







分享一篇以LLM为核心的多模态语言模型工作LLaVA,仅仅通过在CLIP和Vicuna间使用一个线性投射层连接的方式完成多模态聊天。
论文题目:Visual Instruction Tuning
来源:NeurIPS2023/威斯康星大学麦迪逊分校
方向:LLM、MLLM
开源地址:https://github.com/haotian-liu/LLaVA
摘要
使用机器生成的指令遵循数据对大型语言模型(LLM)进行指令微调已被证明可以提高新任务的零样本能力,但这种思想在多模态领域的探索较少。我们首次尝试仅使用GPT-4的语言模型来生成多模态语言-图像指令跟随数据。通过利用这些生成的数据进行指令微调,我们引入了LLaVA:大型语言和视觉助手(Large Language and Vision Assistant),这是一个端到端训练的大型多模态模型(LMM Large Multimodal Models**)**,它连接了视觉编码器和LLM,用于通用的视觉和语言理解。
为了便于未来对视觉指令遵循的研究,我们构建了两个具有挑战性的面向应用任务的评估基准。我们的实验表明,LLaVA显示出令人印象深刻的多模态聊天能力,有时在没看过的图像/指令上表现出堪比多模态GPT-4的行为,在混合多模态指令跟随数据集上,得分相当于GPT-4的85.1%。当对科学QA进行微调时,LLaVA和GPT-4的协同作用达到了92.53%的最先进的准确率。我们开源了GPT-4生成的视觉指令微调数据、模型和代码。
GPT辅助的视觉指令数据生成
大量图像-标题对易获取,比如CC和LAION,但是指令遵循数据较少
给定一个图像-标题对 (𝑋𝑣,𝑋𝑐) ,最简单的构造指令数据方式为,先提示GPT4得到一系列的问题 𝑋𝑞 ,之后就可以组成指令遵循数据: 𝐻𝑢𝑚𝑎𝑛:𝑋𝑞𝑋𝑣<𝑆𝑇𝑂𝑃>𝐴𝑠𝑠𝑖𝑠𝑡𝑎𝑛𝑡:𝑋𝑐<𝑆𝑇𝑂𝑃> ,尽管很简单,但是这种方式不管是指令还是回复都缺乏多样性和推理深度。这种方式称为简单扩展方式
为了解决这两个问题,我们使用了GPT4和ChatGPT中的语言模型作为强大的教师。为了将图像转换为可以用于提示GPT的纯文本,我们使用了两种符号表示:
- 从不同方面描述图像的标题。
- Bounding Box,包含每个box的坐标以及相应的概念文本。
利用这些符号表示,我们使用COCO的图像生成了三种类型的指令遵循数据,如下图所示。对每种类型,我们首先人工设计了一些样例作为种子样例来提示GPT-4,以下是三种类型:
- 对话(Conversation)。我们设计了一个AI助手和一个问关于这张图像的人之间的对话。答案的语气就好像AI助手看到了图像并回答问题。本文对每张图像的视觉内容提出了一组不同的问题,包括对象类型、对象计数、对象动作、对象位置、对象之间的相对位置,最终只考虑有明确答案的问题。
- 详细描述(Detailed Description)。为了为每张图像引入丰富且全面的描述,我们利用GPT4创建了一个问题列表,对每张图像,我们随机从问题列表中选取一个问题提示GPT4生成详细的描述。
- 复杂推理(Complex Reasoning)。这种问题的答案需要符合逻辑的一步一步的推理流程

我们创建了158K不同的语言-图像指令遵循数据,包含58K的对话,23K的详细描述,77K的复杂推理。早期实验中,本文同时使用了ChatGPT和GPT4,同时发现GPT4能够一致地提供更高质量的指令遵循数据,比如空间推理。
视觉指令微调
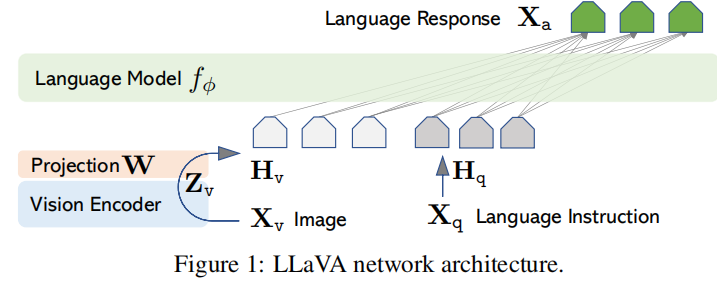
架构
本文使用Vicuna作为LLM 解码器,因为它在公开模型中取得了最好的指令遵循能力。CLIP ViT-L/14作为视觉编码器。本文使用了一个简单的线性层来将图像特征转换到词语编码空间,从而可以将转换后的视觉表征token序列与问题的文本token序列拼接起来,输入语言模型得到回复。
训练
为每张图像,我们构建了多轮对话数据 (𝑋𝑞1,𝑋𝑎1…,𝑋𝑞𝑇,𝑋𝑎𝑇) ,具体每一轮的query构建方式如下,第一轮包含了图像和问题文本(token顺序随机),之后每一轮仅包含问题文本。
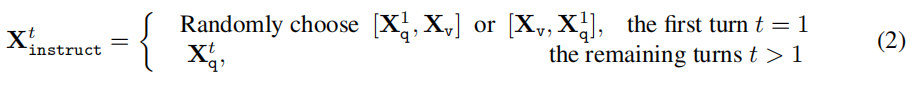
我们使用自回归训练目标来进行指令微调:
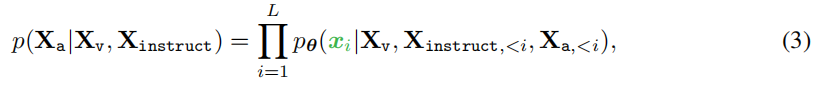
具体来说是如下的指令序列格式:

本文提出了两阶段指令微调策略:
- 阶段1:特征对齐预训练(Pre-training for Feature Alignment):从CC3M中过滤出595K条图文对,使用简单扩展方式得到相应的简单指令微调数据。利用这些数据,冻住LLM和CLIP,只训练投射层,从而将转换后的视觉特征与LLM的词编码对齐。(注意,这里的预训练和普通LLM的预训练差异还是很大的,本质上其实是单轮对话数据微调。
- 阶段2:端到端微调(Fine-tuning End-to-End):冻住CLIP,训练投射层和LLM,本文考虑了两种具体使用场景:
- 多模态聊天机器人:使用158K指令数据进行微调,其中对话数据为多轮,其他两种数据为单轮,均匀采样进行训练。
- 科学问答:在ScienceQA基准上微调。
实验
所有模型都使用8张A100进行训练,和Vicuna超参保持一致。我们在过滤后的CC-595K子集上对模型预训练1个epoch,学习率为2e-3,批大小为128。并对提出的LLaVA-Instruct-158K数据集进行微调3个epoch,学习率为2e-5,批大小为32。
多模态聊天机器人
以下展示了一个demo,LLaVA对于没见过的图像仍然展现出比三个LMM更好的回答效果

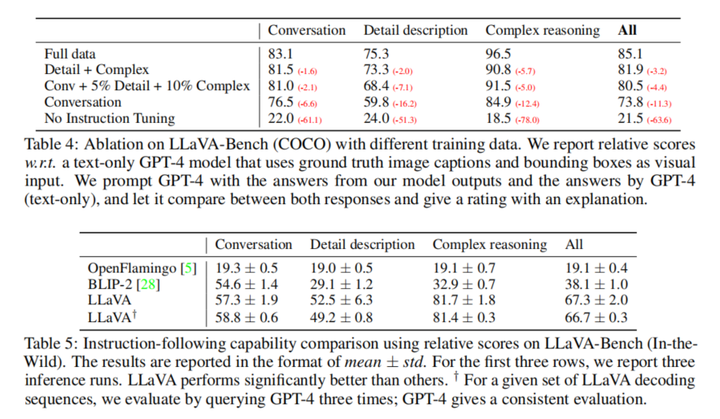
在两个评估基准上,使用GPT4对回复进行自动评估,使用所有数据进行微调的LLaVA都取得了领先效果。LLaVA-Bench (COCO)从COCO-Val-2014中构建,LLaVA-Bench (In-the-Wild)从各种类型图像中构建。
局限性
- 部分视觉问题可能需要检索增强辅助回答(无法准确回复某道菜对应的餐馆)
- 有时LLaVA会简单把图像token序列简单看成bag of patches,无法捕捉到复杂语义(无法区分“草莓味酸奶”和“草莓和酸奶”)

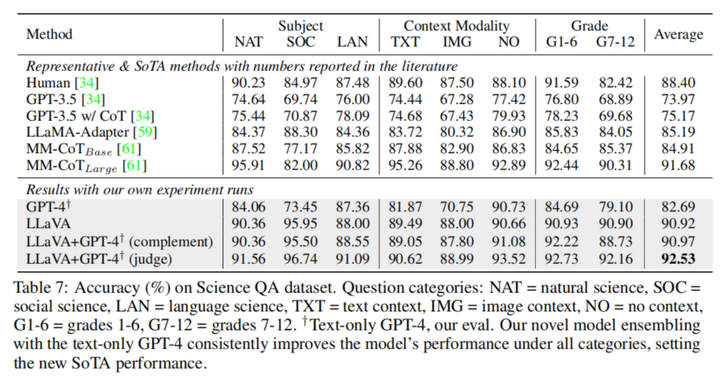
科学问答
LLaVA自身表现良好,结合GPT4可以互相取长补短。此外有趣的是,不依赖于图像的GPT4语言模型本身已经可以获得很好的效果。
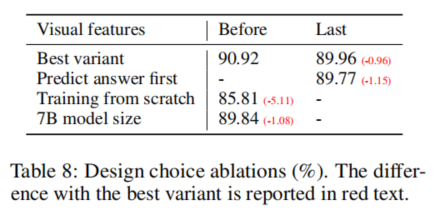
科学问答消融实验
- 视觉特征:使用CLIP的倒数第二层的表征比最后一层的表征表现更好,这可能与CLIP最后一层更关注全局特征以及抽象属性有关,而倒数第二层则可以更多地关注局部特征,对于具体的图像细节更有用。
- 思维链:类似CoT的先推理的提示策略,收敛速度快,但不能提升太多性能。
- 预训练:跳过预训练直接微调,发现效果会变差。
- 模型大小:模型越大效果越好。
大家好,我是NLP研究者BrownSearch,如果你觉得本文对你有帮助的话,不妨点赞或收藏支持我的创作,您的正反馈是我持续更新的动力!如果想了解更多LLM/检索的知识,记得关注我!

















 44
44

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









