






 该文使用Python实现随机森林分类方法,通过训练和测试数据集评估模型准确性。利用RobustScaler进行数据标准化,比较了10个和100个决策树的模型表现。此外,还展示了混淆矩阵、分类报告、ROC曲线和AUC值,以及运用交叉验证进一步验证模型性能。
该文使用Python实现随机森林分类方法,通过训练和测试数据集评估模型准确性。利用RobustScaler进行数据标准化,比较了10个和100个决策树的模型表现。此外,还展示了混淆矩阵、分类报告、ROC曲线和AUC值,以及运用交叉验证进一步验证模型性能。
#Python的随机森林分类方法预测
#导入所需的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score,classification_report,confusion_matrix,roc_auc_score
import warnings
warnings.filterwarnings('ignore')
#读取文件
df=pd.read_csv('H:/CSV/Dataset.csv')
#Y是因变量,X是自变量
X = df.drop(['Purchased'],axis=1)
y = df['Purchased']
#训练集和测试集的划分呢
X_train,X_test,y_train,y_test = train_test_split(X,y, test_size=0.2,random_state=4)
#RobustScaler 数据的标准化选择的是RobustScaler方法
from sklearn.preprocessing import RobustScaler
cols=X_train.columns
scaler = RobustScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
X_train = pd.DataFrame(X_train, columns=[cols])
X_test = pd.DataFrame(X_test, columns=[cols])
#计算10个决策树模型拟合的准确度
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=10,random_state=0)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print('10个决策树的模型准确率得分 : {0:0.4f}'. format(accuracy_score(y_test, y_pred)))
#计算100个决策树模型拟合的准确度
rfc_100 = RandomForestClassifier(n_estimators=100, random_state=0)
rfc_100.fit(X_train, y_train)
y_pred_100 = rfc_100.predict(X_test)
print('100个决策树的模型准确率得分 : {0:0.4f}'. format(accuracy_score(y_test, y_pred_100)))
#测试集和训练集的精度得分
y_pred = model.predict(X_test)
y_pred_train = model.predict(X_train)
from sklearn.metrics import accuracy_score
print("测试集模型精度 : {0:0.4f}".format(accuracy_score(y_test,y_pred)))
print("训练集模型精度 : {0:0.4f}".format(accuracy_score(y_train,y_pred_train)))
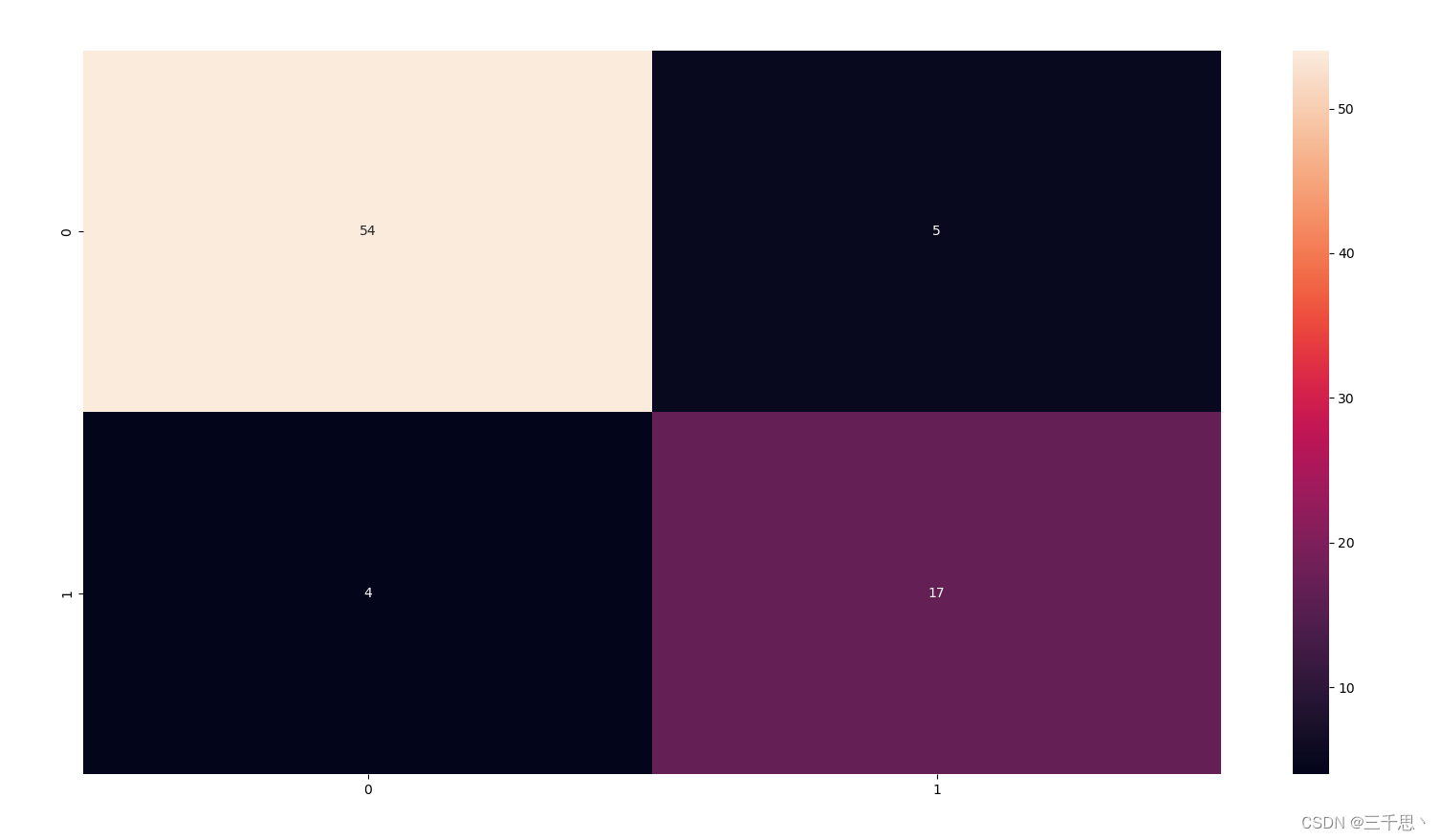
#混淆矩阵以及分类报告
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test,y_pred)
print('混淆矩阵\n\n',cm)
print('\n真阳性(TP) = ', cm[0,0])
print('\n真阴性(TN) = ', cm[1,1])
print('\n假阳性(FP) = ', cm[0,1])
print('\n假阴性(FN) = ', cm[1,0])
sns.heatmap(cm,annot= True, fmt='d', cmap='rocket')
#plt.show()
from sklearn.metrics import classification_report
print(classification_report(y_test,y_pred))
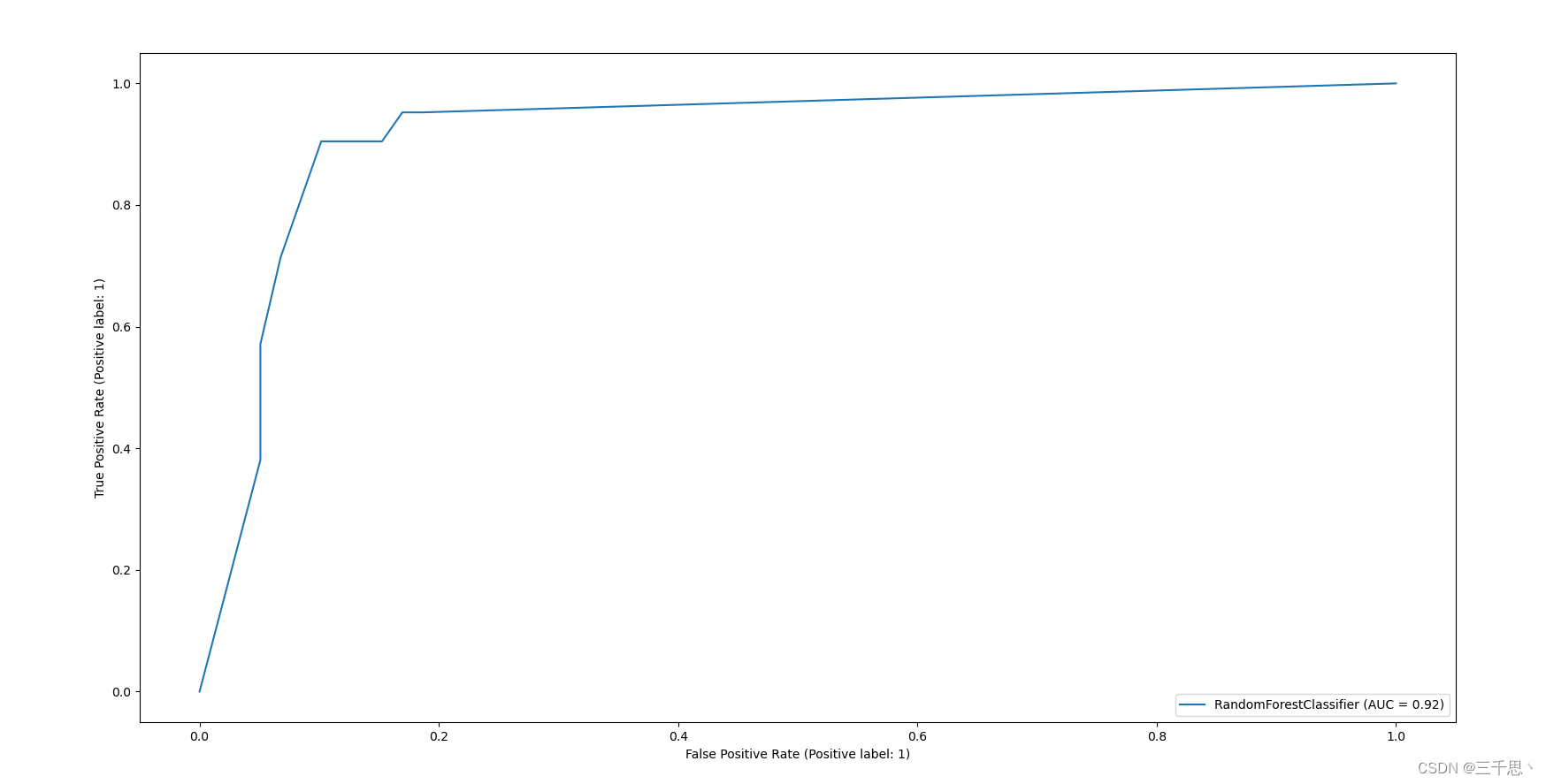
#看下ROC曲线和AUC值
#从sklearn中导入metrics 这个库里面有roc曲线的函数,直接调用就行
#ROC曲线就可看着敏感性分析 我是看有些论文就直接用ROC曲线做敏感性分析
from sklearn import metrics
metrics.plot_roc_curve(model,X_test,y_test)
plt.show()
y_pred1 = model.predict_proba(X_test)[:, 1]
from sklearn.metrics import roc_auc_score
ROC_AUC = roc_auc_score(y_test, y_pred1)
#打印AUC值 看下结果 0.92效果很好
print('ROC AUC : {:.4f}'.format(ROC_AUC))
#然后看下交叉验证
#这里面有自助法
#结果 0.8844
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X_train, y_train, cv = 10, scoring='accuracy')
print('Cross-validation scores:{}'.format(scores))
print('Average cross-validation score: {:.4f}'.format(scores.mean()))
#KFold法
#结果 .8975
from sklearn.model_selection import KFold
kfold=KFold(n_splits=5, shuffle=True, random_state=0)
model=RandomForestClassifier()
linear_scores = cross_val_score(model, X, y, cv=kfold)
print('Stratified cross-validation scores with linear kernel:{}'.format(linear_scores))
print('\nAverage stratified cross-validation score with linear kernel:{:.4f}'.format(linear_scores.mean()))结果:



















 9494
9494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











