







Training data-efficient image transformers & distillation through attention
论文链接:https://export.arxiv.org/pdf/2012.12877
代码:https://github.com/facebookresearch/deit
摘要
纯基于注意力的神经网络被证明可以解决图像分类等图像理解任务,但是这些高性能的网络结构通常需要使用大型的基础设施预先训练了数亿个图像,因此限制了他们的采用。
为此,对于这种设计庞大的预训练量,作者提出了一种convolution-free transformers的结构,只在Imagenet上进行训练,就具有竞争力。在不需要其他额外数据进行预训练的情况下,在ImageNet上达到了top-1 accuracy 达到83.1%的效果。
此外,作者还引入了teacher-student策略,依赖于一个蒸馏标记(distillation token),确保学生通过注意力从老师那里学习。当卷积网络作为teacher时,效果达到了85.2%的准确率
DeiT能取得更好效果的方法:
- better hyperparameter更好的超参数设置(模型初始化,learning-rate等设置),
- data augmentation(多种数据增强方式)
- distillation(知识蒸馏)
Introduction
ViT的问题:
- ViT需要大量的GPU资源
- ViT的预训练数据集JFT-300M并没有公开
- 超参数设置不好很容易导致训练效果差
- 只用ImageNet训练准确率没有很好
对于VIT训练数据巨大,超参数难设置导致训练效果不好的问题,提出了DeiT。
DeiT : Data-efficient image Transformers
DeiT的模型和VIT的模型几乎是相同的,可以理解为本质上是在训一个VIT。
DeiT特点:
- DeiT不包含卷积层,可以在没有外部数据的情况下实现与ImageNet上的最新技术相媲美的结果。
- 引入了一种基于distillation token的新蒸馏过程,它扮演着与class token相同的角色,只不过它的目的是学习教师网络中的预测结果,两个标记都通过注意力在转换器中交互。
- 通过蒸馏,图像transformers从一个convnet学到的比从另一个性能相当的transformers学到的更多。
- 在Imagenet上预先学习的模型在转移到不同的下游任务时是有竞争力的
Related work
Knowledge Distillation 知识蒸馏
参考资料:(58条消息) 深度学习之知识蒸馏(Knowledge Distillation)_AndyJ的学习之旅-优快云博客_知识蒸馏温度
简单来说就是用teacher模型去训练student模型,通常teacher模型更大而且已经训练好了,student模型是我们当前需要训练的模型。在这个过程中,teacher模型是不训练的。
软蒸馏 soft distillation
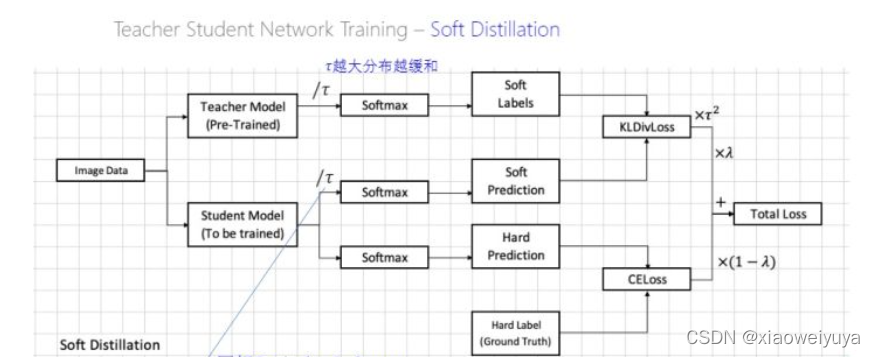
当teacher模型和student模型拿到相同的图片时,都进行各自的前向,这时teacher模型就拿到了具有分类信息的feature,在进行softmax之前先除以一个参数 ,叫做temperature(蒸馏温度),然后softmax得到soft labels(区别于one-hot形式的hard-label)。
student模型也是除以同一个 ,然后softmax得到一个soft-prediction,我们希望student模型的soft-prediction和teacher模型的soft labels尽量接近,使用KLDivLoss进行两者之间的差距度量,计算一个对应的损失teacher loss。
在训练的时候,我们是可以拿的到训练图片的真实的ground truth(hard label)的,可以看到上面图中student模型下面一路,就是预测结果和真是标签之间计算交叉熵crossentropy。
交叉熵:损失函数|交叉熵损失函数 - 知乎 (zhihu.com)
然后两路计算的损失:KLDivLoss和CELoss,按照一个加权关系计算得到一个总损失total loss,反向修改参数的时候这个teacher模型是不做训练的,只依据total loss训练student模型。
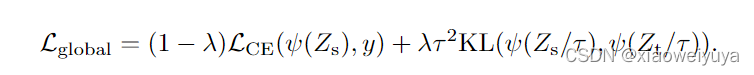
其中表示的是教师网络的输出概率,
表示学生网络的输出概率,
表示蒸馏温度,λ表示Kullback-Leibler散度损失与交叉熵损失之间的权重因子,y表示真实标签,ψ表示softmax函数
公式很容易可以理解,loss为学生网络与真实标签的损失加上学生网络输出值与教师网络输出值的标签分布差异。一方面希望学生网络的输出值与真实标签相近,同时还希望其与教师网络的输出分布相近,这样才可以学习到教师网络对某些错误数据与正确数据的相识情况。
硬蒸馏 hard diatillation
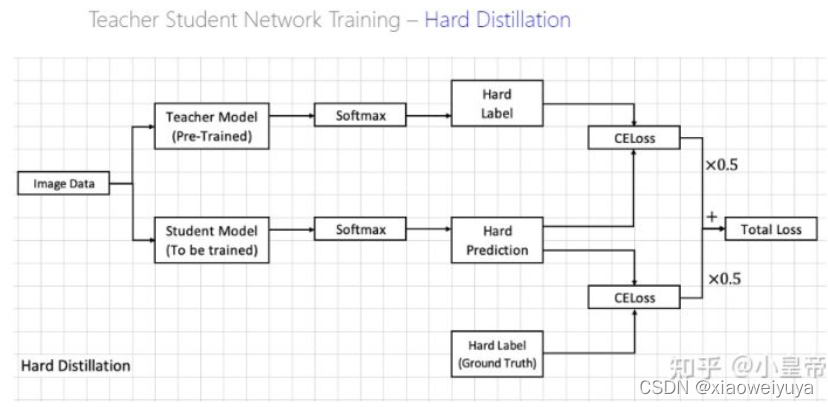
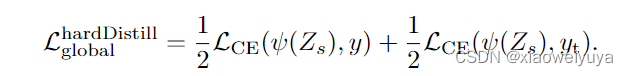
其中:,一方面使得学生网络与真实标签的损失最小,同时也希望与教师网络得出来的标签损失最小,这两个损失各占一半的权重。
对于给定的图像,与教师相关的硬标签可能会根据具体的数据增强而改变,而这种选择比传统的选择更好,教师预测与真实labely扮演相同的角色。还要注意,硬标签也可以通过标签平滑转换为软标签。
软蒸馏是限制student和teacher的模型输出类别分布尽可能接近,而硬蒸馏是限制两种模型输出的类别标签尽可能接近。
KLDivloss
KL散度,又叫相对熵,用于衡量两个分布(连续分布和离散分布)之间的距离,在knowledge distillation中,两个分布为teacher模型和student模型的softmax输出。

当两个分布很相近时候,对应class的预测值就会很接近,取log之后的差值就会很小,KL散度就很小。当两个分布完全一致时候,KL散度就等于0。
transformer中加入蒸馏——distillation token
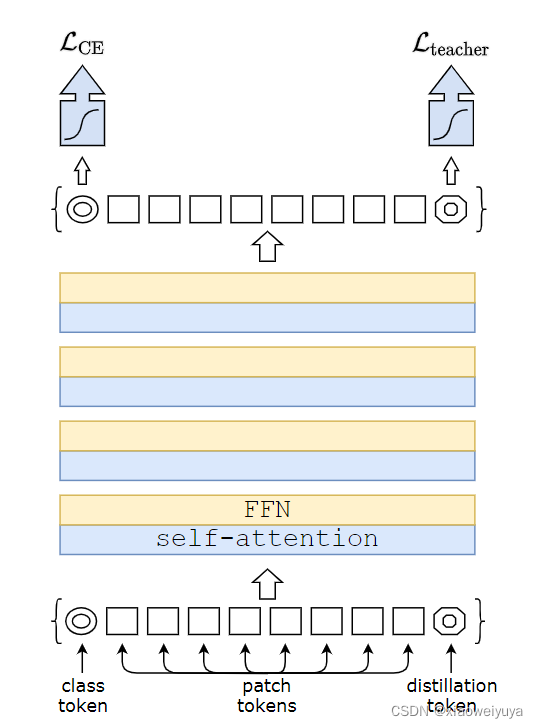
在VIT中时使用class tokens去做分类的,相当于是一个额外的patch,这个patch去学习和别的patch之间的关系,然后连classifier,计算CELoss。在DeiT中为了做蒸馏,又额外加一个distill token,这个distill token也是去学和其他tokens之间的关系,然后连接teacher model计算KLDivLoss,那CELoss和KLDivLoss共同加权组合成一个新的loss取指导student model训练(知识蒸馏中teacher model不训练)。
在预测阶段,class token和distill token分别产生一个结果,然后将其加权(分别0.5),再加在一起,得到最终的结果做预测。
在patches中加入与class token类似的distillation token,两者的通过网络时的计算方式相同,区别在于class token目标是重现ground truth标签,而distillation token目标是重现教师模型的预测,Distillation token让模型从教师模型输出中学习,文章发现:
- 最初class token和distillation token区别很大,余弦相似度为0.06
- 随着class 和 distillation embedding互相传播和学习,通过网络逐渐变得相似,到最后一层,余弦相似度为0.93,相似但不相同
- 当用一个class token替换distillation token时,两个class token输出的余弦相似度为0.999,网络性能与一个class token相近,而加入distillation token的网络性能明显提升。这表明distillation token的设定是有效的。
Experiments
DeiT不同参数
定义了与ViT-B参数相同的DeiT-B模型,和更小的DeiT-S、DeiT-Ti模型,区别在于heads数目和embedding dimension不同。超参数如下:

teacher模型的选择
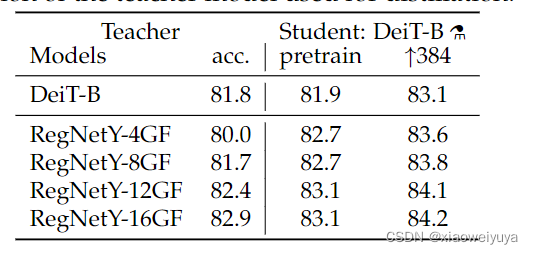
实验发现RegNetY-16GF是效果最好的教师模型,后续实验默认选择。
CNN效果更好,这可能是因为transformer可以学到CNN的归纳假设。CNN是有inductive bias的,例如局部感受野,参数共享等,这些设计比较适应于图像任务,这里将CNN作为teacher,可以通过蒸馏,使得Transformer学习得到CNN的inductive bias,从而提升Transformer对图像任务的处理能力。
同时还可以发现,学生网络可以取得超越老师的性能,能够在准确率和吞吐量权衡方面做的更好。
m小标表示使用了蒸馏策略的网络模型。↑384表示student在224*224图像上进行预训练,然后在384*384图像上进行fine-tune。
蒸馏策略的选择
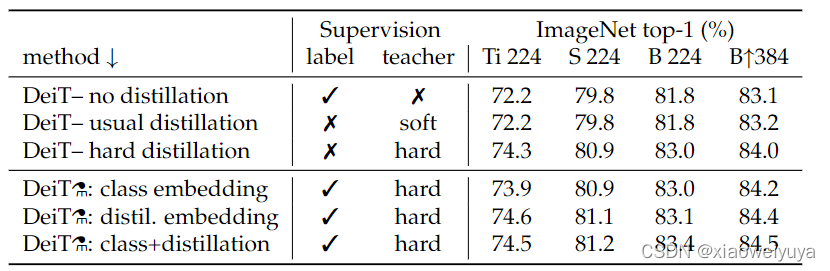
硬蒸馏的性能比软蒸馏更好。
在pretrain上测试的时候,distillation token和class token两个一起用性能更佳,这表明两个token提供了对分类有用的互补信息。只用一个的时候,distillation token性能略好于class token,这可能是因为distillation token里有更多从CNN中学到的归纳假设
与其他模型性能对比
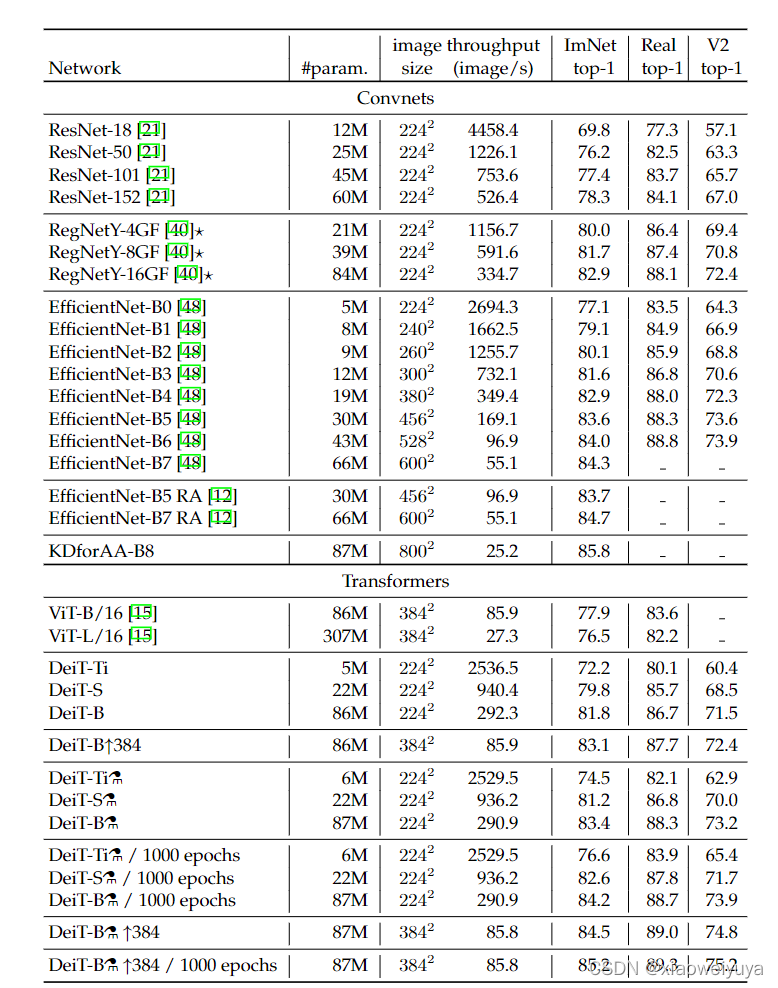
训练策略和消融实验
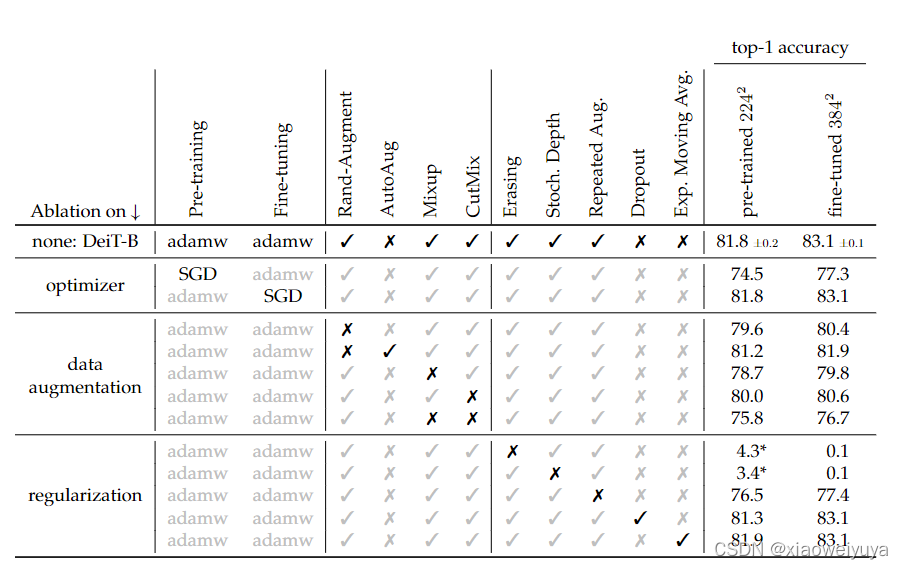
初始化和超参数
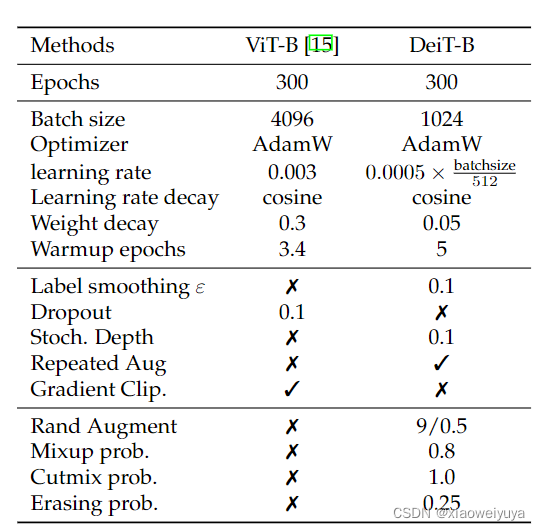
参数初始化方式:truncated normal distribution(截断标准分布)
soft蒸馏参数:= 3 ,
= 0.1

















 2111
2111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









