







 本文介绍了卷积神经网络的基础知识,包括卷积计算、三维卷积、池化层的作用。重点展示了如何使用PyTorch实现LeNet模型进行手势识别,以及训练过程和结果。还讨论了残差网络、1x1卷积、Inception网络等经典结构,并提到了迁移学习的应用。最后,给出了一个基于PyTorch的笑脸识别例子,展示了训练过程和高准确率的结果。
本文介绍了卷积神经网络的基础知识,包括卷积计算、三维卷积、池化层的作用。重点展示了如何使用PyTorch实现LeNet模型进行手势识别,以及训练过程和结果。还讨论了残差网络、1x1卷积、Inception网络等经典结构,并提到了迁移学习的应用。最后,给出了一个基于PyTorch的笑脸识别例子,展示了训练过程和高准确率的结果。
一、卷积相关
用一个f×f的过滤器卷积一个n×n的图像,假如padding为p,步幅为s,输出大小则为:
[ n + 2 p − f s + 1 ] × [ n + 2 p − f s + 1 ] [\frac{n+2p-f}{s}+1]×[\frac{n+2p-f}{s}+1] [sn+2p−f+1]×[sn+2p−f+1]
[]表示向下取整(floor)

大部分深度学习的方法对过滤器不做翻转等操作,直接相乘,更像是互相关,但约定俗成叫卷积运算。
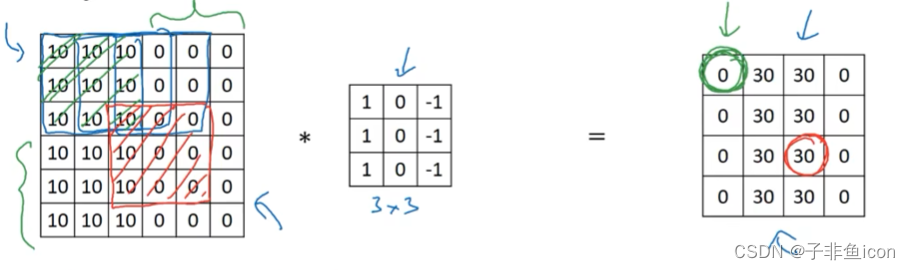
二、三维卷积
图片的数字通道数必须和过滤器中的通道数相匹配。
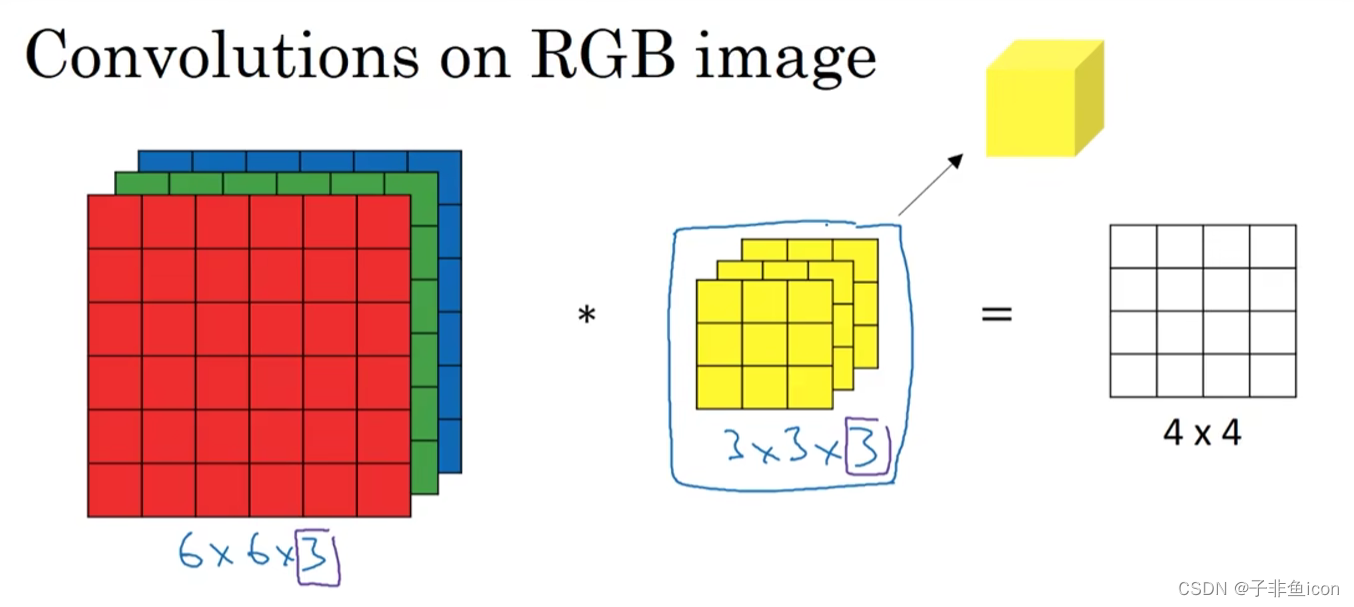
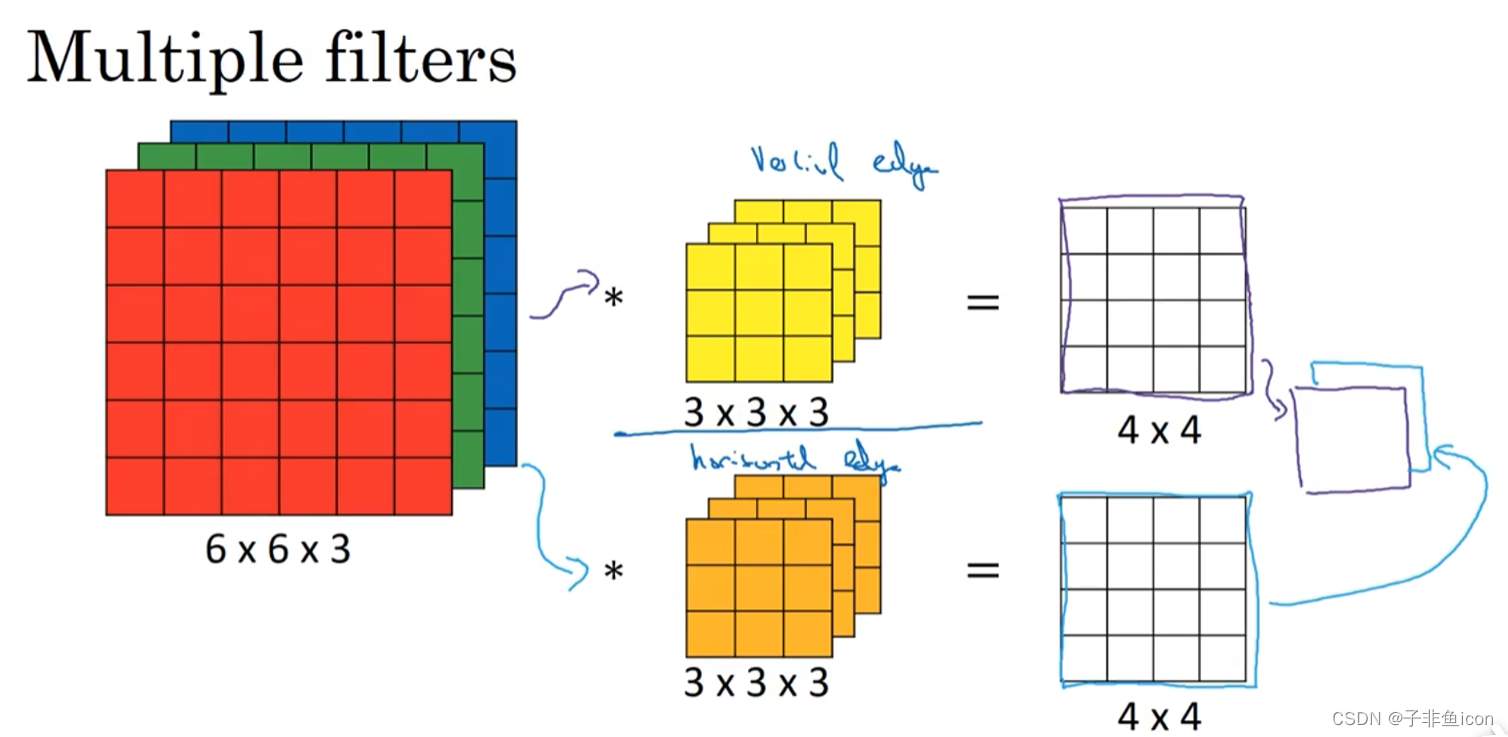
三维卷积相当于一个立方体与所有通道都乘起来然后求和。可以设计滤波器使得其得到单一通道,如红色的边缘特征。
卷积核通道数等于输入通道数,卷积核个数等于输出通道数。
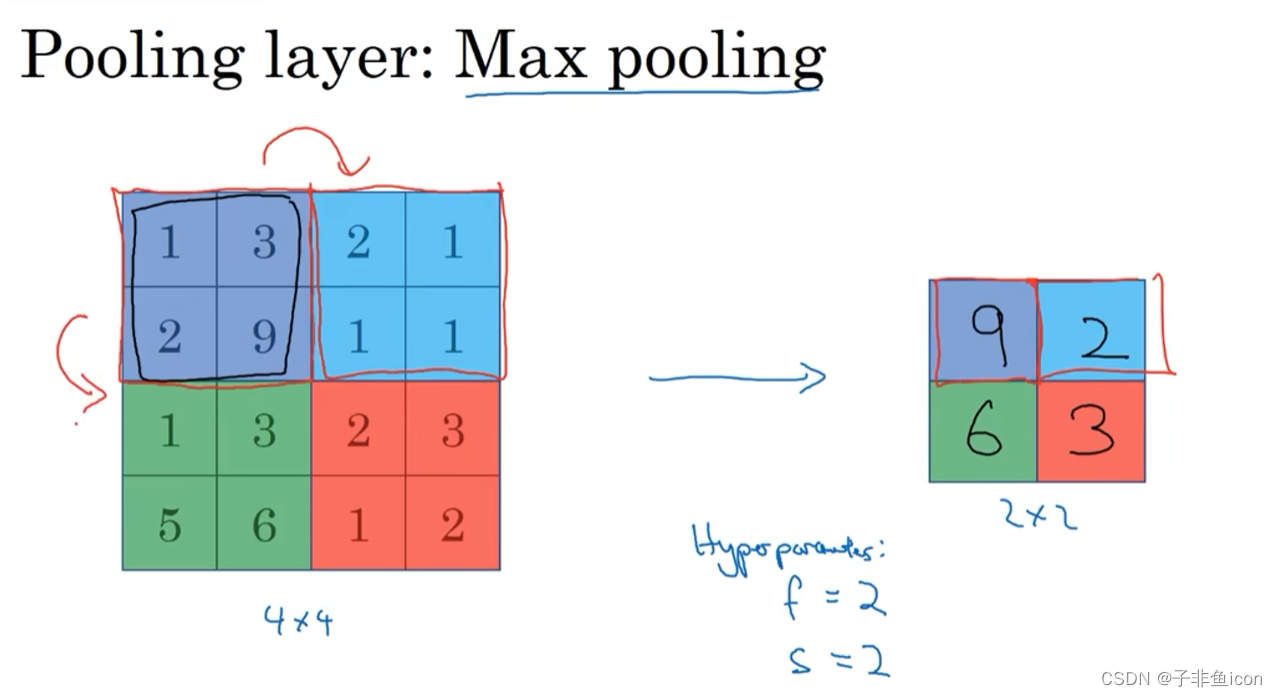
三、池化层
最大池化

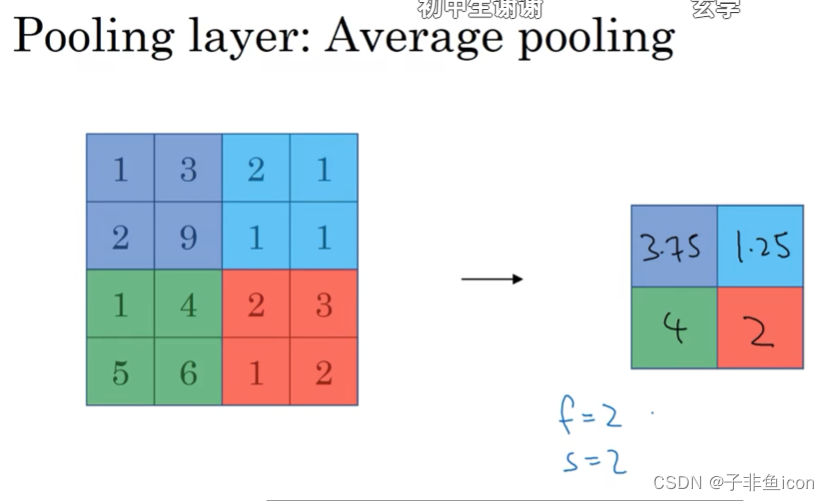
平均池化


四、为什么使用卷积
1.参数共享。


2.稀疏连接。


五、两个重要课后题





六、第一周课后作业
使用Pytorch来实现卷积神经网络,然后应用到手势识别中
代码:
import h5py
import time
import torch
import numpy as np
import torch.nn as nn
import matplotlib.pyplot as plt
#import cnn_utils
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载数据集
def load_dataset():
train_dataset = h5py.File('datasets/train_signs.h5', "r")
train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
test_dataset = h5py.File('datasets/test_signs.h5', "r")
test_set_x_orig = np.array(test_dataset["test_set_x"][:]) # your test set features
test_set_y_orig = np.array(test_dataset["test_set_y"][:]) # your test set labels
classes = np.array(test_dataset["list_classes"][:]) # the list of classes
train_set_y_orig = train_set_y_orig.reshape((train_set_y_orig.shape[0], 1))
test_set_y_orig = test_set_y_orig.reshape((test_set_y_orig.shape[0], 1))
return train_set_x_orig, train_set_y_orig, test_set_x_orig, test_set_y_orig, classes
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
print(X_train_orig.shape) # (1080, 64, 64, 3),训练集1080张,图像大小是64*64
print(Y_train_orig.shape) # (1080, 1)
print(X_test_orig.shape) # (120, 64, 64, 3),测试集120张
print(Y_test_orig.shape) # (120, 1)
print(classes.shape) # (6,) 一共6种类别,0,1,2,3,4,5
index = 6
plt.imshow(X_train_orig[index])
print ("y = " + str(np.squeeze(Y_train_orig[index,:])))
plt.show()
# 把尺寸(H x W x C)转为(C x H x W) ,即通道在最前面;归一化数据集
X_train = np.transpose(X_train_orig, (0, 3, 1, 2))/255 # 将维度转为(1080, 3, 64, 64)
X_test = np.transpose(X_test_orig, (0, 3, 1, 2))/255 # 将维度转为(120, 3, 64, 64)
Y_train = Y_train_orig
Y_test = Y_test_orig
# 转成Tensor方便后面的训练
X_train = torch.tensor(X_train, dtype=torch.float)
X_test = torch.tensor(X_test, dtype=torch.float)
Y_train = torch.tensor(Y_train, dtype=torch.float)
Y_test = torch.tensor(Y_test, dtype=torch.float)
print(X_train.shape)
print(X_test.shape)
print(Y_train.shape)
print(Y_test.shape)
# 使用交叉熵损失函数不用转化为独热编码
# LeNet模型
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=8, kernel_size=4, padding=1, stride=1), # in_channels, out_channels, kernel_size 二维卷积
nn.ReLU(),
nn.MaxPool2d(kernel_size=8, stride=8, padding=4), # kernel_size=2, stride=2;原函数就是'kernel_size', 'stride', 'padding'的顺序
nn.Conv2d(8, 16, 2, 1, 1),
nn 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1163
1163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









