






机器学习实战 打卡第二周
逻辑回归
一、初步了解
Logistic回归是众多分类算法中的一员。通常,Logistic回归用于二分类问题,假设现在有一些数据点,我们利用一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称作为回归。
二、Sigmoid函数
由教材和视频上所讲解而得知,Logistic回归是一种二分类算法,它利用的是Sigmoid函数阈值在[0,1]这个特性。Logistic回归进行分类的主要思想是:根据现有数据对分类边界线建立回归公式,以此进行分类。其实,Logistic本质上是一个基于条件概率的判别模型。
这里我们注重了解一下Sigmoid函数
其公式如下
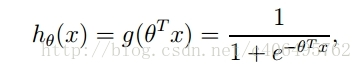
函数曲线表示如下:
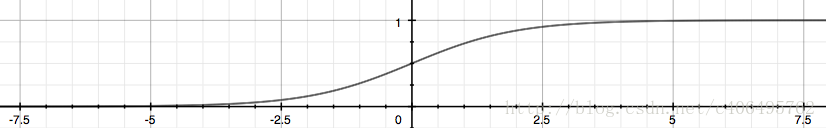
函数具体特征分析可以在书上或者视频中学习得知。
三、如何得到合适的参数向量θ?
我们研究的目的是为了解决实际问题,举个例子,对于"垃圾邮件判别问题",对于给定的邮件(样本),我们定义非垃圾邮件为正类,垃圾邮件为负类。我们通过计算出的概率值即可判定邮件是否是垃圾邮件。
开始我们确立假设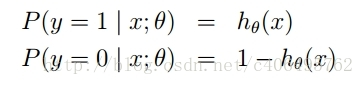
该公式分别为在已知样本x和参数θ的情况下,样本x属性正样本(y=1)和负样本(y=0)的条件概率。理想状态下,根据上述公式,求出各个点的概率均为1,也就是完全分类都正确。但是考虑到实际情况,样本点的概率越接近于1,其分类效果越好。我们可以把上述两个概率公式合二为一:
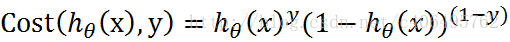
再将公式对数化,便可得到如下公式:
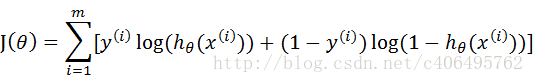
推导过程可以自己试着去推导哦,我这里只做说明。m为样本的总数,y(i)表示第i个样本的类别,x(i)表示第i个样本,需要注意的是θ是多维向量,x(i)也是多维向量。
三、梯度上升算法
这里又不得不引入了梯度上升算法。由于上面我们推断出需要求出J(θ)最大值,这里可以通过不断顺着梯度迭代的求较大值,最后取得最大值,这一过程,就是梯度上升算法。
公式推导我这里还是不做说明
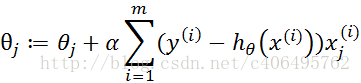
四、概述Logistic回归的一般过程:
收集数据:采用任意方法收集数据。
准备数据:由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则最佳。
分析数据:采用任意方法对数据进行分析。
训练算法:大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数。
测试算法:一旦训练步骤完成,分类将会很快。
使用算法:首先,我们需要输入一些数据,并将其转换成对应的结构化数值;接着,基于训练好的回归系数,就可以对这些数值进行简单的回归计算,判定它们属于哪个类别;在这之后,我们就可以在输出的类别上做一些其他分析工作。
五、实战。
这里选用了视频中博客所用例子进行算法演示
链接:https://blog.youkuaiyun.com/c406495762/article/details/77851973
https://github.com/apachecn/AiLearning/tree/master/docs/ml
https://www.bilibili.com/video/av36993857
从疝气病症状预测病马的死亡率
试试梯度上升算法
# -*- coding:UTF-8 -*-
import numpy as np
import random
"""
函数说明:sigmoid函数
Parameters:
inX - 数据
Returns:
sigmoid函数
Author:
Jack Cui
Blog:
http://blog.youkuaiyun.com/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-09-05
"""
def sigmoid(inX):
return 1.0 / (1 + np.exp(-inX))
"""
函数说明:梯度上升算法
Parameters:
dataMatIn - 数据集
classLabels - 数据标签
Returns:
weights.getA() - 求得的权重数组(最优参数)
Author:
Jack Cui
Blog:
http://blog.youkuaiyun.com/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-08-28
"""
def gradAscent(dataMatIn, classLabels):
dataMatrix = np.mat(dataMatIn) #转换成numpy的mat
labelMat = np.mat(classLabels).transpose() #转换成numpy的mat,并进行转置
m, n = np.shape(dataMatrix) #返回dataMatrix的大小。m为行数,n为列数。
alpha = 0.01 #移动步长,也就是学习速率,控制更新的幅度。
maxCycles = 500 #最大迭代次数
weights = np.ones((n,1))
for k in range(maxCycles):
h = sigmoid(dataMatrix * weights) #梯度上升矢量化公式
error = labelMat - h
weights = weights + alpha * dataMatrix.transpose() * error
return weights.getA() #将矩阵转换为数组,并返回
"""
函数说明:使用Python写的Logistic分类器做预测
Parameters:
无
Returns:
无
Author:
Jack Cui
Blog:
http://blog.youkuaiyun.com/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-09-05
"""
def colicTest():
frTrain = open('horseColicTraining.txt') #打开训练集
frTest = open('horseColicTest.txt') #打开测试集
trainingSet = []; trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr = []
for i in range(len(currLine)-1):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[-1]))
trainWeights = gradAscent(np.array(trainingSet), trainingLabels) #使用改进的随即上升梯度训练
errorCount = 0; numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr =[]
for i in range(len(currLine)-1):
lineArr.append(float(currLine[i]))
if int(classifyVector(np.array(lineArr), trainWeights[:,0]))!= int(currLine[-1]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec) * 100 #错误率计算
print("测试集错误率为: %.2f%%" % errorRate)
"""
函数说明:分类函数
Parameters:
inX - 特征向量
weights - 回归系数
Returns:
分类结果
Author:
Jack Cui
Blog:
http://blog.youkuaiyun.com/c406495762
Zhihu:
https://www.zhihu.com/people/Jack--Cui/
Modify:
2017-09-05
"""
def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
if __name__ == '__main__':
colicTest()

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









