







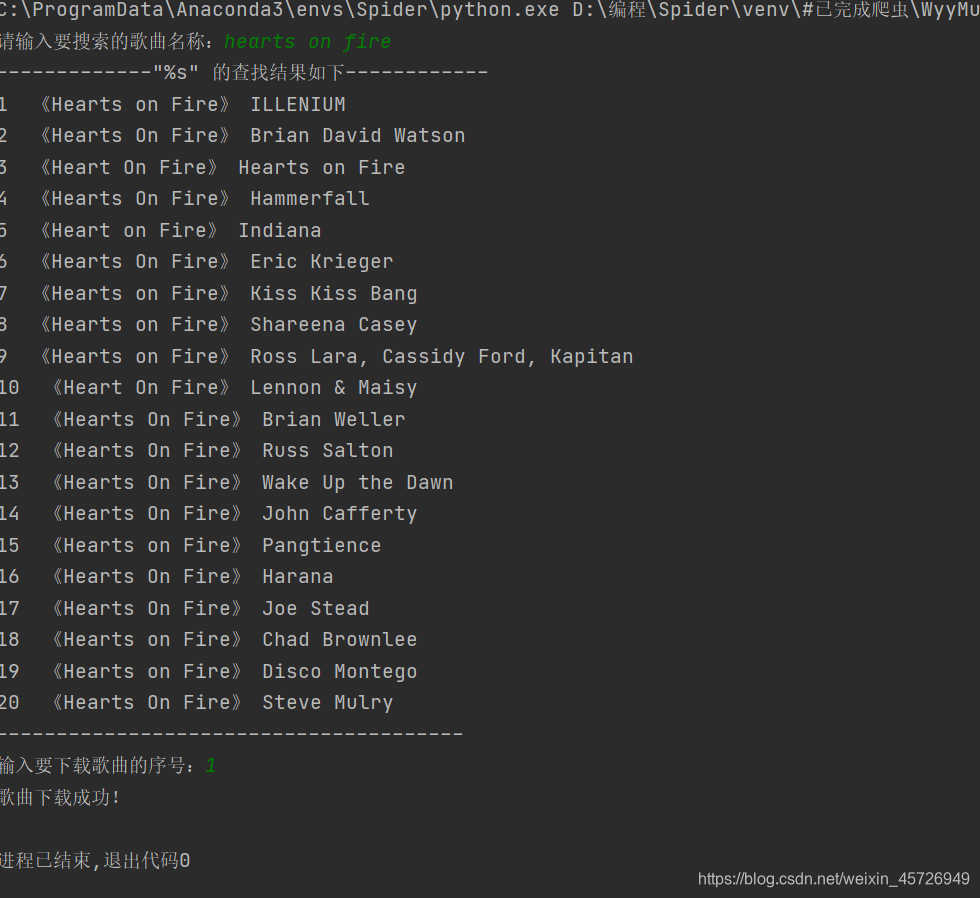
首先展示下成果

过程中使用到的知识:selenium,request,正则表达式,
# author:浸
# time:2021/1/31 10:07
# file:WyyMusic.py
# use:通过输入歌曲名称显示一系列搜索结果,选择下载歌曲
#通过api接口来下载歌曲:http://music.163.com/song/media/outer/url?id={}
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import requests
import time
import re
class Spider():
def __init__(self):
self.path="D://音乐//"
#这里是歌曲的api
self.download_api='http://music.163.com/song/media/outer/url?id='
self.head={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'}
#存放查找后歌曲信息的列表
self.message=[]
self.count=0
def __get_data(self):
#设置selenium无头模式
Chrome_options = Options()
Chrome_options.add_argument('--headless')
Chrome_options.add_argument('--disable-gpu')
bro = webdriver.Chrome(options=Chrome_options)
#通过url请求搜索结果
bro.get(self.url)
bro.switch_to.frame('contentFrame')
#网页渲染后源码存放搜索结果匹配的歌曲的一系列信息的class
music_list=bro.find_elements_by_class_name('srchsongst')[0]
#获取每一个歌曲的信息
music_list=music_list.find_elements_by_xpath('./div')
print('-------------"%s" 的查找结果如下------------')
for m in music_list:
#每一个歌曲都有自己专属的id,api+id就是歌曲下载地址
id=re.findall('.*?id=(.*?)$',m.find_element_by_xpath('./div[2]/div/div/a').get_attribute('href'))[0]
download_url=self.download_api+id
#歌曲名music_name=m.find_element_by_xpath('./div[2]/div/div/a/b').get_attribute('title')
#歌手名
music_author=m.find_element_by_xpath('./div[4]/div/a').text
#每一个歌曲信息做成一个字典
data={"name":music_name,'author':music_author,"url":download_url}
self.count+=1
self.message.append(data)
print('%d 《%s》 %s' %(self.count,music_name,music_author))
print('--------------------------------------------')
def __download(self,i):
name=self.message[i-1]["name"]
author=self.message[i-1]["author"]
url = self.message[i - 1]["url"]
data=requests.get(url,headers=self.head).content
with open(self.path+f'{name} {author}'+".mp3","wb") as file:
file.write(data)
file.close()
print(f'歌曲下载成功!')
def pc(self,key):
self.key=key
self.url=f'https://music.163.com/#/search/m/?s={str(key)}&type=1'
self.__get_data()
choose=input("输入要下载歌曲的序号:")
self.__download(int(choose))
if __name__=="__main__":
wyy=Spider()
music_name=input("请输入要搜索的歌曲名称:")
wyy.pc(music_name)

















 849
849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









