



 本文详细介绍了如何使用C++编写一个词法分析器,针对给定的C语言子集,包括单词分类、正则表达式和源代码实例解析。通过逐个识别并输出二元组,展示了词法分析的过程和结果。
本文详细介绍了如何使用C++编写一个词法分析器,针对给定的C语言子集,包括单词分类、正则表达式和源代码实例解析。通过逐个识别并输出二元组,展示了词法分析的过程和结果。
《编译原理》实验一:词法分析器 C++ 版
考虑如下C语言子集:
| 单词 | 类别编码 | 助记符 | 值 |
|---|---|---|---|
| break | 1 | BREAK | _ |
| char | 2 | CHAR | _ |
| do | 3 | DO | _ |
| double | 4 | DOUBLE | _ |
| else | 5 | ELSE | _ |
| if | 6 | IF | _ |
| int | 7 | INT | _ |
| return | 8 | RETURN | _ |
| void | 9 | VOID | _ |
| while | 10 | WHILE | _ |
| 标识符 | 11 | ID | 构成标识符的字符串 |
| 常数 | 12 | NUM | 数值 |
| 字符串 | 13 | STRING | 字符串 |
| + | 14 | ADD | _ |
| - | 15 | SUB | _ |
| * | 16 | MUL | _ |
| / | 17 | DIV | _ |
| > | 18 | GT | _ |
| >= | 19 | GE | _ |
| < | 20 | LT | _ |
| <= | 21 | LE | _ |
| == | 22 | EQ | _ |
| != | 23 | NE | _ |
| = | 24 | ASSIGN | _ |
| { | 25 | LB | _ |
| } | 26 | RB | _ |
| ) | 27 | LR | _ |
| ) | 28 | RR | _ |
| , | 29 | COMMA | _ |
| ; | 30 | SEMI | _ |
-
单词的正则定义如下
- D = [0-9]
- L = [a-zA-Z_]
- H = [a-fA-F0-9]
- E = [Ee][±]?{D}+
- FS = (f|F|l|L)
- IS = (u|U|l|L)* 标识符
- id = {L}({L}|{D})* 常数
- num:
- 0[xX]{H}+{IS}?
- | 0{D}+{IS}?
- | {D}+{IS}?
- | L?‘(\.|[^\’])+’
- | {D}+{E}{FS}?
- | {D}*“.”{D}+({E})?{FS}?
- | {D}+“.”{D}*({E})?{FS}? 字符串
- string = L?“(\.|[^\”])*"
对给定的源程序进行词法分析,每个单词一行,以二元组的形式输出结果。
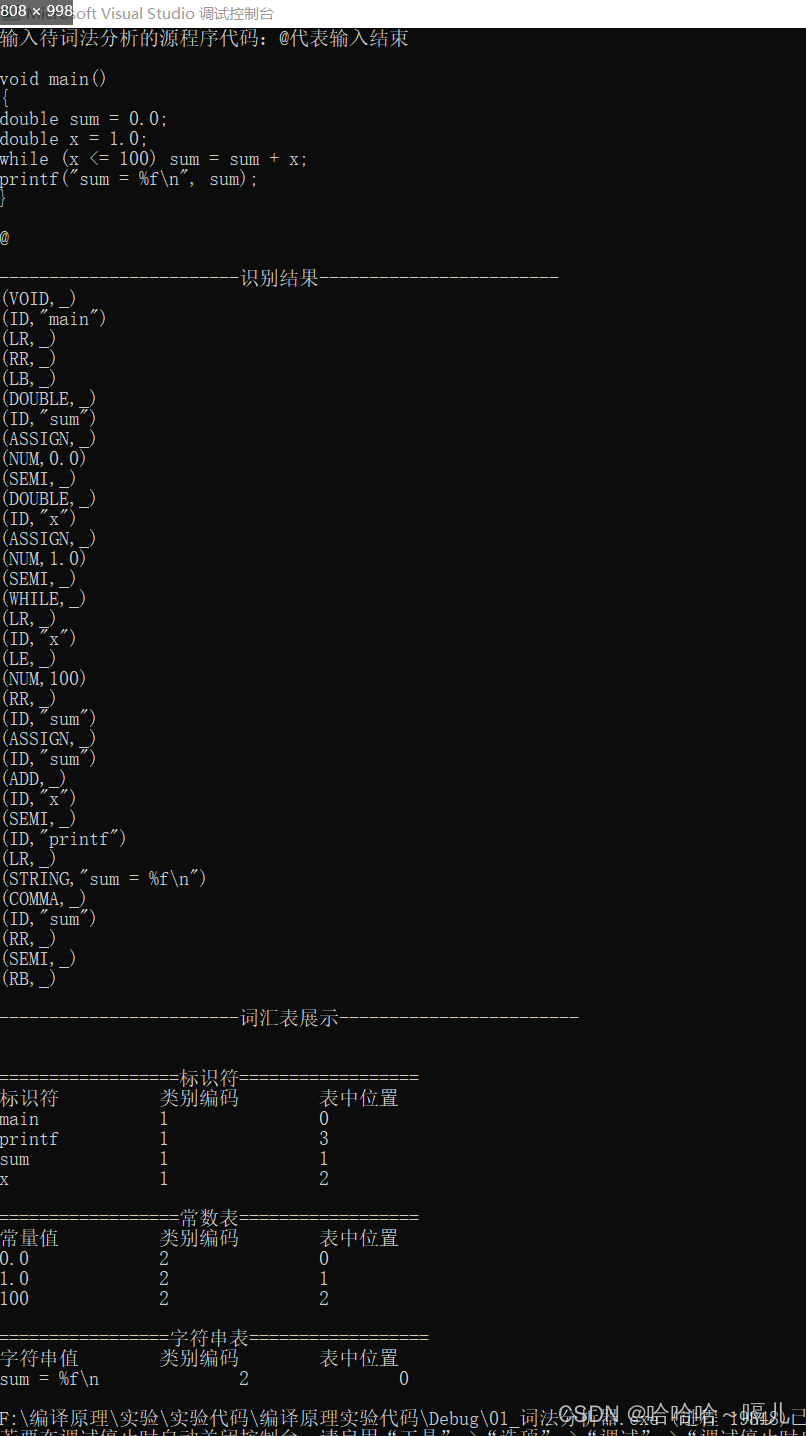
例如,下面的源程序代码
void main()
{
double sum = 0.0;
double x = 1.0;
while (x <= 100) sum = sum + x;
printf("sum = %f\n", sum);
}
词法分析的结果为
(VOID, _)
(ID, “main”)
(LR, _)
(RR, _)
(LB, _)
(DOUBLE, _)
(ID, “sum”)
(ASSIGN, _)
(NUM, 0.0)
(SEMI, _)
(DOUBLE, _)
(ID, “x”)
(ASSIGN, _)
(NUM, 1.0)
(SEMI, _)
(RB, _)
(WHILE, _)
(LR, _)
(ID, “x”)
(LE, _)
(NUM, 100)
(RR, _)
(ID, “sum”)
(ASSIGN, _)
(ID, “sum”)
(ADD, _)
(ID, “x”)
(SEMI, _)
(ID, “printf”)
(LR, _)
(STRING, “sum = %f\n”)
(COMMA, _)
(ID, “sum”)
(RR, _)
(SEMI, _)
(RB, _)
编写C++代码
#include <iostream>
#include <map>
#include <algorithm>
#include <string>
#include<Windows.h>
using namespace std;
string in_str; //输入符号串
int index; //当前输入符号读入字符的位置
char character; //全局变量字符,存放最新读入的字符
string token; //字符数组,存放已读入的字符序列
map<string, int> Symbol; //标识符集
map<string, int> Digit; //常数集
map<string, int> String; //常数集
map<string, int>::iterator ite;
const int len = 100;
//string Reserve[len]; //保留字表
string Reserve[3 * len];
struct Binary {
Binary(int c, int i, string v = "_") {
type = c;
index = i;
value = v;
}
int type = 0;
int index = 0;
string value = "_";
};
//构造保留字表的函数
void init_Reserve()
{
// 单词
Reserve[1] = "break";
Reserve[2] = "char";
Reserve[3] = "do";
Reserve[4] = "double";
Reserve[5] = "else";
Reserve[6] = "if";
Reserve[7] = "int";
Reserve[8] = "return";
Reserve[9] = "void";
Reserve[10] = "while";
Reserve[11] = "id";
Reserve[12] = "num";
Reserve[13] = "string";
Reserve[14] = "+";
Reserve[15] = "-";
Reserve[16] = "*";
Reserve[17] = "/";
Reserve[18] = ">";
Reserve[19] = ">=";
Reserve[20] = "<";
Reserve[21] = "<=";
Reserve[22] = "==";
Reserve[23] = "!=";
Reserve[24] = "=";
Reserve[25] = "{";
Reserve[26] = "}";
Reserve[27] = "(";
Reserve[28] = ")";
Reserve[29] = ",";
Reserve[30] = ";";
//助记符
Reserve[31] = "BREAK";
Reserve[32] = "CHAR";
Reserve[33] = "DO";
Reserve[34] = "DOUBLE";
Reserve[35] = "ELSE";
Reserve[36] = "IF";
Reserve[37] = "INT";
Reserve[38] = "RETURN";
Reserve[39] = "VOID";
Reserve[40] = "WHILE";
Reserve[41] = "ID";
Reserve[42] = "NUM";
Reserve[43] = "STRING";
Reserve[44] = "ADD";
Reserve[45] = "SUB";
Reserve[46] = "MUL";
Reserve[47] = "DIV";
Reserve[48] = "GT";
Reserve[49] = "GE";
Reserve[50] = "LT";
Reserve[51] = "LE";
Reserve[52] = "EQ";
Reserve[53] = "NE";
Reserve[54] = "ASSIGN";
Reserve[55] = "LB";
Reserve[56] = "RB";
Reserve[57] = "LR";
Reserve[58] = "RR";
Reserve[59] = "COMMA";
Reserve[60] = "SEMI";
Reserve[61] = "\"";
}
//读入一个字符
void getChar() {
character = in_str[index++];
}
//读入非空白字符
void get_no_blank()
{
while (character == ' ') {
getChar();
}
}
//连接字符串
void concat() {
token = token + character;
}
//回退字符的函数
void retract()
{
character = ' ';
index--;
}
//判断是否为字母
bool is_letter()
{
if ((character >= 'A' && character <= 'Z') || (character >= 'a' && character <= 'z'))
return true;
return false;
}
//判断是否为数字
bool is_digit()
{
if (character >= '0' && character <= '9')
return true;
/*
if (character >= '0' && character <= '9') { //浮点数
getChar();
if (character == '.') {
return true;
}
return false;
}
else if (character == 'o' || character <= 'O') { // 十六进制
getChar();
if (character == 'x' || character <= 'X') {
return true;
}
return true;
}
else { // 科学计数法
return true;
}
*/
return false;
}
bool is_string()
{
if (character == '"' )
return true;
return false;
}
int dot_Sum = 0;
bool is_dotOnce()
{
if(character == '.')
dot_Sum++;
if (dot_Sum == 1 || dot_Sum == 0)
return true;
else
return false;
}
//匹配保留字符
int reserve()
{
for (int i = 0; i < 3 * len; i++)
if (Reserve[i] == token)
return i;
return -1;
}
string symbol()
{
ite = Symbol.find(token);
if (ite != Symbol.end()) {
return ite->first;
}
else {
Symbol[token] = Symbol.size();
return token;
}
}
string constant()
{
ite = Digit.find(token);
if (ite != Digit.end()) {
return ite->first;
}
else {
Digit[token] = Digit.size();
return token;
}
}
string _string()
{
ite = String.find(token);
if (ite != String.end()) {
return ite->first;
}
else {
String[token] = String.size();
return token;
}
}
Binary error()
{
//SetConsoleTextAttribute(GetStdHandle(STD_OUTPUT_HANDLE), FOREGROUND_RED);
cout << token << "单词错误!" << endl;
return Binary(0, 0);
}
//词法分析函数,逐个识别单词
Binary LexAnalyze()
{
token = "";
getChar();
get_no_blank();
string val;
int num = -1;
dot_Sum = 0;
//char temp = getchar();
switch (character) {
case'a':
case'b':
case'c':
case'd':
case'e':
case'f':
case'g':
case'h':
case'i':
case'j':
case'k':
case'l':
case'm':
case'n':
case'o':
case'p':
case'q':
case'r':
case's':
case't':
case'u':
case'v':
case'w':
case'x':
case'y':
case'z':
case'A':
case'B':
case'C':
case'D':
case'E':
case'F':
case'G':
case'H':
case'I':
case'J':
case'K':
case'L':
case'M':
case'N':
case'O':
case'P':
case'Q':
case'R':
case'S':
case'T':
case'U':
case'V':
case'W':
case'X':
case'Y':
case'Z':
while (is_letter() || is_digit() || character=='_') { //为字母 数字 下划线
concat(); //追加到token末尾
getChar(); //读取下一个字符
}
retract(); //回退一个字符
num = reserve(); //查看保留字表
if (num != -1) {
return Binary(num, 1);
}
else {
val = symbol(); //查看标识符表
return Binary(1, Symbol[val], val);
}
break;
case'0':
//dot_Sum = -1;
concat();
getChar();
if (character == 'x' || character == 'X') //十六进制
{
concat(); //追加到token末尾
getChar(); //读取下一个字符
while (is_letter() || is_digit()) { //为字母 数字
concat(); //追加到token末尾
getChar(); //读取下一个字符
}
retract(); //回退一个字符
val = constant();
return Binary(2, Digit[val], val);
}
else if (is_dotOnce() || is_digit())
{
concat(); //追加到token末尾
getChar();
while (is_digit() && is_dotOnce()) { //为数字
concat();
getChar();
}
retract();
val = constant(); //查看常数表
return Binary(2, Digit[val], val);
//break;
}
else
retract();
break;
case'1':
case'2':
case'3':
case'4':
case'5':
case'6':
case'7':
case'8':
case'9':
concat(); //追加到token末尾
getChar();
while (is_digit() || character == '.' && is_dotOnce() || is_letter())
{
if (character == 'e' || character == 'E') {
concat();
getChar();
if (character == '-' || is_digit()) {
concat();
getChar();
continue;
}
}
concat();
getChar();
}
retract();
val = constant(); //查看常数表
return Binary(2, Digit[val], val);
/*
if (is_dotOnce() || is_digit())
{
concat(); //追加到token末尾
getChar();
while (is_digit() && is_dotOnce() || is_letter())
{
if (character == 'e' || character == 'E') {
concat();
getChar();
if (character == '-' || is_digit()) {
concat();
getChar();
continue;
}
}
concat();
getChar();
}
retract();
val = constant(); //查看常数表
return Binary(2, Digit[val], val);
}
*/
break;
case'<':
getChar();
if (character == '=')
return Binary(21, 0); //返回<=符号
else {
retract();
return Binary(20, 0); //返回<符号
}
break;
case'>':
getChar();
if (character == '=')
return Binary(19, 0); //返回>=符号
else {
retract();
return Binary(18, 0); //返回>符号
}
break;
case'=':
getChar();
if (character == '=')
return Binary(22, 0); //返回==符号
else {
retract();
return Binary(24, 0); //返回=符号
}
break;
case'!':
getChar();
if (character == '=')
return Binary(23, 0);
else
return error();
break;
case'+':
return Binary(14, 0);
break;
case'-':
return Binary(15, 0);
break;
case'*':
return Binary(16, 0);
break;
case'/':
getChar();
if (character == '/') // 单行注释
{
concat();
getChar();
//temp = getchar();
while (! '\n') {
concat();
getChar();
//temp = getchar();
}
return Binary(0, 0);
}
else if(character == '*') // 块注释
{
concat();
getChar();
while (character != '*') {
concat();
getChar();
}
concat();
getChar();
if (character == '/') {
return Binary(0, 0);
//break;
}
else
error();
}
else {
retract();
return Binary(17, 0); // 返回除号
//break;
}
break;
case'{':
return Binary(25, 0);
break;
case'}':
return Binary(26, 0);
break;
case'(':
return Binary(27, 0);
break;
case')':
return Binary(28, 0);
break;
case',':
return Binary(29, 0);
break;
case';':
return Binary(30, 0);
break;
case'"':
getChar();
while (character != '"') { // 字符串(“”)
concat();
getChar();
}
val = _string();
return Binary(3, String[val], val);
break;
default:
return error();
}
}
void show_table()
{
/*
cout << "==================" << "保留字" << "==================" << endl;
cout << "保留字符\t类别编码" << endl;
for (int i = 0; i < len; i++) {
if (Reserve[i] != "") {
if (Reserve[i].size() >= 8)
cout << Reserve[i] << "\t" << i << endl;
else
cout << Reserve[i] << "\t\t" << i << endl;
}
}
*/
cout << "\n==================" << "标识符" << "==================" << endl;
cout << "标识符\t\t类别编码\t表中位置" << endl;
for (ite = Symbol.begin(); ite != Symbol.end(); ite++) {
if (ite->first.size() >= 8)
cout << ite->first << "\t1\t\t" << ite->second << endl;
else
cout << ite->first << "\t\t1\t\t" << ite->second << endl;
}
cout << "\n==================" << "常数表" << "==================" << endl;
cout << "常量值\t\t类别编码\t表中位置" << endl;
for (ite = Digit.begin(); ite != Digit.end(); ite++) {
cout << ite->first << "\t\t2\t\t" << ite->second << endl;
}
cout << "\n=================" << "字符串表" << "==================" << endl;
cout << "字符串值\t类别编码\t表中位置" << endl;
for (ite = String.begin(); ite != String.end(); ite++) {
cout << ite->first << "\t\t2\t\t" << ite->second << endl;
}
}
int main()
{
init_Reserve(); //表初始化
Symbol.clear(); //标识符集初始化
Digit.clear(); //常数集初始化
index = 0;
character = ' ';
token = "";
//输入
cout << "输入待词法分析的源程序代码:@代表输入结束\n" << endl;
string in;
while (cin >> in && in != "@") {
in_str = in_str + " " + in;
}
//输出
Binary word(0, 0, "_"); //识别二元组初始化
cout << "\n------------------------识别结果------------------------" << endl;
//循环进行词法分析直到识别所有单词符号
while (index < in_str.size())
{
word = LexAnalyze();
if (word.type != 0)
{
if (word.type == 1) {
cout << "(" << Reserve[41] << "," <<"\""<< word.value<< "\""<< ")" << endl;
continue;
}
if (word.type == 2) {
cout << "(" << Reserve[42] << "," << word.value << ")" << endl;
continue;
}
if (word.type == 3) {
cout << "(" << Reserve[43] << "," << "\"" << word.value << "\"" << ")" << endl;
continue;
}
cout << "(" << Reserve[word.type + 30] << "," << word.value << ")" << endl;
}
}
cout << "\n------------------------词汇表展示------------------------\n" << endl;
show_table();
return 0;
}
// 注释的识别好像未完成?记不得了
/*
void main()
{
double sum = 0.0;
double x = 1.0;
while (x <= 100) sum = sum + x;
printf(“sum = %f\n”, sum);
}
@
void main()
{
double sum = 0;
double x = 1;
while (x <= 100) sum = sum + x;
printf(“sum = %f\n”, sum);
}
@
void main()
{
// compute 1 + 2 + … + 100
double sum = 0.0;
double x = 1.0;
while (x <= 100) sum = sum + x;
printf(“sum = %f\n”, sum);
}
@
*/
/* A test C program for scanner (这个是老师给的最终测试案例,若有不能识别的标识符等,请自行添加代码)
int main() {
double W, b;
double Y_predicted;
int passenger_id, survived, pclass;
W = 0.0;
b = 0.005;
Y_predicted = 1;
passenger_id = 1000L;
survived = 505u;
pclass = L'\10a0cc';
if (passenger_id >= 100)
W += 5.6372e-10;
else
b = 9.78f - 0.005 * W;
if (Y_predicted < 1)
passenger_id = 0X654E;
else
passenger_id = 0X054EL;
survived = 2 ^ pclass;
print("end");
}
@
*/
运行结果

















 455
455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









