







简介:本文提出pixelSplat,一种从成对图像中重建由3D高斯参数化的辐射场的前馈网络。该方法渲染和3D重建的速度快,且节省空间。为克服稀疏且局部支持固有的局部极小值,本文预测密集概率分布,并从中采样3D高斯均值。通过重参数化技巧,使采样过程可微,从而允许梯度回传到高斯溅射表达。实验表明本文方法能重建可编辑的3D辐射场并加速渲染,且性能可以超越sota的光场Transformer。
0. 背景:3D高斯溅射
3DGS将3D场景参数化为3D高斯的集合 { g k = ( μ k , Σ k , α k , S k ) } k K \{g_k=(\mu_k,\Sigma_k,\alpha_k,S_k)\}_k^K {gk=(μk,Σk,αk,Sk)}kK,其中 μ k , Σ k , α k , S k \mu_k,\Sigma_k,\alpha_k,S_k μk,Σk,αk,Sk分别为均值、协方差、不透明度和球面谐波系数。与密集表达如神经场或体素网格,3D高斯可使用栅格化操作进行快速而不占空间的渲染。
局部极小:3DGS的拟合与高斯混合模型的拟合密切相关,即需要寻找一组高斯的参数使样本的可能性最大化。3DGS的高斯被初始化到随机位置,并在训练过程中移动到最终位置。但高斯的局部支持性使得在距离正确位置超过几个标准差时,梯度会消失;即便离正确位置很近,也需要找到一条损失值随着距离减小而单调降低的移动路径。在可微渲染中,因为高斯可能会途经空空间并遮挡背景特征(导致损失增大),故3DGS需要依赖不可微的“自适应密度控制”(来避免局部极小);但在可泛化情况下,3D高斯由必须接收梯度的神经网络预测(操作必须可微)。因此本文提出不受局部极小影响的高斯可微参数化。
1. 解决尺度模糊性
理想的新视图合成数据集会包含度量的相机姿态。每个场景
C
i
m
C_i^m
Cim会包含一组元组
C
i
m
=
{
(
I
j
,
T
j
m
)
}
j
C_i^m=\{(I_j,T_j^m)\}_j
Cim={(Ij,Tjm)}j,其中
I
j
I_j
Ij为图像,
T
j
m
T_j^m
Tjm为其姿态。但实际中,相机的姿态是按比例放缩的(由SfM计算),从而导致不同的场景
C
i
C_i
Ci会按照不同的随机尺度
s
i
s_i
si放缩。给定场景
C
i
=
{
(
I
j
,
s
i
T
j
)
}
j
C_i=\{(I_j,s_iT_j)\}_j
Ci={(Ij,siTj)}j,从单一图像恢复
s
i
s_i
si是不可能的,即重建网络不可能预测与姿态匹配的深度,如图所示。

本文首先将每个视图分别编码为特征
F
,
F
~
F,\tilde F
F,F~。令
u
u
u为
I
I
I中的像素坐标,
ℓ
\ell
ℓ为
I
~
\tilde I
I~中的对极线(
u
u
u的相机射线在
I
~
\tilde I
I~中的投影),沿
ℓ
\ell
ℓ采样像素
{
u
~
l
}
∼
I
~
\{\tilde u_l\}\sim \tilde I
{u~l}∼I~。对每个样本
u
~
l
\tilde u_l
u~l,通过
u
u
u和
u
~
l
\tilde u_l
u~l的三角测量,计算到
I
I
I相机中心的距离
d
~
u
~
l
\tilde d_{\tilde u_l}
d~u~l。随后,计算对极注意力的查询、键与值:
s
=
F
~
[
u
~
l
]
⊕
γ
(
d
~
u
~
l
)
q
=
Q
⋅
F
[
u
]
,
k
l
=
K
⋅
s
,
v
l
=
V
⋅
s
s=\tilde F[\tilde u_l]\oplus\gamma(\tilde d_{\tilde u_l})\\ q=Q\cdot F[u],\;k_l=K\cdot s,\;v_l=V\cdot s
s=F~[u~l]⊕γ(d~u~l)q=Q⋅F[u],kl=K⋅s,vl=V⋅s
其中
⊕
\oplus
⊕为拼接(concat),
γ
(
⋅
)
\gamma(\cdot)
γ(⋅)为位置编码。按下式更新
F
[
u
]
F[u]
F[u]:
F
[
u
]
+
=
A
t
t
(
q
,
{
k
l
}
,
{
v
l
}
)
F[u]+=\mathtt{Att}(q,\{k_l\},\{v_l\})
F[u]+=Att(q,{kl},{vl})
更新后的
F
[
u
]
F[u]
F[u]包含了深度位置编码的加权和,且正确对应的权重最大。因此,
F
[
u
]
F[u]
F[u]编码了与缩放后相机姿态对应的缩放深度。随后,使用自注意力使缩放深度估计传播到无对极对应的区域:
F
[
u
]
+
=
S
e
l
f
A
t
t
(
F
)
F[u]+=\mathtt{SelfAtt}(F)
F[u]+=SelfAtt(F)
注意该机制也可扩展到多视图。
2. 高斯参数预测
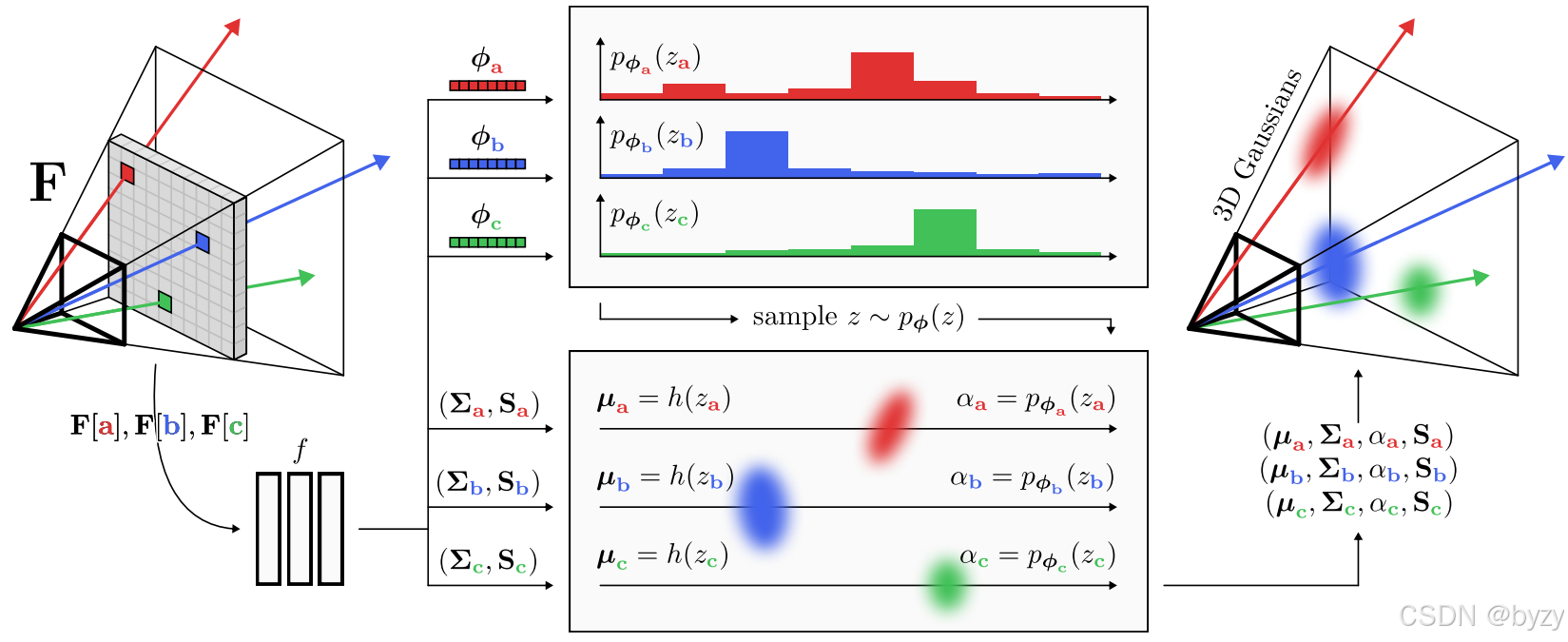
本步骤使用尺度感知的特征图预测高斯。由于图像像素采样了3D场景中的表面点,本文使用像素对齐的高斯:对坐标为
u
u
u的像素,以图像特征
F
[
u
]
F[u]
F[u]为输入,预测
M
M
M个高斯。其中,最重要的问题是如何参数化位置
μ
\mu
μ。本文方法的预测流程如图所示。
基准方案:预测
μ
\mu
μ的点估计。直接回归高斯中心
μ
\mu
μ即使用神经网络
g
g
g预测高斯中心到相机中心
o
o
o的距离
d
u
d_u
du,并反投影到3D:
μ
=
o
+
d
u
d
,
d
u
=
g
(
F
[
u
]
)
,
d
=
T
K
−
1
[
u
,
1
]
T
\mu=o+d_ud,\;d_u=g(F[u]),\;d=TK^{-1}[u,1]^T
μ=o+dud,du=g(F[u]),d=TK−1[u,1]T
其中 d d d为相机射线方向, K , T K,T K,T为相机内外参。直接优化高斯参数会陷入局部极小,因此本文提出一种可微替代。
本文提出的方案:预测
μ
\mu
μ的概率密度。本文预测沿射线
u
u
u的高斯距离相机中心为
d
d
d的概率分布,定义深度范围
[
d
n
e
a
r
,
d
f
a
r
]
[d_{near},d_{far}]
[dnear,dfar],将深度离散化为
Z
Z
Z个区间,得到向量
b
∈
R
Z
b\in\mathbb R^Z
b∈RZ,其中第
z
z
z个元素(第
z
z
z个区间对应的深度值)为
b
z
=
(
(
1
−
z
Z
)
(
1
d
n
e
a
r
−
1
d
f
a
r
)
+
1
d
f
a
r
)
−
1
b_z=((1-\frac zZ)(\frac1{d_{near}}-\frac1{d_{far}})+\frac1{d_{far}})^{-1}
bz=((1−Zz)(dnear1−dfar1)+dfar1)−1
注意此处的深度区间并非均匀划分的。
随后,定义离散概率分布
p
ϕ
(
z
)
p_\phi(z)
pϕ(z),其元素
ϕ
z
\phi_z
ϕz为
b
z
b_z
bz内存在表面的概率。概率
ϕ
\phi
ϕ由全连接网络
f
f
f根据
F
[
u
]
F[u]
F[u]预测,并通过softmax归一化。进一步,预测偏移量
δ
∈
[
0
,
1
]
Z
\delta\in[0,1]^Z
δ∈[0,1]Z调整高斯:
μ
=
o
+
(
b
z
+
δ
z
)
d
u
,
z
∼
p
ϕ
(
z
)
,
(
ϕ
,
δ
)
=
f
(
F
[
u
]
)
\mu=o+(b_z+\delta_z)d_u,\;z\sim p_\phi(z),\;(\phi,\delta)=f(F[u])
μ=o+(bz+δz)du,z∼pϕ(z),(ϕ,δ)=f(F[u])
前向过程中,高斯会从预测的分布中采样。
通过设置 α = ϕ z \alpha=\phi_z α=ϕz使采样可微。由于需要将梯度反传到概率 ϕ \phi ϕ(即计算 ∇ ϕ μ \nabla_\phi\mu ∇ϕμ),但 z ∼ p ϕ ( z ) z\sim p_\phi(z) z∼pϕ(z)的采样过程是不可微的,本文通过重参数化技巧,将不透明度 α \alpha α设置为对应的采样概率,即 α = ϕ z \alpha=\phi_z α=ϕz。因此,反向传播时对损失 L L L的梯度 ∇ ϕ L = ∇ α L \nabla_\phi L=\nabla_\alpha L ∇ϕL=∇αL。
为便于理解,假设采样了正确的深度。此时梯度下降会增大高斯的不透明度,从而更可能被采样。最终会导致所有概率集中到该区间;若不正确采样,梯度下降会减小高斯的不透明度,从而减小该区间被采样的概率。
预测
Σ
\Sigma
Σ和
S
S
S。通过扩展网络
f
f
f,预测协方差矩阵和球面谐波系数:
ϕ
,
δ
,
Σ
,
S
=
f
(
F
[
u
]
)
\phi,\delta,\Sigma,S=f(F[u])
ϕ,δ,Σ,S=f(F[u])
小结。下面的算法即高斯的预测过程。



















 4228
4228

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











