







 本文深入探讨Flask-SQLAlchemy的高级操作技巧,包括复杂查询、数据更新与创建、多表关联、窗口函数使用及数据监听等,适用于希望提升数据库操作效率的开发者。
本文深入探讨Flask-SQLAlchemy的高级操作技巧,包括复杂查询、数据更新与创建、多表关联、窗口函数使用及数据监听等,适用于希望提升数据库操作效率的开发者。
1. 更新
# 批量更新某表多条数据的某些字段
HeTongTaiZhangLaoWu.query.filter_by(xiang_mu_id=xiang_mu_id).update({"is_delete": True})
# 批量更新某表不同数据不同字段,更新数据中需要有主键
update_data = [
{'id': 1, 'is_delete': True, 'name': '张三'},
{'id': 2, 'is_delete': False, 'age': 20}
]
# 注意这种方式并不能触发orm层级的更新,即涉及到关联关系的属性并不能更新,只能对本表内的属性进行更新
db.session.bulk_update_mappings(RenYuanXinXi, update_data)
# 更新单条数据
ren_yuan_xin_xi.name = '张三' # ren_yuan_xin_xi是数据库查询的实例化对象
跟新 Json 格式数据需要注意:
当更新json字段时,不能直接在该字段的基础上进行添加。例如:
def query():
obj = DangAnShiWenJian.query.filter(DangAnShiWenJian.id == 783).first()
obj.meta_info["new_key"] = "new_value"
db.session.commit()
这是因为数据库对象的json属性值本质上是一个指针,当修改json类型时(例如字段或者列表),因为是可变数据类型,导致指针所指向的数据结构发生变化,但是指针本身没有变化,这种情况数据库认为该值没有发生变化,于是没有将修改操作commit进数据库。
有两种解决方式:
- 重新定义一个新的dict或者list对象,可以使用copy或者new一个都可行。将新的对象赋值给数据库对象的json字段数据即可。
- 显式的声明该字段被修改了:使用sqlalchem orm中的flag_modified将某个字段显式的标记为已修改(该操作下,即使未对该字段进行修改,也会触发表的on_update更新功能)
from sqlalchemy.orm.attributes import flag_modified
def query():
obj = DangAnShiWenJian.query.filter(DangAnShiWenJian.id == 783).first()
obj.meta_info["new_key"] = "new_value"
flag_modified(obj, "meta_info")
db.session.commit()
2. 新增
# 创建一条
db.session.add(RenYuanXinXi(name='张三'))
# 批量创建数据,同表数据
create_data = [
{'name': '张三', 'age': 20},
{'name': '李四', 'age': 22},
]
# 注意这种方式并不能触发orm层级的更新,即涉及到关联关系的属性并不能新增,只能对本表内的属性进行新增
db.session.bulk_insert_mappings(RenYuanXinXi, create_data)
# 批量创建数据,不同表数据
create_data = []
create_data.append(RenYuanXinXi(name='张三'))
create_data.append(XiangMuYunXingZhiBiaoCanShuShiJianSheZhi(suo_shu_zu_zhi=1))
db.session.add_all(create_data)
3. 查询
3.1 查询的顺序
在Flask-SQLAlchemy中,查询语句的执行顺序并不是按照你在代码中写的顺序来执行的。实际上,查询语句的执行顺序是由SQLAlchemy的ORM(对象关系映射)层在后台处理的。
以下是一般的执行顺序:
- db.session.query():这是开始一个查询的起点,你在这里指定你想要查询的模型或者字段。
- filter():这个方法在查询中添加WHERE子句,用于过滤结果。
- group_by():这个方法在查询中添加GROUP BY子句,用于将结果集按照某个字段进行分组。
- 聚合函数(如db.func.max):这些函数通常在GROUP BY子句之后使用,用于对每个分组进行某种计算,如求最大值、最小值、平均值等。
- order_by():这个方法在查询中添加ORDER BY子句,用于对结果集进行排序。
- 调用 limit 和 offset 子句(如果有的话)。
- 最后,当你调用all()、first()等方法时,SQLAlchemy会将整个查询转换为SQL语句并在数据库中执行。
这个执行顺序是由SQL标准和SQLAlchemy的ORM层决定的,和你在代码中调用这些方法的顺序无关。你可以在代码中以任何顺序调用这些方法,SQLAlchemy会在后台正确地组织它们。
3.2 基本查询
# 查询符合条件的第一条, 没有返回None
ManYiDuDiaoChaShiJianSheZhi.query.filter(ManYiDuDiaoChaShiJianSheZhi.suo_shu_zu_zhi == zu_zhi_id, ManYiDuDiaoChaShiJianSheZhi.is_delete == false()).first()
# 查询符合条件的所有, 没有返回空的查询集
ManYiDuDiaoChaShiJianSheZhi.query.filter(ManYiDuDiaoChaShiJianSheZhi.suo_shu_zu_zhi == zu_zhi_id, ManYiDuDiaoChaShiJianSheZhi.is_delete == false()).all()
# 预加载数据
ManYiDuDiaoChaShiJianSheZhi.query.options(selectinload(ManYiDuDiaoChaShiJianSheZhi.can_shus)).filter(ManYiDuDiaoChaShiJianSheZhi.id == subquery).first()
3.3 查询id最大的一条数据
shi_jian = ManYiDuDiaoChaShiJianSheZhi.query.filter(ManYiDuDiaoChaShiJianSheZhi.suo_shu_zu_zhi == zu_zhi_id, ManYiDuDiaoChaShiJianSheZhi.is_delete == false()).order_by(ManYiDuDiaoChaShiJianSheZhi.id.desc()).first()
3.4 查询关联表id最大的所有数据
subquery = db.session.query(db.func.max(XiangMuYunXingZhiBiaoCanShuShiJianSheZhi.id)).filter(
XiangMuYunXingZhiBiaoCanShuShiJianSheZhi.suo_shu_xiang_mu == zu_zhi_id).scalar_subquery()
db_data = db_class.query.options(selectinload(db_class.xiang_mu_shi_jian_she_zhi)).filter(
db_class.suo_shu_xiang_mu_ == zu_zhi_id, db_class.shi_jian_she_zhi_id == subquery).all()
3.5 连接两表查询
subquery = db.session.query(db.func.max(XiangMuYunXingZhiBiaoCanShuShiJianSheZhi.id)).filter(
XiangMuYunXingZhiBiaoCanShuShiJianSheZhi.suo_shu_xiang_mu == zu_zhi_id).scalar_subquery()
db_data = db_class.query.join(XiangMuYunXingZhiBiaoCanShu).options(
selectinload(db_class.xiang_mu_shi_jian_she_zhi),
selectinload(db_class.xiang_mu_yun_xing_zhi_biao_can_shu)).filter(
db_class.suo_shu_xiang_mu_ == zu_zhi_id, db_class.shi_jian_she_zhi_id == subquery,
XiangMuYunXingZhiBiaoCanShu.zhi_biao_type == zhi_biao).all()
3.6 查询年龄在30以下、30-40、40-50、50以上的人数,人员按照身份证号码去重
nian_ling_ren_shu = (
db.session.query(
db.func.count().label("count"),
db.case(
(FenBaoShangRenYuanZhuCeBiao.nian_ling < 30, "30岁以下"),
(FenBaoShangRenYuanZhuCeBiao.nian_ling.between(30, 50), "30-50岁"),
(FenBaoShangRenYuanZhuCeBiao.nian_ling > 50, "50岁以上"),
else_="其他",
).label("nian_ling"),
)
.distinct(FenBaoShangRenYuanZhuCeBiao.shen_fen_zheng_hao_ma)
.group_by("nian_ling")
.all()
)
3.7 子查询构建指定数组内的数据
tong_ji_yue_fen_subquery = (
db.session.query(db.func.distinct(model.tong_ji_yue_fen))
.filter(
model.zu_zhi_id == 5,
model.tong_ji_yue_fen >= start_time,
model.tong_ji_yue_fen < end_time,
)
.scalar_subquery()
)
if data_type == "last":
filters.append(model.tong_ji_yue_fen.in_(tong_ji_yue_fen_subquery))
3.8 按照datetime类型日期,忽略时分秒分组
result = (
db.session.query(
YueDuWuZiXuQiuJiHua,
db.func.date_format(YueDuWuZiXuQiuJiHua.tong_ji_yue_fen, "%Y-%m-%d").label("day"),
db.func.sum(YueDuWuZiXuQiuJiHua.shu_liang).label("shu_liang_zong_ji"),
)
.filter(YueDuWuZiXuQiuJiHua.xiang_mu_id == xiang_mu_id, YueDuWuZiXuQiuJiHua.is_delete == false())
.group_by(YueDuWuZiXuQiuJiHua.md5, "day")
.all()
)
3.9 巧用多次子查询
# 子查询,log数据中按照bill_id分组,去除每组操作时间最晚数据,得到log_id列表
sub_query = (
db.session.query(AppDataWorkFlowLog.bill_id, db.func.max(AppDataWorkFlowLog.id).label("max_id"))
.filter(
AppDataWorkFlowLog.optid == current_user.id,
AppDataWorkFlowLog.status.in_(["PROCESSING", "FINISHED", "SENDBACK"]),
AppDataWorkFlowLog.biao_dan_type == biao_dan_type,
)
.group_by(AppDataWorkFlowLog.bill_id)
.subquery()
)
bill_ids = db.session.query(sub_query.c.bill_id).scalar_subquery()
workflow_bills = (
db.session.query(AppDataWorkFlowBill).filter(AppDataWorkFlowBill.id.in_(bill_ids), *bill_filters).all()
)
3.10 如果要根据某几个字段进行group_by,并且对某个字段求最大值,并找到最大值对应的数据
# 需要先建立子查询,然后根据子查询进行逐一字段匹配进行查询
sub_query = (
db.session.query(
GongChengZaoJiaTongJiDanXiangGongCheng.zu_zhi_id,
GongChengZaoJiaTongJiDanXiangGongCheng.dan_xiang_gong_cheng_id,
GongChengZaoJiaTongJiDanXiangGongCheng.zhuan_ye_lei_bie,
db.func.max(GongChengZaoJiaTongJiDanXiangGongCheng.tong_ji_yue_fen).label("max_date"),
)
.filter(
GongChengZaoJiaTongJiDanXiangGongCheng.zu_zhi_id.in_(xiang_mu_ids),
GongChengZaoJiaTongJiDanXiangGongCheng.is_delete == false(),
)
.group_by(
GongChengZaoJiaTongJiDanXiangGongCheng.zu_zhi_id,
GongChengZaoJiaTongJiDanXiangGongCheng.dan_xiang_gong_cheng_id,
GongChengZaoJiaTongJiDanXiangGongCheng.zhuan_ye_lei_bie,
)
.subquery()
)
current_app.logger.info(sub_query)
zu_zhi_id_and_max_date = (
db.session.query(
GongChengZaoJiaTongJiDanXiangGongCheng,
)
.filter(
GongChengZaoJiaTongJiDanXiangGongCheng.is_delete == false(),
GongChengZaoJiaTongJiDanXiangGongCheng.zu_zhi_id == sub_query.c.zu_zhi_id,
GongChengZaoJiaTongJiDanXiangGongCheng.dan_xiang_gong_cheng_id == sub_query.c.dan_xiang_gong_cheng_id,
GongChengZaoJiaTongJiDanXiangGongCheng.zhuan_ye_lei_bie == sub_query.c.zhuan_ye_lei_bie,
GongChengZaoJiaTongJiDanXiangGongCheng.tong_ji_yue_fen == sub_query.c.max_date,
)
.all()
)
current_app.logger.info(zu_zhi_id_and_max_date)
3.11 过滤某个字符串类型的字段不包含“-”的数据
data = GongChengChengBenZhengTiHeSuanGcxm.query.filter(
GongChengChengBenZhengTiHeSuanGcxm.is_delete == false(),
GongChengChengBenZhengTiHeSuanGcxm.tong_ji_yue_fen >= start_time,
GongChengChengBenZhengTiHeSuanGcxm.tong_ji_yue_fen <= end_time,
GongChengChengBenZhengTiHeSuanGcxm.xiang_mu_id == zu_zhi_id,
GongChengChengBenZhengTiHeSuanGcxm.cheng_ben_bian_ma.notlike("%-%"),
).all()
3.12 多对多关联对象过滤查询
zhu_ce_biao_filters.append(
FenBaoShangRenYuanZhuCeBiao.shi_yong_bu_wei.any(
DanXiangGongCheng.id== shi_yong_bu_wei_id_
)
)
# 注意如果any中的过滤条件需要多个的话,需要使用and_方法,否则会报错,因为any只接受两个位置参数
# 且只有第一个参数是用来写过滤条件的,第二个参数是用来在第一个参数的基础上添加更多的过滤条件的
# 例如:
filters = [
FenBaoShangRenYuanZhuCeBiao.xiang_mu_id == zu_zhi_id,
FenBaoShangRenYuanZhuCeBiao.is_delete == false(),
FenBaoShangRenYuanZhuCeBiao.data_source == "zhu_ce_biao",
]
wen_hua_cheng_du = (
db.session.query(
db.func.count(db.func.distinct(LaoWuGeRenWeiDangAnJiBenXinXi.shen_fen_zheng_hao_ma)).label("count"),
db.case(
(LaoWuGeRenWeiDangAnJiBenXinXi.xue_li == "xiao_xue", "小学"),
(LaoWuGeRenWeiDangAnJiBenXinXi.xue_li == "chu_zhong", "初中"),
(LaoWuGeRenWeiDangAnJiBenXinXi.xue_li == "gao_zhong", "高中"),
(
LaoWuGeRenWeiDangAnJiBenXinXi.xue_li.in_(["yan_jiu_sheng", "da_xue_zhuan_ke", "da_xue_ben_ke"]),
"高中以上",
),
).label("wen_hua_cheng_du"),
)
.filter(LaoWuGeRenWeiDangAnJiBenXinXi.fen_bao_shang_ren_yuan_zhu_ce_biaos.any(and_(*filters)))
.group_by("wen_hua_cheng_du")
.all()
)
3.13 在session.query中格式化datetime类型字段
liu_shui_dan_yue_fen = (
db.session.query(
liu_shui_model.xiang_mu_id,
db.func.date_format(liu_shui_model.tong_ji_yue_fen, "%Y-%m").label("tong_ji_yue_fen"),
)
.distinct()
.all()
)
4. 枚举
4.1 根据枚举值获取枚举常量
class ShiYongDanWeiType(enum.Enum):
lao_wu_fen_bao = '劳务分包'
zhuan_ye_fen_bao = '专业分包'
zong_bao_dan_wei = '总包单位'
qi_ta_dan_wei = '其他单位'
# 得到枚举常量
ShiYongDanWeiType('总包单位') # 通过value获得
ShiYongDanWeiType.zong_bao_dan_wei
ShiYongDanWeiType["zong_bao_dan_wei"] # 通过name获得
# 获取枚举key
ShiYongDanWeiType.lao_wu_fen_bao.name # 返回 lao_wu_fen_bao 字符串
# 获取枚举value
ShiYongDanWeiType.lao_wu_fen_bao.value # 返回 劳务分包 字符串
# 枚举类查询
class ZhaoTouBiaoWenJianType(enum.Enum):
zhao_biao_wen_jian = '招标文件'
tou_biao_wen_jian = '投标文件'
ZhaoTouBiaoWenJian.query.filter(ZhaoTouBiaoWenJian.wen_jian_lei_xing == 'zhao_biao_wen_jian').all()
5. 打印
.__dict__
# db.session.query方式查询出来的数据打印
._asdict()
# 打印 SQL 语句
print(db.session.query(*querys).filter(*filters).group_by(*group_by).statement)
# 打印查询参数
print(db.session.query(*querys).filter(*filters).group_by(*group_by).params)
6. 其他场景
6.1 创建或更新后立即获取新数据的相关属性
# 创建
record=[]
dan_xiang_gong_chengs=[
{
"suo_shu_xiang_mu": 1,
},
{
"suo_shu_xiang_mu": 2,
}
]
for obj in dan_xiang_gong_chengs:
record.append(DanXiangGongCheng(**obj))
db.session.add_all(record)
db.session.commit()
for obj in record:
print('+++++++++++++++',obj.id)
# 更新
db_objs = DanXiangGongCheng.query.filter(DanXiangGongCheng.id.in_([4,5])).all()
for obj in db_objs:
# ㎡
obj.gui_mo_dan_wei='m'
db.session.commit()
for obj in db_objs:
print(obj.gui_mo_dan_wei)
当需要获取日期类型的属性时,上述方式有一个需要注意的点:
# 创建
record = []
dan_xiang_gong_chengs = [
{
"suo_shu_xiang_mu": 1,
"created_at": "2021-01-01",
},
{
"suo_shu_xiang_mu": 2,
},
]
for obj in dan_xiang_gong_chengs:
record.append(DanXiangGongCheng(**obj))
db.session.add_all(record)
db.session.flush()
for obj in record:
print("+++++++++++++++", type(obj.created_at))
这种情况下,第一次会输出<class 'str'>,第二次会输出<class 'datetime.datetime'>。也就是说,手动创建时间类型的数据时,flush之后,自己创建时是什么类型,获取到的还是什么类型;数据库默认创建的时间类型是datetime类型的。
6.2 多对多关系的增加与修改
# 增加
dan_xiang_gong_chengs = DanXiangGongCheng.query.filter(DanXiangGongCheng.id.in_([1, 2])).all()
data = {"min_zu": "汉族", "shi_yong_bu_wei": dan_xiang_gong_chengs}
db_data = FenBaoShangRenYuanZhuCeBiao(**data)
db.session.add(db_data)
db.session.commit()
# 修改
dan_xiang_gong_chengs = DanXiangGongCheng.query.filter(DanXiangGongCheng.id.in_([4, 5])).all()
data = {"min_zu": "傣族", "shi_yong_bu_wei": dan_xiang_gong_chengs}
db_data = FenBaoShangRenYuanZhuCeBiao.query.filter_by(id=128).first()
for key, value in data.items():
setattr(db_data, key, value)
db.session.commit()
6.3 数据监听
使用sqlalchemy 中的event 接口进行表操作监听,可以使用event.listen() 或者event.listens_for() 装饰器
- 使用限制:只有单个插入数据,或者obj.field_name = new_value 的更新方式能够触发listen,其他的更新或插入方式无法触发
- 如果回调函数中是对数据库对象本身进行操作,那么操作完后不需要单独提交事务
# 定义 事件监听器函数,在 插入/更新 数据之前计算
def calculate_xiang_mu_gai_kuang(mapper, connection, target):
if target.mate_info is None:
target.mate_info = {"illegal_fields": []}
if "illegal_fields" not in target.mate_info:
target.mate_info["illegal_fields"] = []
fields_to_check = ["ben_qi_ji_hua_wan_cheng_lv", "lei_ji_ji_hua_wan_cheng_lv"]
for field in fields_to_check:
if getattr(target, field) is None:
if field not in target.mate_info["illegal_fields"]:
target.mate_info["illegal_fields"].append(field)
else:
if field in target.mate_info["illegal_fields"]:
target.mate_info["illegal_fields"].remove(field)
# 将事件监听器与数据模型关联
event.listen(XiangMuGaiKuang, "before_insert", calculate_xiang_mu_gai_kuang, propagate=True)
使用listens_for 装饰器举例
listens_for 中需要指定需要监听的字段,如果有多个字段,可以使用多个装饰器
@event.listens_for(DanXiangGongCheng.ji_chu_lei_xing, "set")
def on_ren_yuan_xin_xi_changed(target, value, old_value, initiator):
print(11111)
target.is_tong_bu_super = false()
6.4 通过query语句获取当前查询model
query.column_descriptions[0]["type"]
# 或者
query.column_descriptions[0]["expr"]
6.5 通过字符串形式的模型名,获取模型类
db.Model.registry._class_registry.get("ZuZhiXinXi")
6.6 Float 和 Decimal 类型数据查询结果的类型受查询方式影响
案例:
res1 = LaoWuGongRenYongGongTongJi.query.get(1)
res2 = db.session.query(
db.func.sum(LaoWuGongRenYongGongTongJi.ben_qi_qi_chu_ren_shu).label("ben_qi_qi_chu_ren_shu")
).first()
print("------打印调试信息------", type(res1.ben_qi_qi_chu_ren_shu))
print("------打印调试信息------", type(res2.ben_qi_qi_chu_ren_shu))
结果:
------打印调试信息------ <class 'int'>
------打印调试信息------ <class 'decimal.Decimal'>
原因:
res1 和 res2 获取的数据类型不同是因为它们查询数据的方式不同,导致了 SQLAlchemy 在处理结果时使用了不同的数据类型。
对于 res1,直接使用.query.get(1)从 LaoWuGongRenYongGongTongJi 模型获取一个实例。在这种情况下,ben_qi_qi_chu_ren_shu 字段的类型由该模型定义。如果模型中 ben_qi_qi_chu_ren_shu 被定义为整数类型(如 Integer ),那么查询结果中res1.ben_qi_qi_chu_ren_shu的类型就是 int 。
对于 res2,你使用了db.session.query()配合db.func.sum()进行了聚合查询。在 SQLAlchemy 中,当你对某列进行聚合操作(如求和)时,默认情况下,结果可能会被处理为 Decimal 类型,这是为了保证数值运算的精度。因此,即使原始数据是整数类型,聚合后的结果 res2.ben_qi_qi_chu_ren_shu 也可能是 decimal.Decimal 类型。
这种类型差异是由于 SQLAlchemy 和底层数据库如何处理聚合函数的结果决定的。Decimal 类型提供了精确的小数运算,这在处理财务数据时特别有用,但它可能与 Python 的内置 int 类型在行为上有所不同。
6.7 通过relationship加载关联对象时,获取这个关联对象的模型
@classmethod
def get_last_data(cls, zu_zhi_id, deadline=None, relationship_keys=None):
if relationship_keys is None:
relationship_keys = cls.relationship_keys
filters = [getattr(cls, cls.zu_zhi_key) == zu_zhi_id, cls.is_avilable == true(), cls.is_delete == false()]
if deadline:
filters.append(cls.shu_wen_jian_created_at < deadline)
options = []
for relationship_key in relationship_keys:
relationship_attr = getattr(cls, relationship_key)
# 获取关联对象的模型
related_model = relationship_attr.property.mapper.class_
options.append(selectinload(relationship_attr.and_(related_model.is_delete == false())))
shi_jian_she_zhi = (
cls.query.options(*options).filter(*filters).order_by(cls.shu_wen_jian_created_at.desc()).first()
)
return shi_jian_she_zhi
6.8 利用窗口函数进行复杂的分组排序查询
我需要按照身份证号码分组,在每个分组内无退场日期的优先被取到,如果有退场日期,退场日期更晚的会优先被取到。
# 去重逻辑:同一个身份证如果有多条记录的时候,如果有无退场日期的登记记录,就取无退场日期的,如果没有,就取退场日期靠后的一条记录的数据
if is_deduplicate:
rn_subquery = (
db.session.query(
FenBaoShangRenYuanZhuCeBiao.id,
func.row_number()
.over(
partition_by=FenBaoShangRenYuanZhuCeBiao.shen_fen_zheng_hao_ma,
order_by=[
case((FenBaoShangRenYuanZhuCeBiao.tui_chang_ri_qi.is_(None), 0), else_=1),
FenBaoShangRenYuanZhuCeBiao.tui_chang_ri_qi.desc(),
],
)
.label("rn"),
)
.filter(
FenBaoShangRenYuanZhuCeBiao.xiang_mu_id == xiang_mu_id,
FenBaoShangRenYuanZhuCeBiao.is_delete == false(),
*args,
)
.subquery()
)
# 从子查询中选择序号为1的记录
subquery = (db.session.query(rn_subquery.c.id).filter(rn_subquery.c.rn == 1)).scalar_subquery()
else:
subquery = (
db.session.query(FenBaoShangRenYuanZhuCeBiao.id)
.filter(
FenBaoShangRenYuanZhuCeBiao.xiang_mu_id == xiang_mu_id,
FenBaoShangRenYuanZhuCeBiao.is_delete == false(),
*args,
)
.scalar_subquery()
)
options.extend(
[
selectinload(FenBaoShangRenYuanZhuCeBiao.fen_bao_shang),
selectinload(FenBaoShangRenYuanZhuCeBiao.he_tong_feng_mian),
]
)
# 执行查询
results = (
FenBaoShangRenYuanZhuCeBiao.query.options(*options).filter(FenBaoShangRenYuanZhuCeBiao.id.in_(subquery)).all()
)
这段查询是利用了sql中的窗口函数实现的。row_number() 是一个窗口函数,它为每个分区内的行分配一个唯一的序号,根据指定的排序顺序。
这里的窗口函数通过.over()方法定义了其作用的窗口。窗口由两部分指定:
partition_by=FenBaoShangRenYuanZhuCeBiao.shen_fen_zheng_hao_ma:这指定了窗口函数的分区依据,即在这个例子中,数据会根据 shen_fen_zheng_hao_ma(身份证号码)进行分组,每组数据独立应用窗口函数。
order_by=[...]:这定义了每个分区内数据的排序方式。在这个例子中,首先根据 tui_chang_ri_qi(退场日期)是否为空进行排序(空值在前),然后在退场日期非空的情况下,根据退场日期进行降序排序。
通过这种方式,row_number() 为每个分区内的行分配一个序号,序号根据 order_by 中定义的排序规则递增。然后,通过外层查询选择每个分区中序号为1的记录,这通常用于选择每个分组中根据某种排序逻辑“最顶端”的记录。
需要注意的是case函数中的0或1只是为了划分优先级,0的优先级更高,而FenBaoShangRenYuanZhuCeBiao.tui_chang_ri_qi.desc()是在同优先级的情况下,选取退场日期更晚的记录在前。
6.9 启用SQLAlchemy日志
def test_sql():
# 启用SQLAlchemy日志
logging.basicConfig()
logging.getLogger("sqlalchemy.engine").setLevel(logging.INFO)
HOST = "127.0.0.1"
PORT = "3306"
DATABASE = "6023_xm"
USERNAME = "root"
PASSWORD = "root"
start_time = datetime.now()
# 创建数据库引擎
engine = create_engine(
"mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8mb4".format(USERNAME, PASSWORD, HOST, PORT, DATABASE)
)
Session = sessionmaker(bind=engine)
session = Session()
打印日志记录同时附带堆栈信息:
import logging
from datetime import datetime
import traceback
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from applications.scheduled_tasks.shu_ju_ku.shu_ju_ku_task import UpdateShuJuKu
from applications.shu_ju_ku_handler.gong_cheng_jing_ji_ji_shu_zhi_biao_handler import (
QYGongChengJingJiZhiBiaoDanXiangGongChengHandler,
)
from flask import current_app
def test_():
test_sql()
# 自定义日志处理器
class StackTraceLoggingHandler(logging.FileHandler):
# 重写emit方法,每次触发日志记录时,将当前的调用栈信息记录到日志文件中
def emit(self, record):
stack = traceback.format_stack()
record.stack_info = "".join(stack)
super().emit(record)
def test_sql():
# 将配置日志文件输入到文件中
handler = StackTraceLoggingHandler("my_log.log")
# 配置Flask的日志记录器(将flask中的打印信息捕获到)
logger = current_app.logger # 获取Flask的日志记录器
handler.setLevel(logging.INFO) # 设置日志级别
logger.addHandler(handler) # 添加日志处理器
# 配置 SQLAlchemy 的日志记录器(将SQLAlchemy中的打印信息捕获到)
sqlalchemy_logger = logging.getLogger("sqlalchemy.engine") # 获取SQLAlchemy的日志记录器
sqlalchemy_logger.setLevel(logging.INFO) # 设置日志级别
sqlalchemy_logger.addHandler(handler) # 添加日志处理器
HOST = "127.0.0.1"
PORT = "3306"
DATABASE = "6023_xm"
USERNAME = "root"
PASSWORD = "root"
# 创建数据库引擎
engine = create_engine(f"mysql+pymysql://{USERNAME}:{PASSWORD}@{HOST}:{PORT}/{DATABASE}?charset=utf8mb4")
start_time = datetime.now()
# 执行一个简单的查询以触发事件监听器
Session = sessionmaker(bind=engine)
session = Session()
# UpdateShuJuKu.qy_sjk_update()
QYGongChengJingJiZhiBiaoDanXiangGongChengHandler.update_on_time(1)
end_time = datetime.now()
# 使用 Flask 日志打印信息
logger.info(f"总耗时: {end_time - start_time}")
session.close()
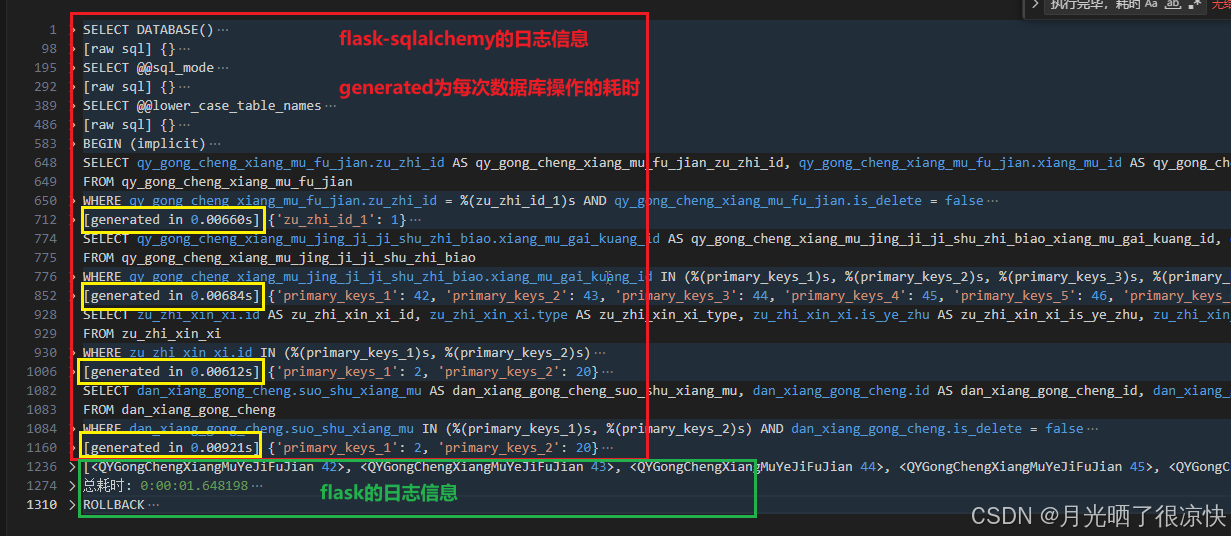
目前以及确定 [generated in xxxs] 相关字样并不是每次操作数据库的耗时,而是构建查询字符串的耗时,上图中的红字部分有错误。至于如何通过SQL Alchemy自带的日志工具得到数据库操作的耗时,我还不清楚。

















 5145
5145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









