile

这里就给大家看看手机端抓取的效果图吧
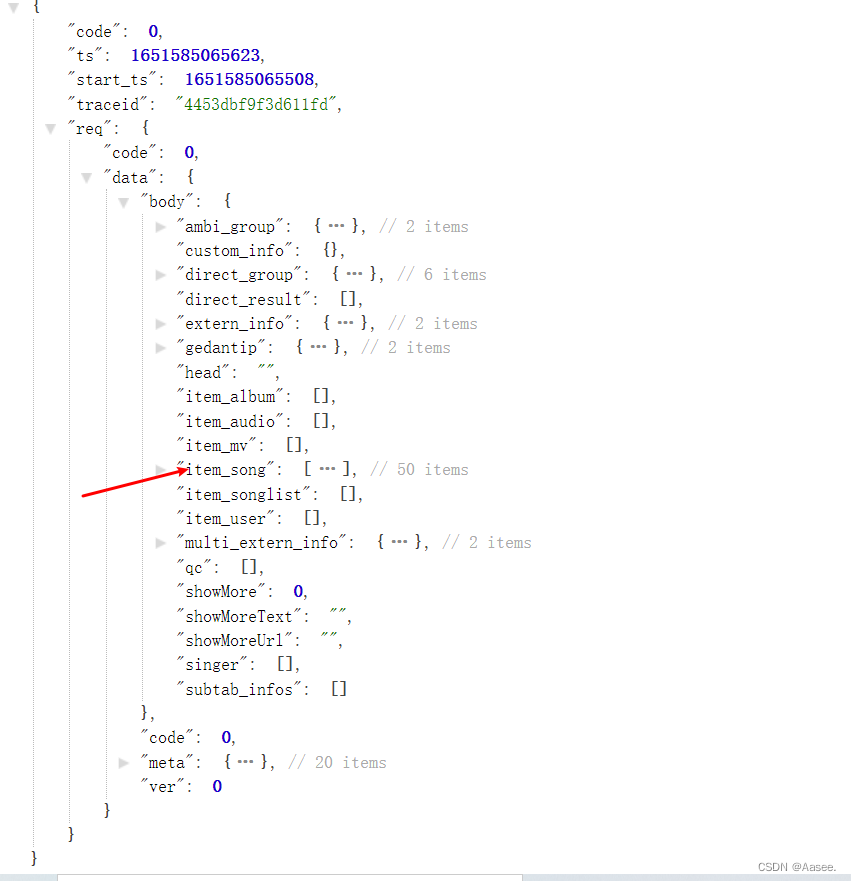
数据就在这里面,数据过多就不一一截图,这里我提取了里面的五个值,歌曲id(前端歌曲身份对比凭证),mid(歌曲地址获取必需要素),歌曲封面pid(album里的mid),音乐名(name),歌手名(sname)。
代码
def get_mid(self,query):
url1 = 'https://u.y.qq.com/cgi-bin/musicu.fcg?data={"comm":{"ct":"1","cv":"10180005","vG":"10180005"},"req":{"method":"DoSearchForQQMusicMobile","module":"music.search.SearchBrokerCgiServer","param":{"search_type":0,"query":"'+query+'","page_num":1,"num_per_page":90,"grp":0}}}'
res = requests.get(url=url1, headers=self.headers)
# print(res.text)
list_song = res.json()['req']['data']['body']['item_song']
author = []
for i in range(len(list_song)):
mydict = {
'pid': res.json()['req']['data']['body']['item_song'][i]['album']['mid'][1:],
'id': res.json()['req']['data']['body']['item_song'][i]['id'],
'mid': res.json()['req']['data']['body']['item_song'][i]['mid'],
'name': res.json()['req']['data']['body']['item_song'][i]['name'],
'sname': res.json()['req']['data']['body']['item_song'][i]['singer'][0]['name'],
}
author.append(mydict)
print(author)
获取评论
老样子找到评论按f12检查一下,观察network。
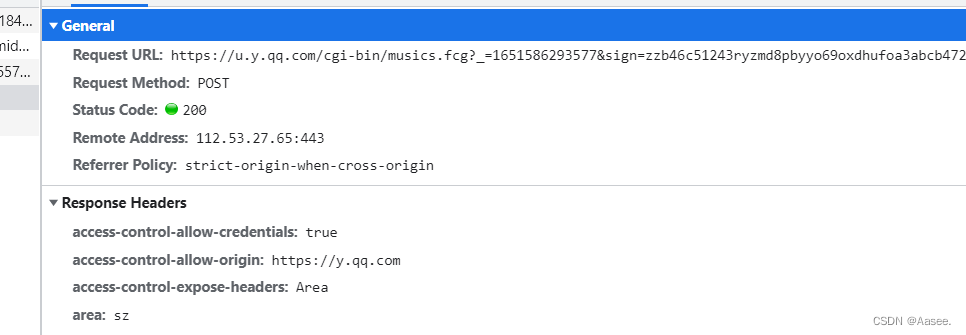
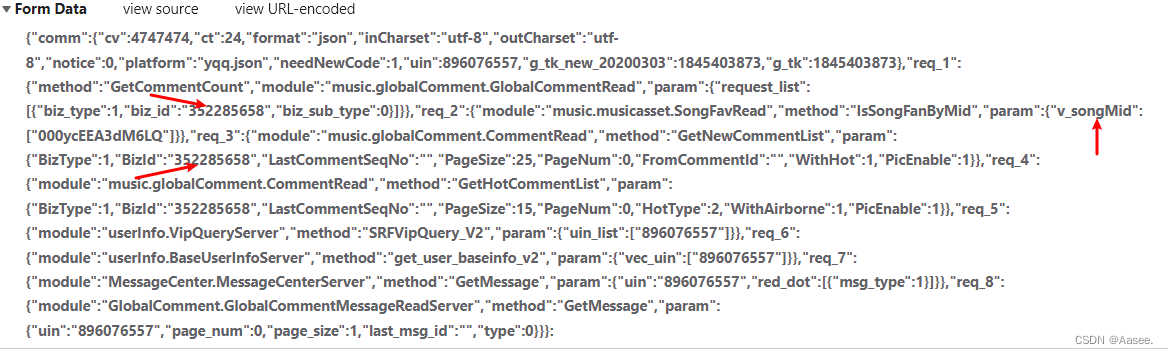
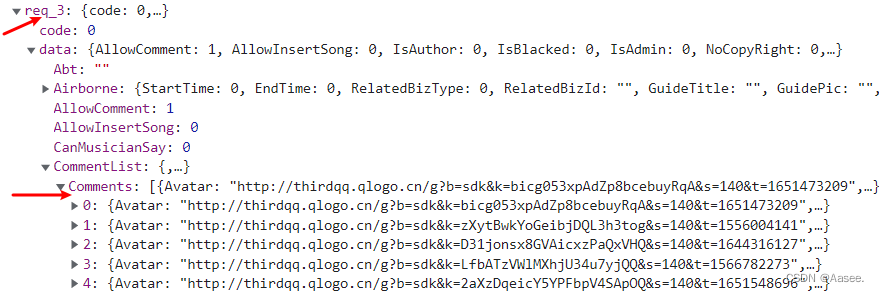
这里我们可以看到里面就是我们所需的数据,而我们这里也需要两个参数,id和mid只要加进去就行了。然后对里面的数据进行切割一下就可以拿到想要的数据了。
代码
def get_comment(self,id, mid):
url = 'https://u.y.qq.com/cgi-bin/musicu.fcg?data={"comm":{"cv":4747474,"ct":24,"format":"json","inCharset":"utf-8","outCharset":"utf-8","notice":0,"platform":"yqq.json","needNewCode":1,"uin":0,"g_tk_new_20200303":406404725,"g_tk":406404725},"req_1":{"method":"GetCommentCount","module":"GlobalComment.GlobalCommentReadServer","param":{"request_list":[{"biz_type":1,"biz_id":"' + id + '","biz_sub_type":0}]}},"req_2":{"module":"music.musicasset.SongFavRead","method":"IsSongFanByMid","param":{"v_songMid":["' + mid + '"]}},"req_3":{"module":"music.globalComment.CommentReadServer","method":"GetNewCommentList","param":{"BizType":1,"BizId":"' + id + '","LastCommentSeqNo":"","PageSize":25,"PageNum":0,"FromCommentId":"","WithHot":1}},"req_4":{"module":"music.globalComment.CommentReadServer","method":"GetHotCommentList","param":{"BizType":1,"BizId":"' + id + '","LastCommentSeqNo":"","PageSize":15,"PageNum":0,"HotType":2,"WithAirborne":1}}}'
res = requests.get(url=url, headers=self.headers)
list_comment = res.json()['req_3']['data']['CommentList2']['Comments']
message = []
for i in range(0, len(list_comment)):
mydict = {
'Avatar': res.json()['req_3']['data']['CommentList2']['Comments'][i]['Avatar'],
'Nick': res.json()['req_3']['data']['CommentList2']['Comments'][i]['Nick'],
'Content': str(res.json()['req_3']['data']['CommentList2']['Comments'][i]['Content']).replace('{br}', '\n'),
'SubComments': res.json()['req_3']['data']['CommentList2']['Comments'][i]['SubComments'],
message.append(mydict)
print(message)
获取歌词
相信英语那么好的你,应该一眼就知道这是干嘛的了吧


这里我们也只需要id和mid,但是歌词和翻译都是进行了base64加密的所以不能直接使用,但是解密也是很简单。
代码
def get_lyric(self,id,mid):
url = 'https://c.y.qq.com/lyric/fcgi-bin/fcg_query_lyric_new.fcg?_=1649322181315&cv=4747474&ct=24&format=json&inCharset=utf-8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=1&uin=0&g_tk_new_20200303=1745233772&g_tk=1745233772&loginUin=0&songmid='+mid+'&musicid='+id+''
res = requests.get(url, headers=self.headerss)
lyric_f = res.json()['lyric']
lyric = base64.b64decode(lyric_f)
print(lyric.decode('utf-8'))
总结
这样我们就基本完成了后端的逻辑处理操作了。分析之后你会发现其实这些都并不难。这就是我这个音乐播放器后端部分的基础实现过程。全部源码有点太多太繁杂就不一一展示,对源码有兴趣或者也想要这个音乐播放器的可以私信我。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











