










原文链接:
https://arxiv.org/abs/1807.06514
摘要简介:
近年来,深度神经网络的发展主要依赖于架构搜索来增强表示能力。在这项工作中,研究者们主要关注了注意力在通用深度神经网络中的作用。他们提出了一种简单而有效的注意力模块,名为瓶颈注意力模块(BAM),该模块可以与任何前馈卷积神经网络集成。
这个模块通过两个独立的路径——通道和空间,来推断注意力图。研究者们将这个模块放置在模型的每个瓶颈处,即特征图进行下采样的地方。该模块通过一定数量的参数在瓶颈处构建层次化的注意力,并且可以与任何前馈模型一起进行端到端的训练。
为了验证BAM的有效性,研究者们在CIFAR-100、ImageNet-1K、VOC 2007和MS COCO等基准数据集上进行了广泛的实验。实验结果显示,各种模型在分类和检测性能上均得到了一致的提升,这证明了BAM的广泛适用性。此外,相关的代码和模型也将公开提供。
总的来说,这个瓶颈注意力模块(BAM)是一个强大而灵活的工具,可以帮助提升深度神经网络在各种任务上的性能。
模型结构:
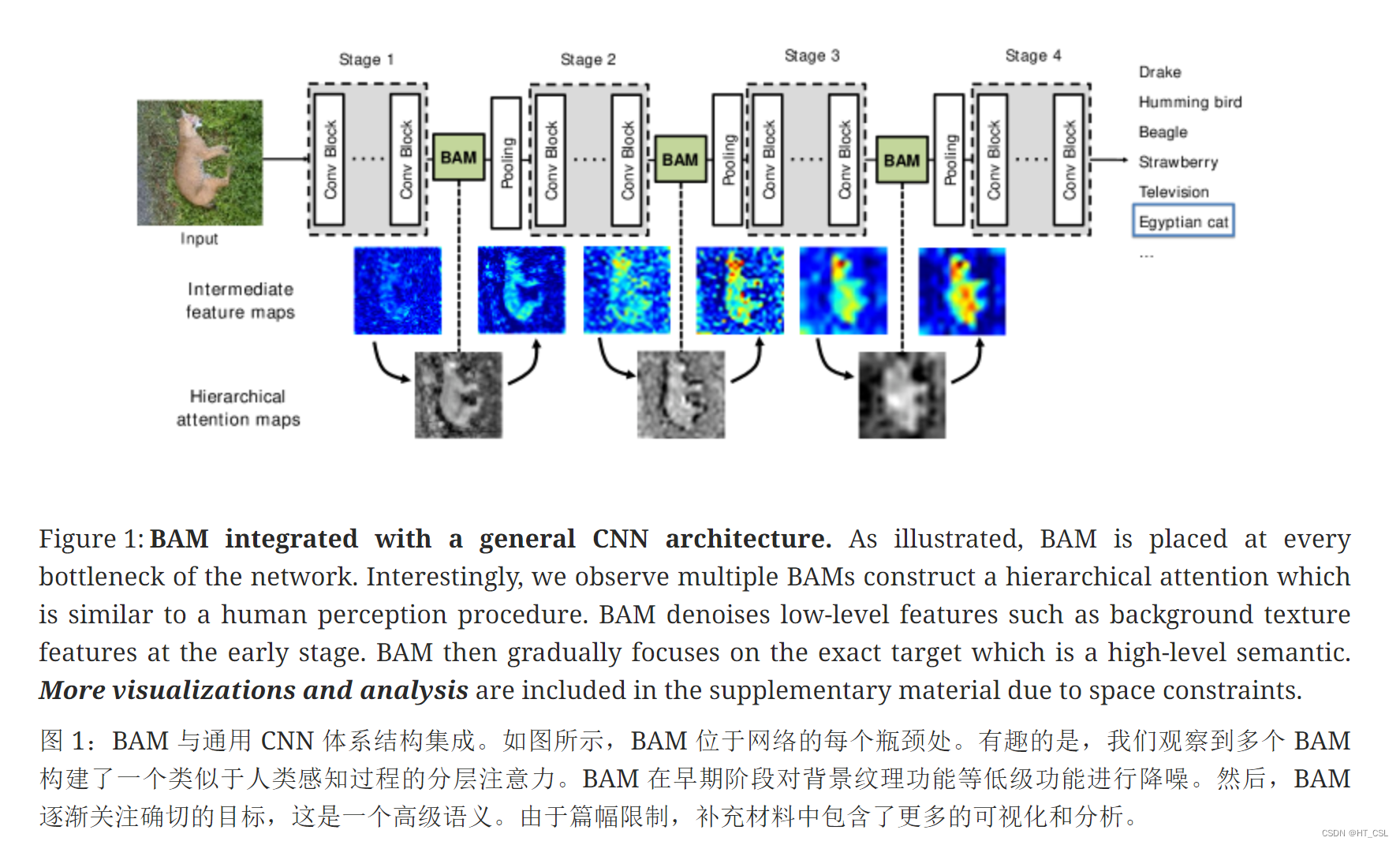
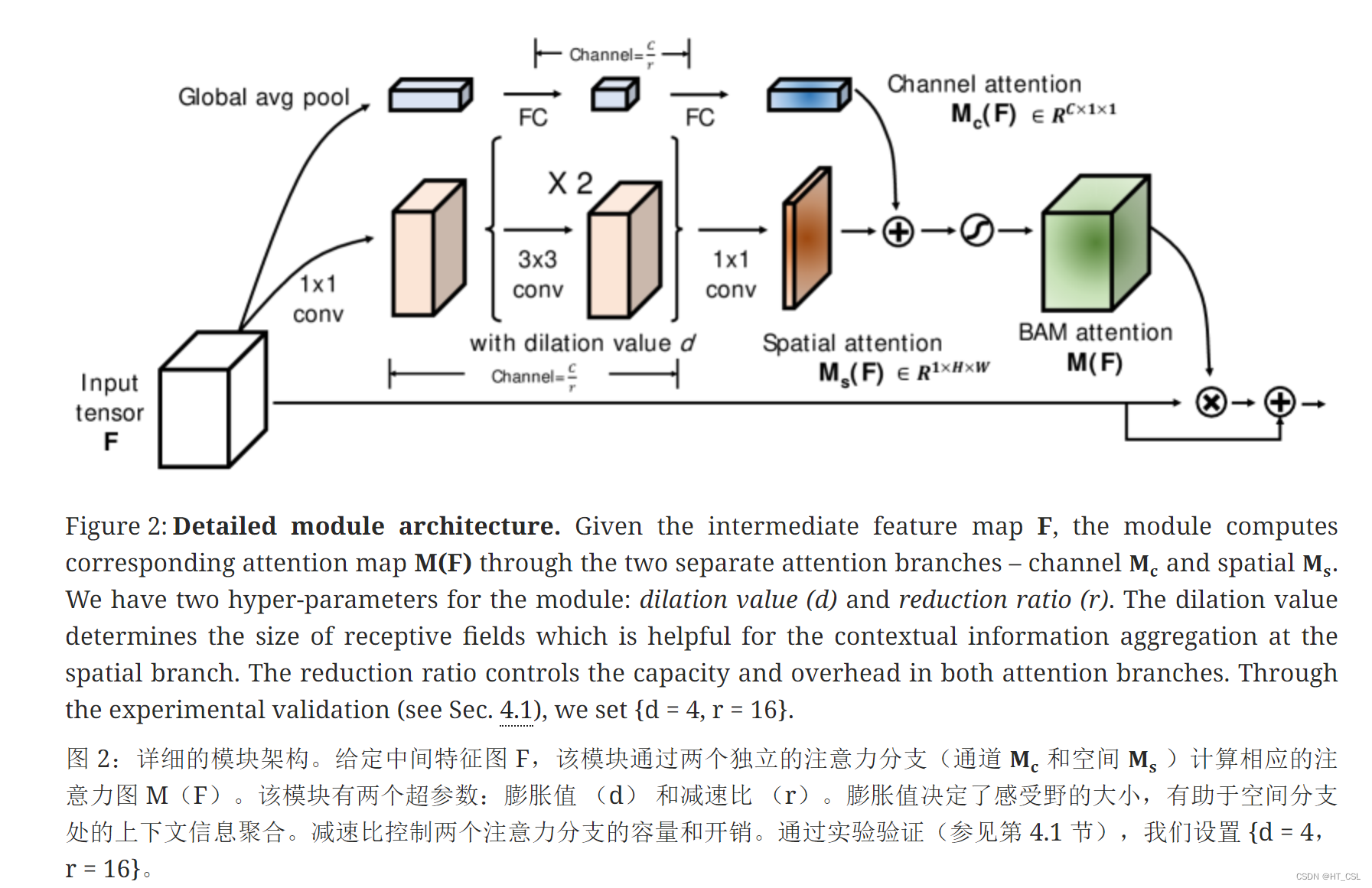
Pytorch版源码:
import torch
import math
import torch.nn as nn
import torch.nn.functional as F
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.size(0), -1)
class ChannelGate(nn.Module):
def __init__(self, gate_channel, reduction_ratio=16, num_layers=1):
super(ChannelGate, self).__init__()
self.gate_c = nn.Sequential()
self.gate_c.add_module( 'flatten', Flatten() )
gate_channels = [gate_channel]
gate_channels += [gate_channel // reduction_ratio] * num_layers
gate_channels += [gate_channel]
for i in range( len(gate_channels) - 2 ):
self.gate_c.add_module( 'gate_c_fc_%d'%i, nn.Linear(gate_channels[i], gate_channels[i+1]) )
self.gate_c.add_module( 'gate_c_bn_%d'%(i+1), nn.BatchNorm1d(gate_channels[i+1]) )
self.gate_c.add_module( 'gate_c_relu_%d'%(i+1), nn.ReLU() )
self.gate_c.add_module( 'gate_c_fc_final', nn.Linear(gate_channels[-2], gate_channels[-1]) )
def forward(self, in_tensor):
avg_pool = F.avg_pool2d( in_tensor, in_tensor.size(2), stride=in_tensor.size(2) )
return self.gate_c( avg_pool ).unsqueeze(2).unsqueeze(3).expand_as(in_tensor)
class SpatialGate(nn.Module):
def __init__(self, gate_channel, reduction_ratio=16, dilation_conv_num=2, dilation_val=4):
super(SpatialGate, self).__init__()
self.gate_s = nn.Sequential()
self.gate_s.add_module( 'gate_s_conv_reduce0', nn.Conv2d(gate_channel, gate_channel//reduction_ratio, kernel_size=1))
self.gate_s.add_module( 'gate_s_bn_reduce0', nn.BatchNorm2d(gate_channel//reduction_ratio) )
self.gate_s.add_module( 'gate_s_relu_reduce0',nn.ReLU() )
for i in range( dilation_conv_num ):
self.gate_s.add_module( 'gate_s_conv_di_%d'%i, nn.Conv2d(gate_channel//reduction_ratio, gate_channel//reduction_ratio,
kernel_size=3, padding=dilation_val, dilation=dilation_val) )
self.gate_s.add_module( 'gate_s_bn_di_%d'%i, nn.BatchNorm2d(gate_channel//reduction_ratio) )
self.gate_s.add_module( 'gate_s_relu_di_%d'%i, nn.ReLU() )
self.gate_s.add_module( 'gate_s_conv_final', nn.Conv2d(gate_channel//reduction_ratio, 1, kernel_size=1) )
def forward(self, in_tensor):
return self.gate_s( in_tensor ).expand_as(in_tensor)
class BAM(nn.Module):
def __init__(self, gate_channel):
super(BAM, self).__init__()
self.channel_att = ChannelGate(gate_channel)
self.spatial_att = SpatialGate(gate_channel)
def forward(self,in_tensor):
att = 1 + torch.sigmoid( self.channel_att(in_tensor) * self.spatial_att(in_tensor) )
return att * in_tensor
if __name__ == '__main__':
input = torch.randn(2, 32, 512, 512)
BAM = BAM(gate_channel=input.size(1))
output = BAM(input)
print(output.shape)
















 932
932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









