










摘要
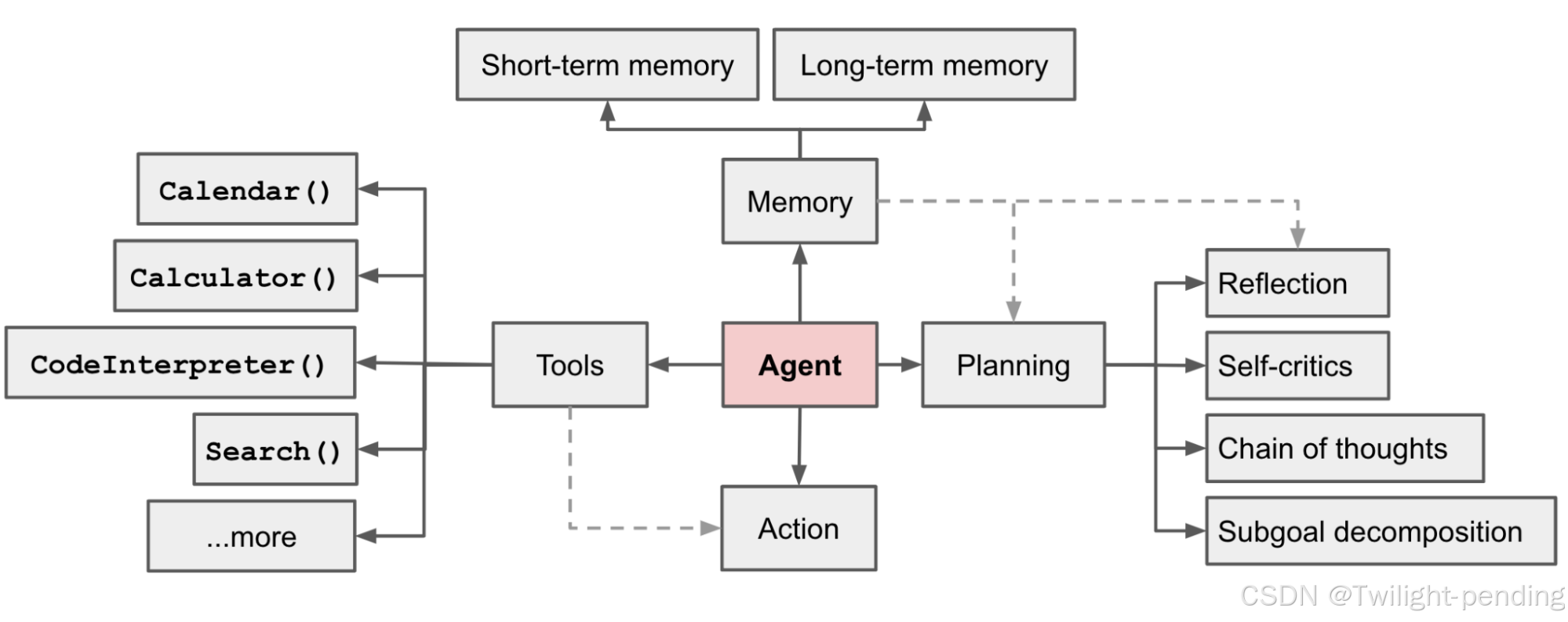
大型语言模型(LLM)作为自主代理的核心控制器是一个创新概念。LLM驱动的自主代理系统(ai agent)主要包含三个关键组件:
- 规划(包括任务分解和自我反思)
- 记忆(包括短期和长期记忆)
- 工具使用能力。
这种系统通过LLM的推理能力,结合外部工具和记忆系统,可以完成复杂的认知任务。但当前这类系统仍面临上下文长度有限、长期规划困难、自然语言接口可靠性等挑战。
要点
- LLM作为代理系统的"大脑",需要规划、记忆和工具使用三个关键组件的支持
- 规划组件包括任务分解和自我反思,可以将复杂任务分解为可管理的子目标
- 记忆系统分为短期记忆(上下文学习)和长期记忆(外部向量存储)
- 工具使用能力使LLM可以调用外部API和服务来扩展其功能
- 目前已有多个概念验证系统,如AutoGPT和GPT-Engineer等
- 系统需要处理格式解析和错误处理等工程挑战
- 当前主要限制包括有限的上下文长度、长期规划能力不足等问题
有效地整合外部工具和知识库来增强LLM代理的能力
提升LLM代理对外部工具和知识库的综合利用能力,核心在于为模型提供明确的“调用方式”和“调用时机”,并辅以高效的检索与上下文管理机制。以下几点是实践过程中常见的关键做法:
- 工具的可调用接口与规范化输出
- 以自然语言对话的方式向LLM提供工具的功能、输入/输出格式,帮助模型清楚地理解何时应调用某个工具,以及应该生成怎样的参数。像Toolformer或ChatGPT Plugins使用显式标注或函数描述,让LLM在生成回答时“插入”相应的工具调用。
- 确保对LLM返回结果进行解析,以处理可能的格式化错误或“幻觉”输出。这通常通过在代理层写解析代码、检查返回JSON格式等方式增强稳定性。
- 知识库检索与长程记忆
- 结合向量数据库(如FAISS、HNSW、ScaNN等)可以让代理快速检索到相关文档或以往记录,从而在有限的上下文窗口外获取更多信息。
- 通过将大文本分段索引,把检索到的匹配内容注入到提示中,就能缓解“上下文窗口限制”,但仍要注意分块后对话结构的合理性,避免噪声信息影响模型判断。
- 规划与反馈回路
- 在工具调用前明确拆分复杂任务为子任务,LLM需要知道任务目标和可用工具清单,以便“先计划,再调用”。
- 借助自我反思(Reflection),LLM对先前步骤的输出进行检查,在必要时纠正或重新调用工具。这样能保证对话在多轮协作中不断提高准确度和鲁棒性。
- 框架与扩展实践
- 在HuggingGPT或ChemCrow等具体系统中,模型不仅需要“知道有多少工具”,还需掌握工具何时可用、何时需要跨工具协作。通过选模组件或Plan-Select-Execute的多阶段流程,代理可以自主挑选和组合不同工具或模型推理结果。
- 对于专业领域(如科学研究、金融分析),可配置一批专门API或模型(如药物分析、分子合成工具)扩展LLM在垂直场景的能力,并以专家评审或测试集合对生成结果做质量把关,从而保证最终输出的可信度。
参考
https://lilianweng.github.io/posts/2023-06-23-agent/
https://kns.cnki.net/nzkhtml/xmlRead/trialRead.html?dbCode=CJFD&tableName=CJFDTOTAL&fileName=DSJD202312002&fileSourceType=1&invoice=kjrZD%2fC7xcvOyXDA2%2bOtzODGT3YPmoc6pffyvVQBmeHw%2f9OVUQHYyMiznkM1Nj4vkeJq2MW5FjGwdpfNg2pZxfwzOdvU88CrujWbxfiuxUFT9XkjU%2b7rNBOydRt5llcUcJ82q2m0JtNGaAghoHCGjpI4pAjUkr43XDdzCoGjzDU%3d&appId=KNS_BASIC_PSMC


















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









