






本周需要解决的几个小问题:
1、人体体温的总体均值是否为98.6华氏度?
2、人体的温度是否服从正态分布?
3、人体体温中存在的异常数据是哪些?
4、男女体温是否存在明显差异?
5、体温与心率间的相关性(强?弱?中等?)
import pandas as pd
import numpy as np
import os
from scipy import stats
os.chdir('F://Desktop//统计学第二期//第十周,第十一周')
data = pd.read_csv('xxx')
'''
Gender:性别,1为男性,2为女性 ;Temperature:体温;HeartRate:心率;
'''
#数据探索
data.Temperature.describe()
# 1、人体体温的总体均值是否为98.6华氏度?
#mean 98.249231
# 2、人体的温度是否服从正态分布?
ks_test = stats.kstest(data['Temperature'], 'norm')
print('ks_test:',ks_test)
'''scipy.stats.kstest(K-S检验)
原假设:数据符合正态分布
输入数据,检验方法norm 正态分布
输出结果中第一个为统计量,
第二个为P值(注:统计量越接近0就越表明数据和标准正态分布拟合的越好,
如果P值大于显著性水平,通常是0.05,接受原假设,则判断样本的总体服从正态分布)
'''
#ks_test: KstestResult(statistic=1.0, pvalue=0.0)
#不是正态分布
mean = data.Temperature.mean()
std = data.Temperature.std()
print('均值为:%.2f,标准差为:%.2f' % (mean,std))
print('------')
# 计算均值,标准差
data_2 = data.Temperature
data_3=data_2.sort_values() # 重新排序
print(data_3.head())
data_3 = data_3.reset_index(drop = False) # 重新排序后,更新index
del data_3['index']
import matplotlib.pyplot as plt
fig = plt.figure(figsize = (10,6))
ax1 = fig.add_subplot(2,1,1) # 创建子图1
ax1.scatter(data_2.index, data_2.values)
plt.grid()
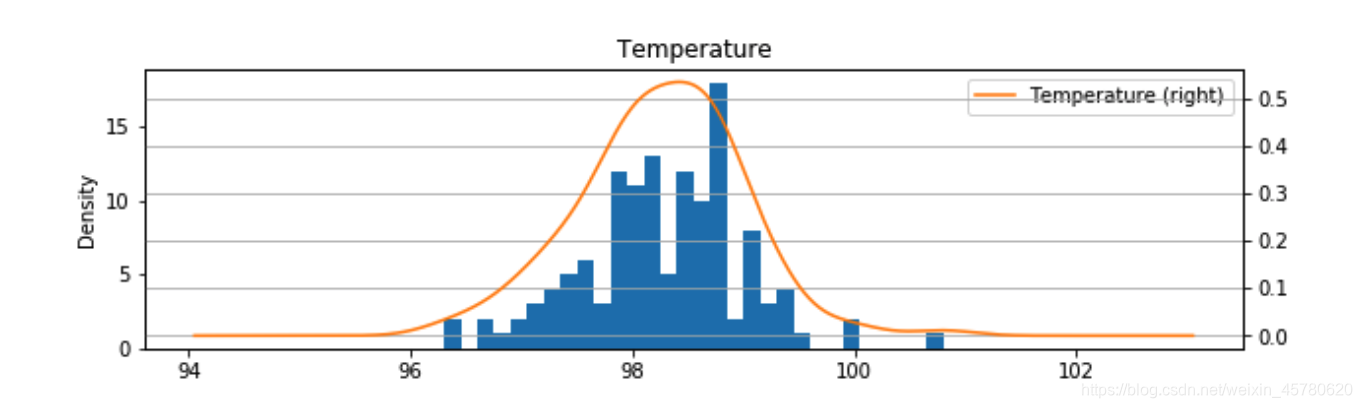
# 绘制数据分布图
#data_3.hist(alpha = 0.5)不同颜色
fig = plt.figure(figsize = (10,6))
ax2 = fig.add_subplot(2,1,2) # 创建子图2
data_3.hist(bins=30,ax = ax2)
#bins : integer or array_like, optional 这个参数指定bin(箱子)的个数
#这个例子中也就是横轴的数据个数
data_3.plot(kind = 'kde', secondary_y=True,ax = ax2)
plt.grid()
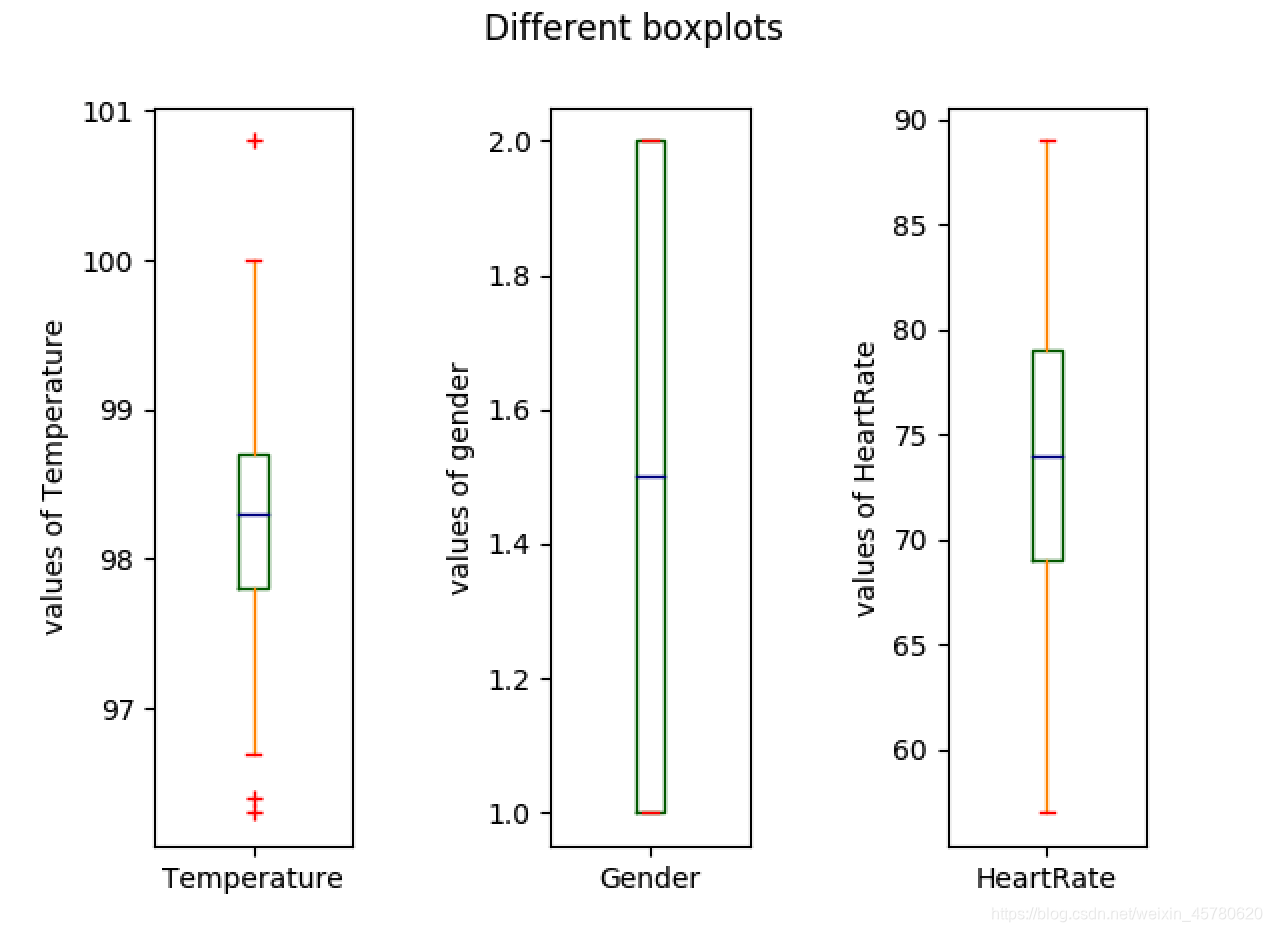
#3、人体体温中存在的异常数据是哪些?
# 箱线图看异常值
fig,axes = plt.subplots(1,3)
color = dict(boxes='DarkGreen', whiskers='DarkOrange',
medians='DarkBlue', caps='Red')
# boxes表示箱体,whisker表示触须线
# medians表示中位数,caps表示最大与最小值界限
data.plot(kind='box',ax=axes,subplots=True,title='Different boxplots',color=color,sym='r+')
# sym参数表示异常值标记的方式
axes[0].set_ylabel('values of Temperature')
axes[1].set_ylabel('values of gender')
axes[2].set_ylabel('values of HeartRate')
fig.subplots_adjust(wspace=1,hspace=1) # 调整子图之间的间距
fig.savefig('p2.png') # 将绘制的图片保存为p2.png
#4、男女体温是否存在明显差异?
data.boxplot(column='Temperature',by='Gender')
#5、体温与心率间的相关性(强?弱?中等?)
a = [random.randint(0, 100) for a in range(20)]
b = [random.randint(0, 100) for a in range(20)]
col_n = ['Temperature','HeartRate']
ab = pd.DataFrame(data,columns = col_n)
计算相关系数
ab.corr()
Temperature HeartRate
Temperature 1.000000 0.253656
HeartRate 0.253656 1.000000
#计算协方差
print(data.Temperature.cov(data.HeartRate))
1.3133810375670798
弱相关


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









