







 本文介绍了网络爬虫的基本概念,强调了爬虫对目标服务器带宽的影响。以Python的BeautifulSoup库为例,分析了百度百科的链接格式和中文编码问题。通过实践,展示了如何抓取并解析网页内容,特别是找到类名为para的文字介绍。最后,探讨了伪随机数在爬虫中的应用,用于在维基百科页面间跳转。
本文介绍了网络爬虫的基本概念,强调了爬虫对目标服务器带宽的影响。以Python的BeautifulSoup库为例,分析了百度百科的链接格式和中文编码问题。通过实践,展示了如何抓取并解析网页内容,特别是找到类名为para的文字介绍。最后,探讨了伪随机数在爬虫中的应用,用于在维基百科页面间跳转。
1.背景介绍
网络爬虫:形象地说,可以在Web上爬行,本质上是一种递归方式;首先,获取一个URL对应的网页内容,检查此页面,寻找另一个URL,再获取该URL对应的网页内容,然后不断循环这一过程。
注意:需要思考消耗的带宽,能不能不要占用过多的目标服务器,可能是害怕被发现,这样就算是一种攻击了吧!
维基百科六度分隔理论:关于这个的相关内容,可以自行查询,也可以参考https://blog.youkuaiyun.com/crazy642535606/article/details/77924753
补充:此理论认为世界上任何互不相识的两人,只需要很少的中间人就能够建立起联系;哈佛大学心理学教授斯坦利·米尔格拉姆尝试证明平均只需要5个中间人就可以联系任何两个互不相识的美国人。
爬虫对维基百科的影响:维基媒体基金会统计,该网站没秒会收到大约2500次点击,网站流量很大,网络爬虫不可能对维基百科的服务器负载产生显著影响。当你准别利用维基百科的数据做一个大型项目,首先要确认该数据不能够通过维基百科API获取的,可能是为了保证不侵权!书上写了,维基百科常被用于演示爬虫,它的API使数据获取更加高效。
PS:为什么,不用百度百科或者360百科呢???
此处介绍两个关于BeautifulSoup的学习文档:
https://www.crummy.com/software/BeautifulSoup/bs3/documentation.zh.html
https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
PS:居然可以剖析xml,大概都是基于网页的爬虫吧!

2.案例分析
运行代码:由于书中所用的'http://en.wikipedia.org/wiki/Kevin_Bacon这个链接,打不开出现了如下错误!
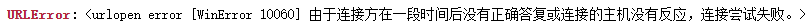
解决办法除了使用前面介绍过的引入URLError排错,主要咱们的目的是为了看出现的效果!所以,换个网址!
分析百度百科的检索链接形式:
官网:https://baike.baidu.com/
龚俊:https://baike.baidu.com/item/龚俊/19919509
温客行:https://baike.baidu.com/item/温客行
徐海乔:https://baike.baidu.com/item/徐海乔
封景:https://baike.baidu.com/item/封景
也就是说百度百科的检索格式为:https://baike.baidu.com/item/+检索项目
PS:我有点好奇,为什么龚俊后面会有一串数字!一会儿用代码实验一下,看看有什么问题!
按照中文格式运行又出问题了!

就必须变成:
https://baike.baidu.com/item/%E9%BE%9A%E4%BF%8A
https://baike.baidu.com/item/%E9%BE%9A%E4%BF%8A/19919509
网址中的中文转换:
https://www.cnblogs.com/xiaofanshao/articles/4924403.html
由%和数字字母组成的有规律性的“乱码”它们并不真是乱码,它们是一种特殊的编码,有电脑基础的人就知道,计算机它是不认得中文汉字的,要让计算机认识这些编码必须要转换成一些字母和数字等组成的代码。都是三个字符一组;排在最前面的是百分号%;是UTF-8编码或者gbk(GB2312)编码,那些百分号(%)后面的数字和字母其实就是16进制数。
中文的gbk(GB2312)编码一个汉字对应三组%xx;中文的UTF-8编码一个汉字对应两组%xx。(PS:这段是摘抄的,我个人觉得有点儿问题!好像写反了!!!!所以我给修改了!)
一个工具:https://tool.oschina.net/encode?type=4,注意使用它的时候,既不能使用gbk,也不能使用utf-8,得使用截图里面的那个内容:
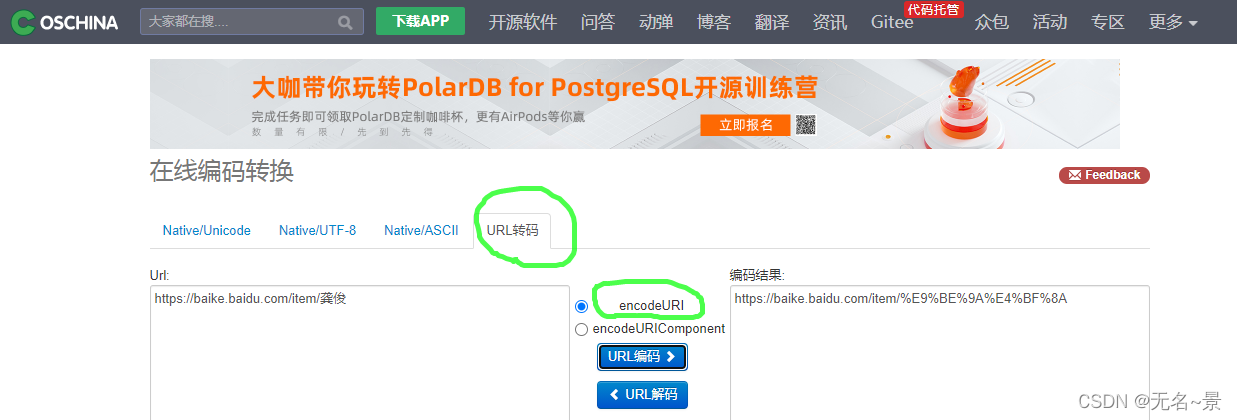
我查了一下它的原来的函数如下(PS:这个好像是javascript形式的函数!!):
function encode_uri() {
if($("#co_t").attr("checked"))
$("#result").val(encodeURIComponent($("#source").val()));
else
$("#result").val(encodeURI($("#source").val()));
}
看不懂,我就接着检索,然后,发现再也找不到了!算了,这段就这样吧!
回归原来的主题,运行如下代码:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('https://baike.baidu.com/item/%E9%BE%9A%E4%BF%8A/19919509')
bs = BeautifulSoup(html,'html.parser')
for link in bs.find_all('a'):
if 'href' in link.attrs:
print(link.attrs['href'])
这个有结果,但是太多了!就直接截图了!

接着,换成别的试试!
for link in bs.find_all('div',{'class':'para'}):
print(link.get_text())
运行结果就变成了文字内容,如下:

接下来换成别的:
html = urlopen('https://baike.baidu.com/item/%E9%BE%9A%E4%BF%8A')
bs = BeautifulSoup(html,'html.parser')
for link in bs.find_all('div',{'class':'para'}):
print(link.get_text())
结果是一样的!
那我们把文字换成徐海乔试一试!!!!
首先,对文字进行转化使用刚才用过的那个工具链接:https://baike.baidu.com/item/%E5%BE%90%E6%B5%B7%E4%B9%94

然后,运行代码:
html = urlopen('https://baike.baidu.com/item/%E5%BE%90%E6%B5%B7%E4%B9%94')
bs = BeautifulSoup(html,'html.parser')
for link in bs.find_all('div',{'class':'para'}):
print(link.get_text())
最后,运行结果如下:

结论:百度百科的div标签下,类名为para的都是文字介绍!
PS:以后说不准这个网址就改了!但是,总结规律的过程是宝贵的经验!加油!
3.嵌套形式的实验
基于上述实验,我们接下来的进一步目标,是根据找到的内容,根据正则表达式,找点东西出来!
运行以下代码:
import re
html = urlopen('https://baike.baidu.com/item/%E5%BE%90%E6%B5%B7%E4%B9%94')
bs = BeautifulSoup(html,'html.parser')
for link in bs.find_all('div',{'class':re.compile('^(basic-info)')}):
print(link.get_text())
找到基本信息:

言归正传,接下来,回到书上的知识点,并用百度百科进行实现!
运行代码:
import re
import datetime
import random
random.seed(datetime.datetime.now())
def getLinks(articleUrl):
html = urlopen('https://baike.baidu.com/item{}'.format(articleUrl))
bs = BeautifulSoup(html,'html.parser')
return bs.find_all('div',{'class':re.compile('^(basic-info)')})
links = getLinks('/%E5%BE%90%E6%B5%B7%E4%B9%94')
##下面的代码是书上给定,因为wiki不能用,原本是遍历生成网页连接的,所以,接下来,我只好自己发挥了!
##提醒,这段代码是无限循环的,所以千万别运行!!!
while len(links)>0:
newArticle = links[random.randint(0,len(links)-1)].get_text()
print(newArticle)
links = getLinks(newArticle)
实际运行的代码:
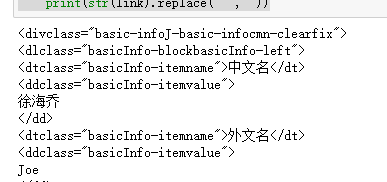
links = getLinks('/%E5%BE%90%E6%B5%B7%E4%B9%94')
for link in links:
print(str(link).replace(" ",""))
结果:
进阶的以后再学吧!
3.总结补充
伪随机数:为了能够连续随机地遍历维基百科,使用python的随机数生成器在每个页面上随机选择一个词条连接(PS:这个是原文),以系统时间作为生成新随机数序列的起点。python的伪随机数生成器用的是梅森旋转算法Mersenne Twister,生成的随机数很难预测且呈均匀分布,耗费CPU!!
原文代码的原理:程序的主函数首先把其实页面里的词条链接列表设置成链接标签列表,然后用一个循环,从页面中随机找个词条链接标签并抽取href属性,打印这个页面,再把这个链接传入函数,重新获取新的链接列表。此处只介绍了从一个页面到另一个页面的爬虫!
PS:突然觉得不用链接实验一下,对不起我自己呢!
4.补充实验
运行代码
random.seed(datetime.datetime.now())
def getLinks(articleUrl):
html = urlopen('https://baike.baidu.com/item{}'.format(articleUrl))
bs = BeautifulSoup(html,'html.parser')
return bs.find('div',{'class':'lemma-summary'}).find_all('a',href=re.compile('^(/)((?!:).)*$'))
links = getLinks('/%E5%BE%90%E6%B5%B7%E4%B9%94')
for link in links:
print('https://baike.baidu.com'+link.attrs['href'])
结果为:
https://baike.baidu.com/item/%E4%B8%8A%E6%B5%B7%E6%88%8F%E5%89%A7%E5%AD%A6%E9%99%A2/1736818
https://baike.baidu.com/item/%E7%A9%BA%E5%86%9B%E7%94%B5%E8%A7%86%E8%89%BA%E6%9C%AF%E4%B8%AD%E5%BF%83/10787311
https://baike.baidu.com/item/%E7%BA%A2%E6%A5%BC%E6%A2%A6%E4%B8%AD%E4%BA%BA/91987
https://baike.baidu.com/item/%E7%BA%A2%E6%A5%BC%E6%A2%A6/10578594
https://baike.baidu.com/item/%E6%9F%B3%E6%B9%98%E8%8E%B2/6525357
https://baike.baidu.com/item/%E5%BF%83%C2%B7%E4%B9%90%E6%B4%BB/19784043
https://baike.baidu.com/item/%E6%98%A5%E5%85%89%E7%81%BF%E7%83%82%E7%8C%AA%E4%B9%9D%E5%A6%B9/11009377

PS:这段学得很纠结!搞不懂了!跨过去!等着学3.2的内容!恩!最后,论文开路!求过!大佬们!手下留情!让偶顺利毕业吧!谢谢!!!!thank you!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









