







Github完整代码获取:https://github.com/Lian-Zekun/python_spilder
1.实现功能
可以分别对歌名,歌手,歌单进行搜索,搜索歌曲和歌单会列出页面第一页所显示的所有歌曲或歌单及其id以供选择下载,搜索歌手会下载网易云音乐列表显示第一位歌手的所有热门歌曲。
2.具体实现
1.搜索部分
网易云音乐搜索界面为:https://music.163.com/#/search ,经过测试发现
对单曲搜索时链接为:https://music.163.com/#/search/m/?s={}&type=1 ,
对歌手搜索时链接为:https://music.163.com/#/search/m/?s={}&type=100 ,
对歌单搜索时链接为:https://music.163.com/#/search/m/?s={}&type=1000
其中大括号中内容为要搜索内容的名称,例如搜索年少有为,网址为:https://music.163.com/#/search/m/?s=年少有为&type=1 搜索后即出现此页面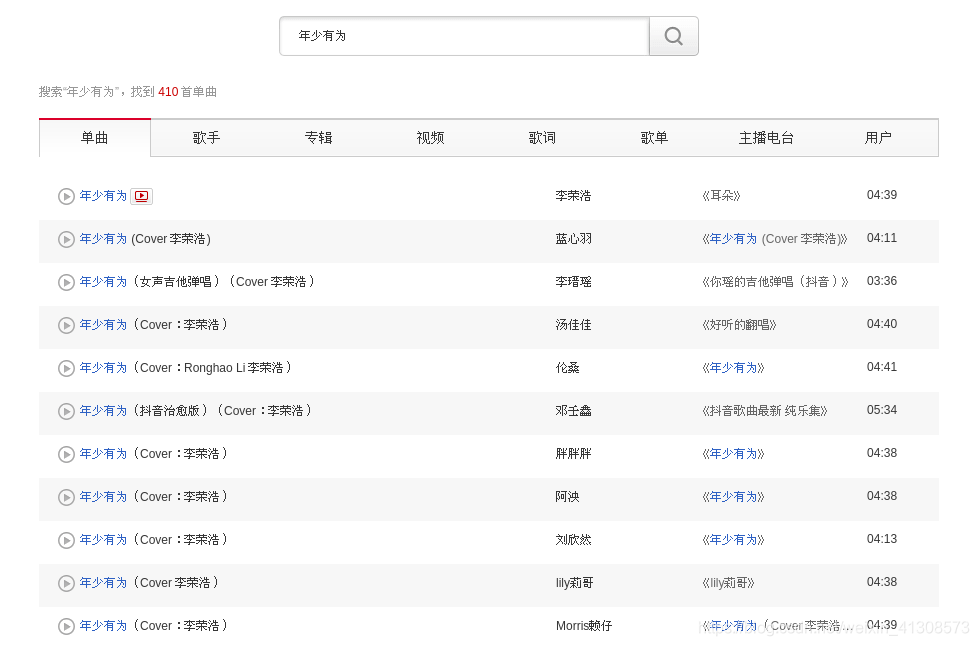
通过检查元素发现在网页的这一部分存在歌曲链接和名字
同理,在搜索歌单和歌手时检查元素也会发现类似的情况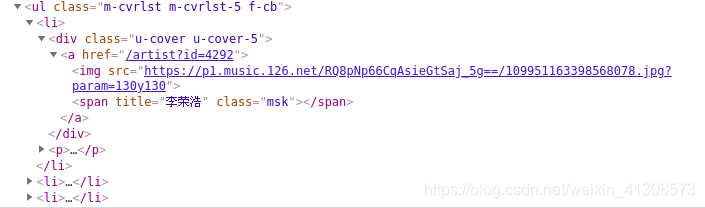
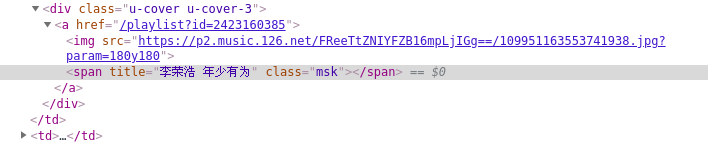
虽然分析网易云音乐接口可能会更快的得到这些信息,网上也有很多这样的文章,但菜鸡的我现在对js实在是不懂,选择selenium + chrome 获取js渲染后的页面源码,并通过xpath提取想要的信息(虽然速度是慢了点,但它简单啊)
python代码:
本文导入的所有模块及对爬虫的伪装
import requests
from urllib import request
from lxml import etree
from selenium import webdriver
import platform
import os
import time
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36',
'Host': 'music.163.com',
'Referer': 'https://music.163.com/'
}
通过selenium获得页面源码
def selenium_get_html(url):
"""通过selenium获得页面源码"""
# 无界面启动chrome
options = webdriver.ChromeOptions 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









