







我们这里说的八大排序是内部排序。
1.算法分类
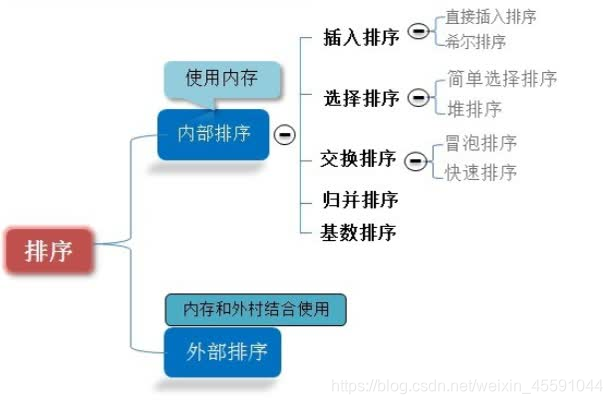
当n较大,则应采用时间复杂度为O(nlog2n)的排序方法:快速排序、堆排序或归并排序序。
快速排序:是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短;
2.算法复杂度
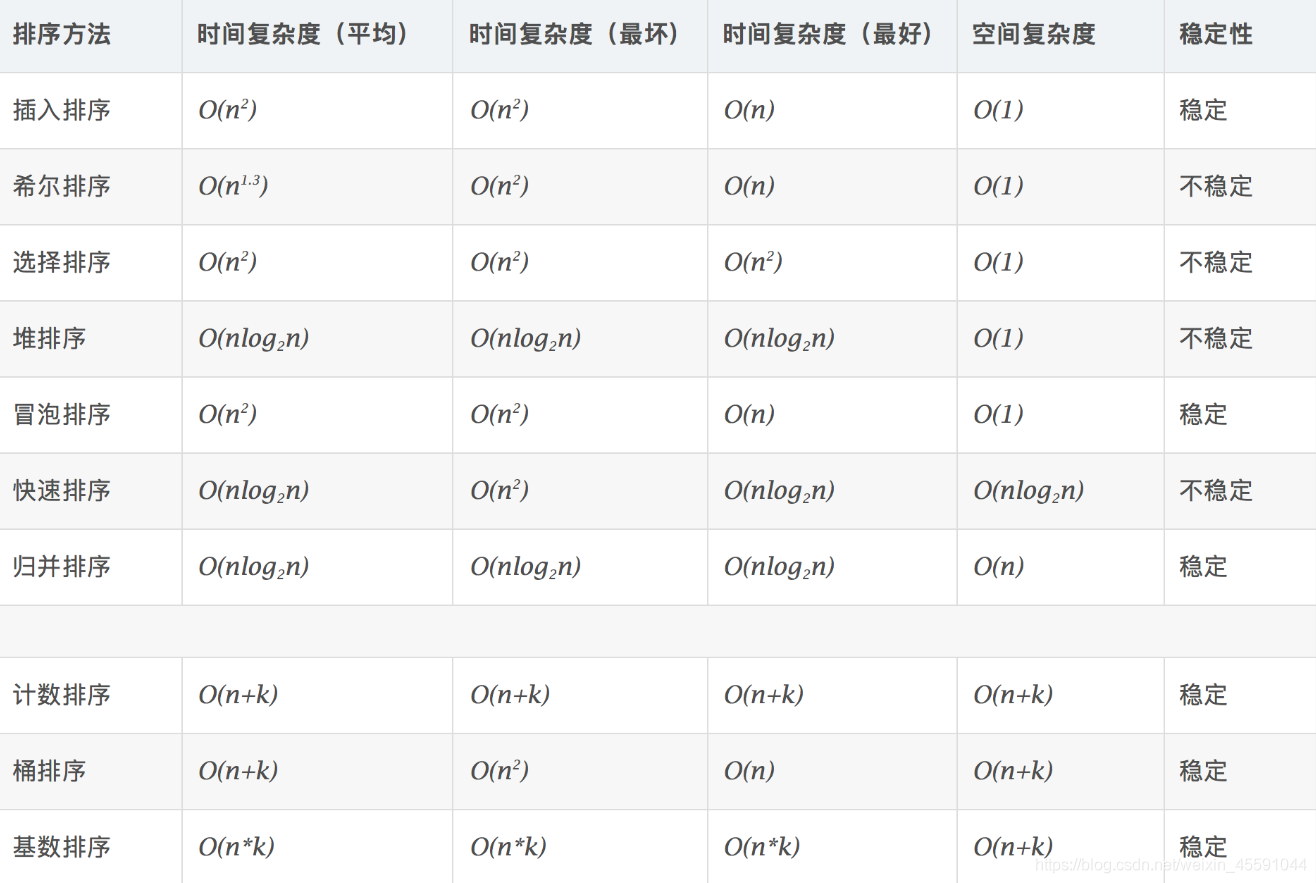
3.相关概念
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
1、冒泡排序(Bubble Sort)

算法实现:
void bubbleSort(int a[], int n){
for(int i =0 ; i< n-1; ++i) {
for(int j = 0; j < n-i-1; ++j) {
if(a[j] > a[j+1])
{
int tmp = a[j] ; a[j] = a[j+1] ; a[j+1] = tmp;
}
}
}
}
1.2冒泡排序算法的改进
对冒泡排序常见的改进方法是加入一标志性变量exchange,用于标志某一趟排序过程中是否有数据交换,如果进行某一趟排序时并没有进行数据交换,则说明数据已经按要求排列好,可立即结束排序,避免不必要的比较过程。本文再提供以下两种改进算法:
1.设置一标志性变量pos,用于记录每趟排序中最后一次进行交换的位置。由于pos位置之后的记录均已交换到位,故在进行下一趟排序时只要扫描到pos位置即可。
改进后算法如下:
void Bubble_1 ( int r[], int n) {
int i= n -1; //初始时,最后位置保持不变
while ( i> 0) {
int pos= 0; //每趟开始时,无记录交换
for (int j= 0; j< i; j++)
if (r[j]> r[j+1]) {
pos= j; //记录交换的位置
int tmp = r[j]; r[j]=r[j+1];r[j+1]=tmp;
}
i= pos; //为下一趟排序作准备
}
}
2.传统冒泡排序中每一趟排序操作只能找到一个最大值或最小值,我们考虑利用在每趟排序中进行正向和反向两遍冒泡的方法一次可以得到两个最终值(最大者和最小者) , 从而使排序趟数几乎减少了一半。
改进后的算法实现为:
void Bubble_2 ( int r[], int n){
int low = 0;
int high= n -1; //设置变量的初始值
int tmp,j;
while (low < high) {
for (j= low; j< high; ++j) //正向冒泡,找到最大者
if (r[j]> r[j+1]) {
tmp = r[j]; r[j]=r[j+1];r[j+1]=tmp;
}
--high; //修改high值, 前移一位
for ( j=high; j>low; --j) //反向冒泡,找到最小者
if (r[j]<r[j-1]) {
tmp = r[j]; r[j]=r[j-1];r[j-1]=tmp;
}
++low; //修改low值,后移一位
}
}
2、简单选择排序(Simple Selection Sort)

算法实现:
#include<iostream>
#include<time.h>
#include <stdio.h>
#include <stdlib.h>
using namespace std;
const int N = 10000;
const int MAX = 10000000;
//选择排序
void SelectSort(double a[], int N) {
int min;
for (int i = 0; i < N - 1; i++) {
min = i;
for (int j = i + 1; j < N; j++) {
if (a[j] < a[min])
min = j;
}
swap(a[i], a[min]);
}
}
//主函数
double arr[N];
int main() {
//随机播种
srand((unsigned)time(NULL));
for (int i = 0; i < N; ++i) {
arr[i] = rand() % MAX;
}
clock_t start_time = clock();
{
SelectSort(arr, N);
}
clock_t end_time = clock();
printf("测试时间: %lfms\n", static_cast<double>(end_time - start_time) / CLOCKS_PER_SEC * 1000);
return 0;
}
2.1简单选择排序的改进——二元选择排序
简单选择排序,每趟循环只能确定一个元素排序后的定位。我们可以考虑改进为每趟循环确定两个元素(当前趟最大和最小记录)的位置,从而减少排序所需的循环次数。改进后对n个数据进行排序,最多只需进行[n/2]趟循环即可。具体实现如下:
void selectSort(int a[],int len) {
int i,j,min,max,tmp;
for(i=0; i<len/2; i++){ // 做不超过n/2趟选择排序
min = max = i;
for(j=i+1; j<=len-1-i; j++){
//分别记录最大和最小关键字记录位置
if(a[j] > a[max]){
max = j;
continue;
}
if(a[j] < a[min]){
min = j;
}
}
//该交换操作还可分情况讨论以提高效率
if(min != i){//当第一个为min值,不用交换
tmp=a[min]; a[min]=a[i]; a[i]=tmp;
}
if(min == len-1-i && max == i)//当第一个为max值,同时最后一个为min值,不再需要下面操作
continue;
if(max == i)//当第一个为max值,则交换后min的位置为max值
max = min;
if(max != len-1-i){//当最后一个为max值,不用交换
tmp=a[max]; a[max]=a[len-1-i]; a[len-1-i]=tmp;
}
print(a,len, i);
}
}
3、插入排序(Insertion Sort)

算法实现:
#include<iostream>
#include<time.h>
#include <stdio.h>
#include <stdlib.h>
using namespace std;
const int N = 10000000;
const int MAX = 10000000;
int space = 2;
//希尔排序
void ShellSort(double a[], int N) {
int i,j,num=0;
int step = N / space + 1;//当N<space时,step至少为1。
while (step >= 1) {
for (i = step; i < N; i++) {//分组进行插入排序
num = a[i];//暂存当前元素值
j = i-step;
while (j >= 0 && num < a[j]) {
a[j+step] = a[j];
j -= step;
}
a[j+step] = num;
}
step = step / space;
}
}
//主函数
double arr[N];
int main() {
//随机播种
srand((unsigned)time(NULL));
for (int i = 0; i < N; ++i) {
arr[i] = rand() % MAX;
}
clock_t start_time = clock();
{
ShellSort(arr, N);//希尔排序
}
clock_t end_time = clock();
printf("测试时间: %lfms\n", static_cast<double>(end_time - start_time) / CLOCKS_PER_SEC * 1000);
return 0;
}
4、希尔排序(Shell Sort)

5、归并排序(Merge Sort)

算法实现:
/*
二路归并排序算法:1.对数组进行划分;
2.对划分的数组进行排序;
3.对两个有序数组合并成为一个有序数组;
4.重复2.3操作至成为一个有序数组。
算法稳定
平均时间复杂度:O(nlog(2)n);
*/
#include<iostream>
using namespace std;
//比较相邻序列并进行合并
void Merge(double a[], double temp[], int start, int mid, int ed) {
int i = start, t = start;
int j = mid + 1;
while (i != mid + 1 && j != ed + 1) {
if (a[i] <= a[j]) {
temp[t++] = a[i++];
}
else {
temp[t++] = a[j++];
}
}
//剩下元素按原排列依次放入序列中
while (i != mid + 1)
temp[t++] = a[i++];
while (j != ed + 1)
temp[t++] = a[j++];
//更新数组
for (i = start; i <= ed; i++)
a[i] = temp[i];
}
void mergeSort(double a[], double temp[], int start, int ed) {
int mid;
if (start < ed) {
//避免堆栈溢出
mid = start + (ed - start) / 2;
//递归
mergeSort(a, temp, start, mid);
mergeSort(a, temp, mid+1, ed);
Merge(a, temp, start, mid, ed);
}
}
//主函数
int main() {
double a[100]; //定义大小为100的数组
int N; //元素的实际个数
cin >> N; //输入元素个数
for (int i = 0; i < N; i++)
cin >> a[i];
double temp[100];
mergeSort(a, temp, 0, N - 1);//二路归并排序算法
//输出
for (int i = 0; i < N; i++)
cout << a[i] << " ";
cout << endl;
return 0;
}
6、快速排序(Quick Sort)

算法实现:
/*
快速排序算法:1.选择一个元素(通常数组第一个元素)作为中轴元素;
2.将剩下的元素与中轴元素比较,分别置换到中轴元素两边;
3.将左边子数组和右边子数组看成两个新的数组,重复以上步骤,直到子数组元素数≤1。
算法不稳定
平均时间复杂度:O(nlog(2)n);
*/
#include<iostream>
using namespace std;
int a[200001]; //定义大小为200001的数组
int Partition(int a[], int l, int r) {
int i = l, j = r;
int temp = a[i];
while (i < j) {
//从右边开始找小于temp的元素
while (i < j && a[j] >= temp)
j--;
if (i < j) {//将找到的元素替换到数组最左边
a[i] = a[j];
i++;
}
//从左边开始找大于temp的元素
while (i < j && a[i] <= temp)
i++;
if (i < j) {//替换到数组最右边小于temp的元素位置
a[j] = a[i];
j--;
}
}
a[i] = temp;
return i;
}
void quickSort(int a[], int l, int r) {
if (l >= r) {
return;
}
int i = Partition(a, l, r);
quickSort(a, l, i - 1);
quickSort(a, i + 1, r);
}
//主函数
int main() {
int N; //元素的实际个数
cin >> N; //输入元素个数
for (int i = 0; i < N; i++)
cin >> a[i];
quickSort(a,0,N-1);//快速排序
//输出
for (int i = 0; i < N-1; i++)
cout << a[i] << " ";
cout << a[N-1];
return 0;
}
7、堆排序(Heap Sort)

算法实现:
/*
堆排序算法:1.将n个元素组成的无序序列构建一个大/小根堆;
2.交换堆尾元素和堆首元素,使堆尾元素为最大元素;
3.将前n-1个元素组成的无序序列调整为大/小根堆;
4.重复执行2、3至序列有序。
算法不稳定
平均时间复杂度:O(nlog(2)n);
*/
#include<iostream>
using namespace std;
void adjust(double a[], int length, int top) {
int left = top * 2 + 1;//左子节点
int right = top * 2 + 2;//右子节点
int root = top;
if (left<length && a[left]>a[root])
root = left;
if (right<length && a[right]>a[root])
root = right;
if (root != top) {//若最大值不是父节点,则交换
swap(a[root], a[top]);
adjust(a, length, root);
}
}
void HeapSort(double a[], int N) {
//构建大根堆
for (int i = N / 2 - 1; i >= 0; i--) {
adjust(a, N, i);
}
//调整大根堆
for (int i = N - 1; i > 0; i--) {
swap(a[0], a[i]);
adjust(a, i, 0);
}
}
//主函数
int main() {
double a[100]; //定义大小为100的数组
int N; //元素的实际个数
cin >> N; //输入元素个数
for (int i = 0; i < N; i++)
cin >> a[i];
HeapSort(a, N);
//输出
for (int i = 0; i < N; i++)
cout << a[i] << " ";
cout << endl;
return 0;
}
8、基数排序(Counting Sort)

算法实现:
/*
基排序算法:1.取得数组中的最大数,并取得位数置;
2.按照低位先排序,然后收集;再按照高位排序,然后再收集;
3.依次类推,直到最高位。
算法稳定
平均时间复杂度:O(n+k)
*/
#include<iostream>
using namespace std;
//计算数组中最大元素的位数
int mBit(int a[], int N) {
int dnum = 1;//表示数组中最大数的位数
int m = 10;
for (int i = 0; i < N; i++) {
while (a[i] >= m) {
m = m * 10;
dnum++;
}
}
return dnum;
}
//基排序
void radixSort(int a[], int N) {
int mb = mBit(a, N);
int temp[100];
int i, j, k;
int radix = 1;
int count[10] ;
for (i = 1; i <= mb; i++) {
for (j = 0; j < 10; j++) {
count[j] = 0;
}
for (j = 0; j < N; j++) {
k = (a[j] / radix) % 10;
count[k]++;
}
for (j = 1; j < 10; j++) {
count[j] = count[j - 1] + count[j];
}
for (j = N - 1; j >= 0; j--) {//将桶中记录依次收集在temp
k = (a[j] / radix) % 10;
temp[count[k] - 1] = a[j];
count[k]--;
}
for (j = 0; j < N; j++) {
a[j] = temp[j];
}
radix = radix * 10;
}
}
//主函数
int main() {
int a[100]; //定义大小为100的数组
int N; //元素的实际个数
cin >> N; //输入元素个数
for (int i = 0; i < N; i++)
cin >> a[i];
radixSort(a, N);//基排序算法
//输出
for (int i = 0; i < N; i++)
cout << a[i] << " ";
cout << endl;
return 0;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









