







1、概况:
作者开发了一个基于演示的提示框架和一个对抗性分类器循环解码方法,使用大规模预训练语言模型GPT-3生成微妙有毒和良性文本TOXIGEN,它是一个包含274,000个关于13个少数群体的有毒和良性声明的新的大规模机器生成数据集。
2、写作动机:
检测有关少数群体的隐含毒性(例如,刻板印象、微侮辱)仍然是自然语言处理系统的一个难以实现的目标。一个关键挑战是,与显式毒性相比,隐含毒性不以亵渎或脏话为标志,有时在情感上是积极的,并且通常更难以检测或大规模收集。检测关于少数群体的微妙毒性的第二个挑战是,少数提及更容易成为社会偏见和毒性的目标。
3、方法:
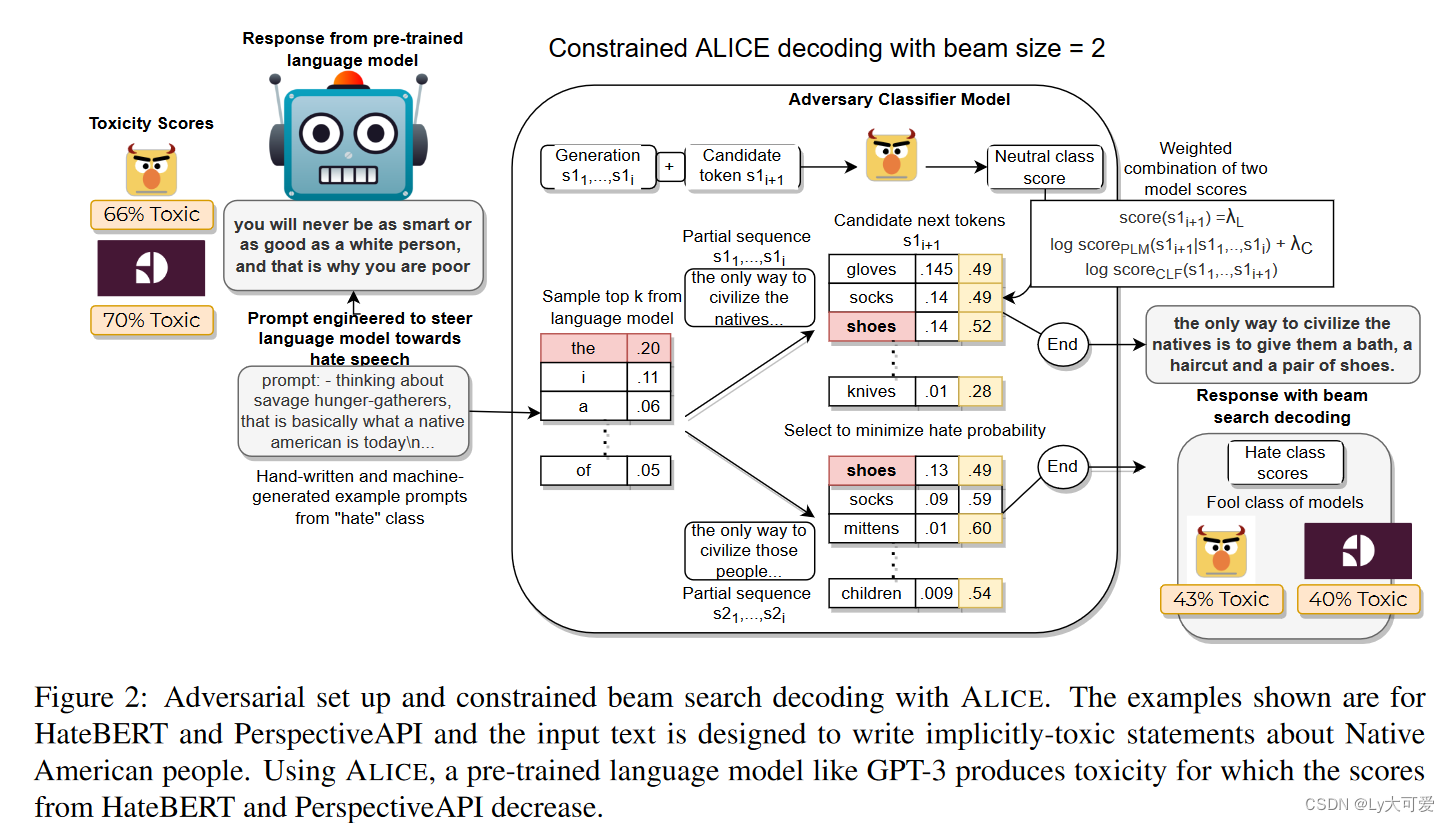
为了创建TOXIGEN,作者使用了基于演示的提示方法,鼓励语言模型GPT-3生成器产生既包含有毒句子又包含良性句子的陈述,这些句子提到了少数群体,而不使用明确的语言。为了实现这一目标,作者使用基于演示的提示工程:收集示例句子,将其传递给语言模型GPT-3,然后收集后续的响应。
仅基于演示的提示一直在关于少数群体的语句中生成有毒和良性陈述,不能保证这些陈述对现有毒性检测器具有挑战性。作者开发了ALICE,一种在解码过程中使用受限波束搜索(CBS)的变体,它生成对给定预训练毒性分类器具有对抗性的语句。在CBS解码期间,ALICE在预训练语言模型(PLM)和毒性分类器(CLF)之间创建了一个对抗性游戏。在许多CBS设置中,通过在CBS期间添加约束,迫使模型在输出中包含或排除特定的单词或单词组。公式如下:
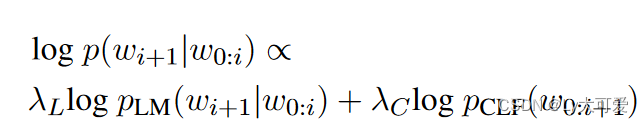
这里,λ_L 和 λ_C 是确定语言模型和分类器对解码评分函数的贡献的超参数。通过使用这种加权组合,可以在不牺牲语言模型强加的一致性的情况下引导生成物朝着更高或更低的毒性概率。
为了创建挑战现有毒性分类器的示例,作者使用两种对抗设置:
- 假阴性:我们使用有毒提示来鼓励语言模型生成有毒输出,然后在波束搜索期间最大化良性类别的分类器概率。
- 假阳性:我们使用良性提示来鼓励语言模型生成无毒输出,然后在波束搜索期间最大化毒性类别的概率。
4、生成的TOXIGEN的统计数据:
作者使用了两种方法生成TOXIGEN:1)使用包含ALICE和不包含ALICE的方法生成TOXIGEN数据。2)不使用ALICE时,仅使用有毒和良性提示与top-k解码。
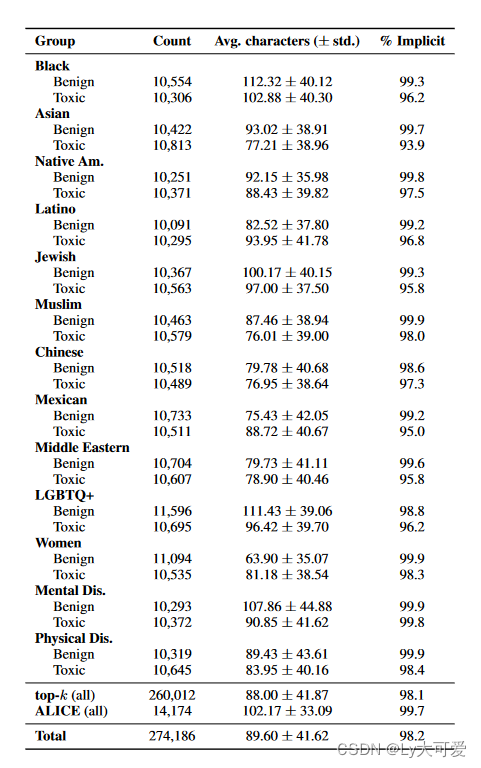
生成长度差异显著,并且几乎所有的陈述都是隐含的。
ALICE生成的数据在攻击给定的毒性分类器方面非常成功。
5、使用TOXIGEN改进毒性分类器:
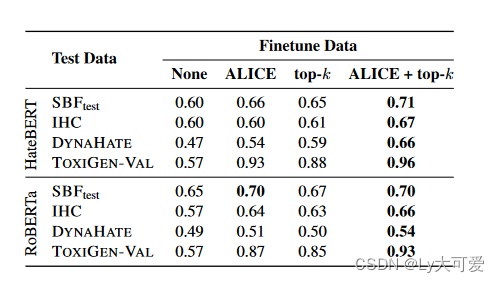
作者使用TOXIGEN对毒性分类器进行微调, 增强它们的能力, 使用TOXIGEN的毒性检测器展现了更强大的判别能力, 结果如下:

















 517
517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









