






 本文介绍了GitHub的基本概念,包括Repository、Star、Fork和Pull Request等,并讲解了Git的安装和使用。接着,文章概述了爬虫的工作原理,包括请求、响应和数据存储,并简要提及了多页面和跨页面爬虫的流程。还提到了HTML结构、DOM和网页构造,以及requests库的基础知识,包括GET请求、请求头和状态码。
本文介绍了GitHub的基本概念,包括Repository、Star、Fork和Pull Request等,并讲解了Git的安装和使用。接着,文章概述了爬虫的工作原理,包括请求、响应和数据存储,并简要提及了多页面和跨页面爬虫的流程。还提到了HTML结构、DOM和网页构造,以及requests库的基础知识,包括GET请求、请求头和状态码。
先修知识
使用github
目的:使用github托管项目代码。
基本概念:
Repository :仓库的意思。即你想在github上开源一个项目,那就必须要新建一个Repository。
Star收藏,方便下次查看。意思是收藏项目的人数。收藏的人数越多,代码越多的人认可你的项目
Fork复制克隆项目。什么意思呢?你开源了一个项目,别人想在你这个项目的基础上做出改进,然后应用到自己的项目中,这个时候就可以fork这个项目。 然后他的github主页上就多了一个项目,只不过这个项目是基于你的项目基础(本质上是在原有项目的基础上新建了一个分支),他就可以随心所欲的去改进,但是丝毫不影响原有项目的代码和结构
注:该fork的项目是独立存在的
Pull Request发起请求,这个是基于fork的,还是上面那个列子,如果别人在你基础上做了改进,后来觉得改进的很不错,想让更多的人受益,于是想把自己 的改进合并到原来的项目中,这个时候就可以发起请求。待原项目创建人觉得ok并同意后,就会把这个改进后的代码,整合到原来的项目中。
Watch关注,如果你关注了某个项目,那么以后只要这个项目有任何更新,你都会第一时间收到关于这个项目的通知消息。
Issue事务卡片。举个列子:就是你开源一个项目,别人发现你的项目中有bug,或者哪些地方做的不够好,他就可以给你提个Issue,然后你看到这些问题,就可以逐个去修复,修复ok了就可以一个个的close掉
Github主页账号创建成功或点击网址导航栏github图标都可以进入github主页,该页左侧主要显示用户动态以及关注用户或关注仓库的动态;右侧显示所有的git库。
仓库主页:仓库主页主要显示项目的信息。如:项目代码,版本,收藏/关注/fork情况等
个人主页:个人信息。。。。。等
GIt安装和使用
目的:通过git管理github托管项目代码
安装:Git官网下载
爬虫原理和网页构造
网络连接
在客户端点开一个连接就会向服务器发送出一个请求,服务器就会向客户端返回相应的文件。
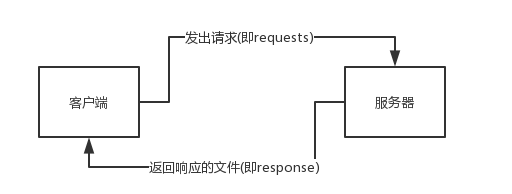
爬虫原理
爬虫的原理就是模拟浏览器对目标网站发送请求,然后从网站返回的数据中提取有用的数据,并将有用的数据存放于数据库或文件中。
即如下三大步骤:
1.模拟计算器对服务器发起Request请求
2.接收服务器端的Response内容并解析、提取所需的信息
3.存储数据
多页面爬虫流程
有时候,我们所需要的信息不在同一个页面,而是分布在多个页面。当这些页面的URL存在一定的规律时,可以用到多页面爬虫。
多页面爬虫流程:
1.观察各页面的URL特点,构建出URL列表
URL:URL是统一资源定位符,对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。就像是路径一样,在电脑上程序访问文件需要提供路径,只不过这些路径是在互联网上。
2.循环遍历URL列表,并调用爬虫函数
3.解析、提取所需的信息
4.存储
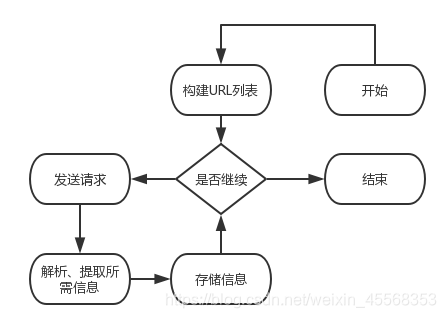
跨页面爬虫流程
当这些页面的URL不存在着明显规律的时候,就要考虑跨页面爬虫流程。假如你在网页上看小说,你想把正本小说爬下来慢慢看,但是章节与章节之间的URL一般是不同的,这个时候你要做的是找到下一章的链接。从第一章爬取到的数据中解析出第二章的链接,然后再去爬第二章的内容,以此类推。
这些内容现在比较抽象,后面的博客会详细说明的。
在WWW上,每一信息资源都有统一的且在网上唯一的地址,该地址就叫URL(Uniform Resource Locator,统一资源定位符),它是WWW的统一资源定位标志,就是指网络地址。
如何查看网页的构造?鼠标右键->检查 或者 按下F12
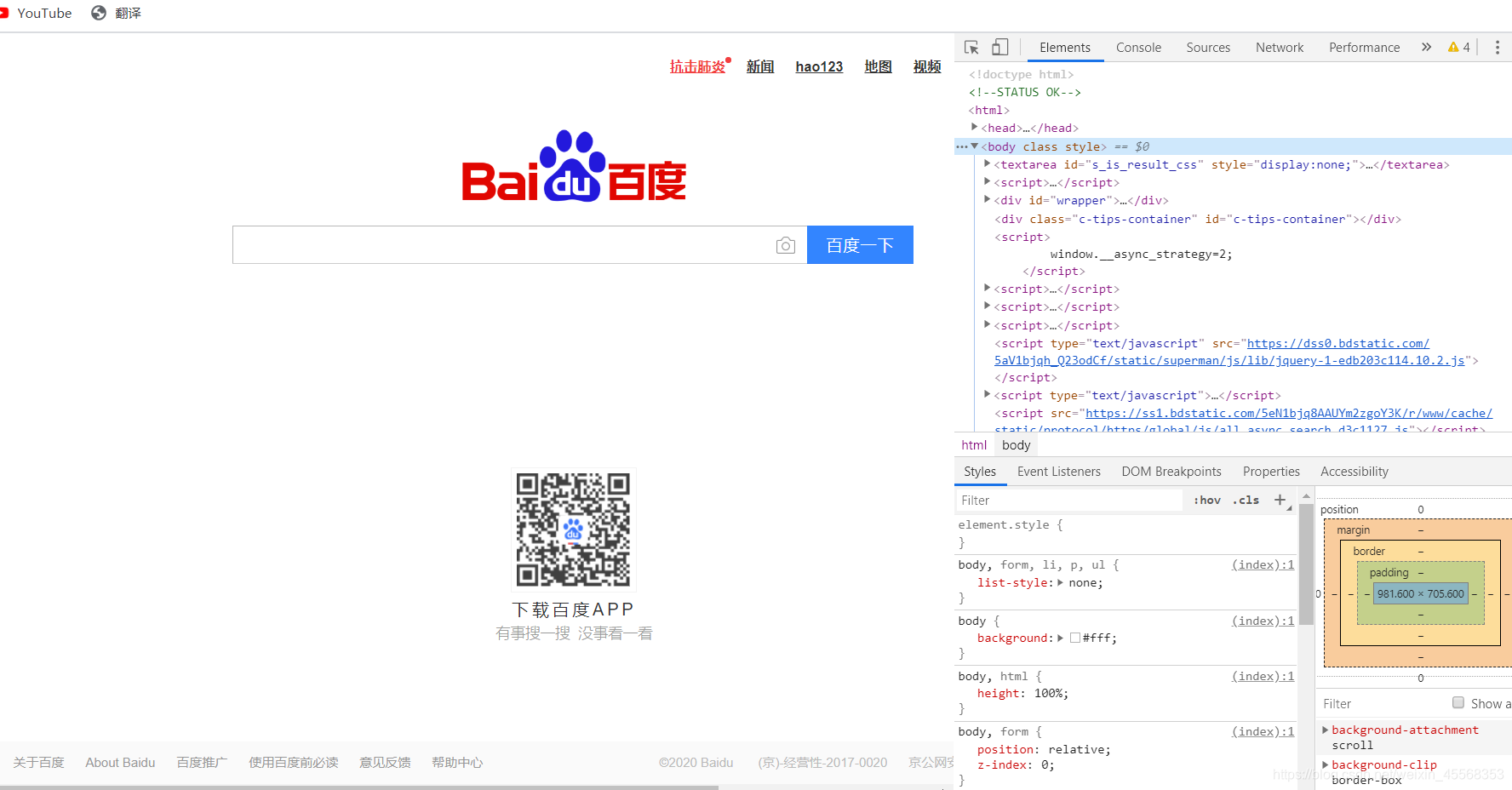
网页结构
这里简单讲一下,浏览器解析 HTML 的时候,并不强制需要每个标签都一定要有闭和标签,但是为了语义明确,最好每个标签都跟上对应的闭和标签。大家可以尝试删除其中的闭和标签进行尝试,并不会影响浏览器的解析。
整个 HTML 文档一般分为 head 和 body 两个部分,在 head 头中,我们一般会指定当前的编码格式为 UTF-8 ,并且使用 title 来定义网页的标题,这个会显示在浏览器的标签上面。
body 中的内容一般为整个 html 文档的正文,html的标签由
到
六个标签构成,字体由大到小递减,换行标签为
,链接使用来创建,herf属性包含链接的URL地址,比如一个指向百度的链接
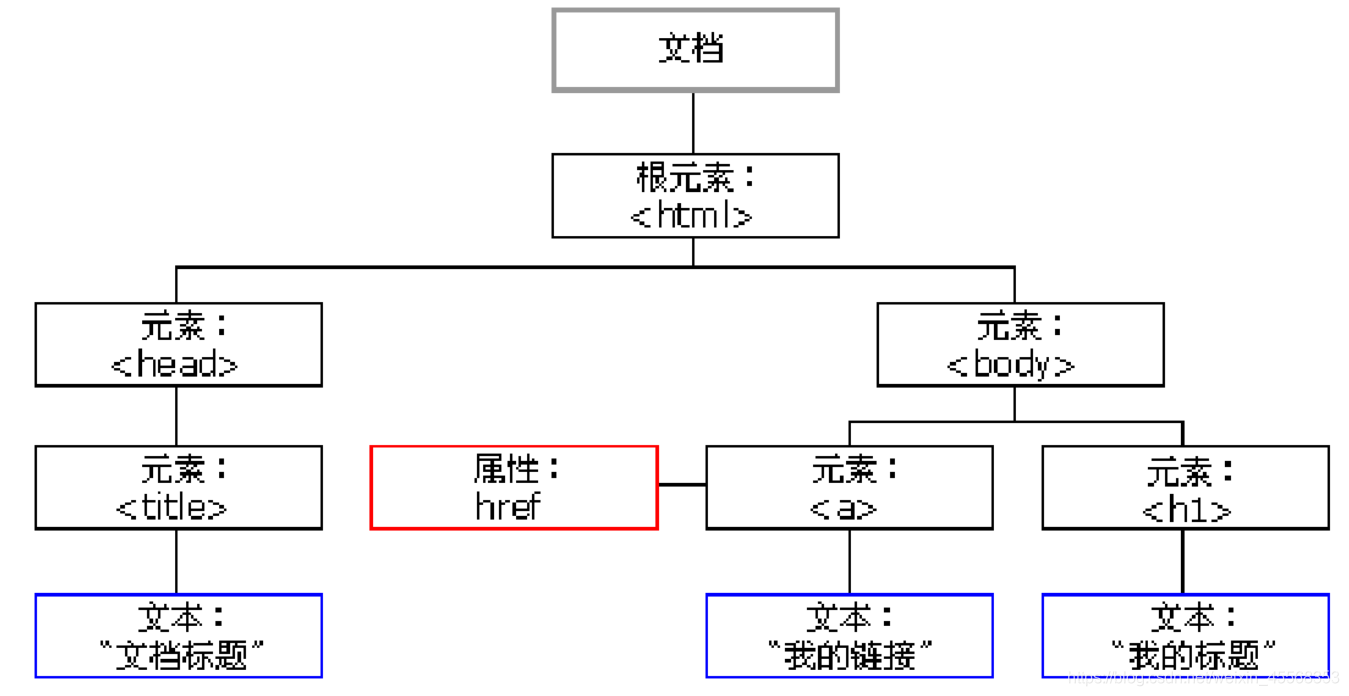
HTML DOM
在 HTML 中,所有标签定义的内容都是节点,它们构成了一个 HTML DOM 树
HTML DOM 将 HTML 文档视作树结构。这种结构被称为节点树:
request库的安装
pip install requests

若如上所示,则代表安装成功。
get请求、请求头与状态码
#导入requests,如果安装成功了就不会报错
import requests
#设置请求头,这里不用打,在浏览器里复制就好了。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'
}
#对bilibili发起一个get请求
res = requests.get("https://www.bilibili.com",headers = headers)
#将bilibili返回的内容输出观察
print(res.content)
print(res.status_code)
requests.get是使用requests库对目标发起一个get请求。
headers是请求头的意思。HTTP客户程序(例如浏览器),向服务器发送请求的时候必须指明请求类型。其实headers不是必要的,因为Python有一个默认的请求头。但是呢,如果你的请求使用了默认的请求头,那么容易被网站判定为恶意程序(网站反爬)而被拒绝回复。
请求头有什么信息呢。可以按下F12查看一下。
BeautifulSoup
import requests
#导入BeautifulSoup库
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'
}
res = requests.get("https://www.bilibili.com",headers = headers)
#使用BeautifulSoup解析从bilibili返回的数据
soup = BeautifulSoup(res.content,'html.parser')
print(soup.prettify())
原来一长串的字符被解析成了HTML形式的对象。
html.parser是BeautifulSoup库的解析器(官方推荐使用lxml)
当然你想用另外解析器也得把相关的库安装好
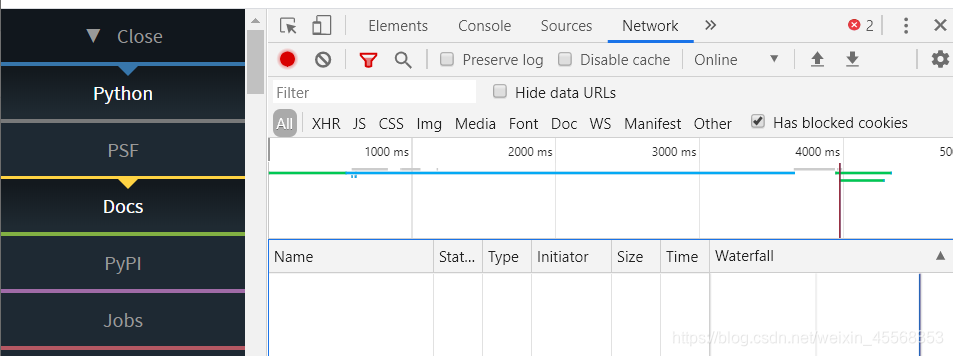
使用开发者工具检查网页
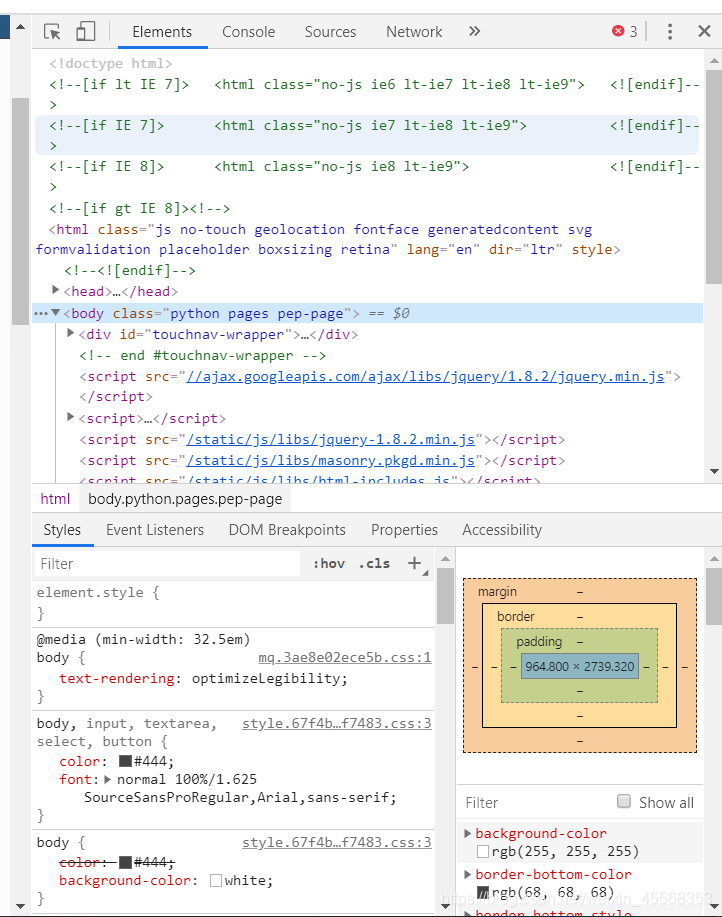
Chrome的开发者模式为用户提供了下面几组工具:
Elements:允许用户从浏览器的角度来观察网页,用户可以借此看到Chrome渲染页面所需要的HTML、CSS和DOM(Document Object Model)对象。
Console:即控制台面板,可以显示各种警告与错误信息。在开发期间,可以使用控制台面板记录诊断信息,或者使用它作为shell在页面上与JavaScript交互
Source:即源代码面板,主要用来调试JavaScript。
Network:可以看到网页向服务气请求了哪些资源、资源的大小以及加载资源的相关信息。此外,还可以查看HTTP的请求头、返回内容等。
Performance:使用这个模块可以记录和查看网站生命周期内发生的各种事情来提高页面运行时的性能
Memory:这个面板可以提供比Performance更多的信息,比如跟踪内存泄漏
Application:检查加载的所有资源。
Security:即安全面板,可以用来处理证书问题等。
值得一提的是快捷菜单中的“Copy XPath”选项。由于XPath是解析网页的利器,因此Chrome中的这个功能对于爬虫程序编写而言就显得十分实用和方便了。
使用“Network”工具可以清楚地查看网页加载网络资源地过程和相关信息。请求的每个资源在“Network”表格中显示为一行,对于某个特定的网络请求,可以进一步查看请求头、响应头及已经返回的内容等信息
一个网络爬虫程序最普遍的过程:
1访问站点;
2定位所需的信息;
3得到并处理信息。
import requests
url = 'https://www.python.org/dev/peps/pep-0020/'
res = requests.get(url)
text = res.text
text
可以看到返回的其实就是开发者工具下Elements的内容,只不过是字符串类型,接下来我们要用python的内置函数find来定位“python之禅”的索引,然后从这段字符串中取出它 通过观察网站,我们可以发现这段话在一个特殊的容器中,通过审查元素,使用快捷键Ctrl+shift+c快速定位到这段话也可以发现这段话包围在pre标签中,因此我们可以由这个特定用find函数找出具体内容
标签可定义预格式化的文本。 被包围在标签 元素中的文本通常会保留空格和换行符。而文本也会呈现为等宽字体
## 爬取python之禅并存入txt文件
with open('zon_of_python.txt', 'w') as f:
f.write(text[text.find('<pre')+28:text.find('</pre>')-1])
print(text[text.find('<pre')+28:text.find('</pre>')-1])
import urllib
url = 'https://www.python.org/dev/peps/pep-0020/'
res = urllib.request.urlopen(url).read().decode('utf-8')
print(res[res.find('<pre')+28:res.find('</pre>')-1])
爬取百度地图
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta name="viewport" content="initial-scale=1.0, user-scalable=no" />
<style type="text/css">
body,
html,
#allmap {
width: 100%;
height: 100%;
overflow: hidden;
margin: 0;
font-family: "微软雅黑";
}
</style>
<script type="text/javascript" src="http://api.map.baidu.com/api?v=3.0&ak=CiprGpYF8c7sMRRmGopzMPTSf7r4dWzF"></script> //在 ak=后面输入你的ak
<title>地图展示</title>
</head>
<body>
<div id="allmap"></div>
</body>
</html>
<script type="text/javascript">
// 百度地图API功能
var map = new BMap.Map("allmap"); // 创建Map实例
map.centerAndZoom(new BMap.Point(116.404, 39.915), 11); // 初始化地图,设置中心点坐标和地图级别
//添加地图类型控件
map.addControl(new BMap.MapTypeControl({
mapTypes: [
BMAP_NORMAL_MAP,
BMAP_HYBRID_MAP
]
}));
map.setCurrentCity("北京"); // 设置地图显示的城市 此项是必须设置的
map.enableScrollWheelZoom(true); //开启鼠标滚轮缩放
</script>
import requests
def getUrl(*address):
ak = '' ## 填入你的api key
if len(address) < 1:
return None
else:
for add in address:
url = 'http://api.map.baidu.com/geocoding/v3/?address={0}&output=json&ak=CiprGpYF8c7sMRRmGopzMPTSf7r4dWzF{1}'.format(add,ak)
yield url
def getPosition(url):
'''返回经纬度信息'''
res = requests.get(url)
#print(res.text)
json_data = eval(res.text)
if json_data['status'] == 0:
lat = json_data['result']['location']['lat'] #纬度
lng = json_data['result']['location']['lng'] #经度
else:
print("Error output!")
return json_data['status']
return lat,lng
if __name__ == "__main__":
address = ['北京市清华大学','北京市北京大学','保定市华北电力大学','上海市复旦大学','武汉市武汉大学']
for add in address:
add_url = list(getUrl(add))[0]
print('url:', add_url)
try:
lat,lng = getPosition(add_url)
print("{0}|经度:{1}|纬度:{2}.".format(add,lng,lat))
except Error as e:
print(e)

对于今天任何一个正式的网站页面而言,HTML决定了网页的基本内容,CSS(Cascading Style Sheets,层叠样式表)描述了网页的样式布局,JavaScript 则控制了用户与网页的交互
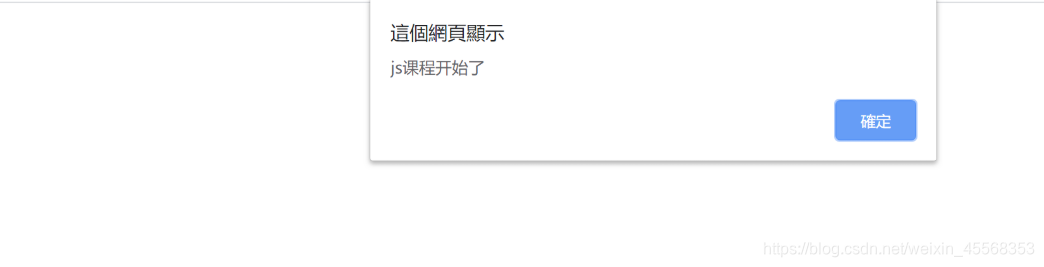
使用js
<!--test1.html-->
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title></title>
</head>
<body>
<script type="text/javascript">
alert('js课程开始了')
</script>
</body>
</html>
JavaScript在语法结构上比较类似于C++等面向对象的语言,循环语句、条件语句等也都与Python中的写法有较大的差异,但其弱类型特点会更符合Python开发者的使用习惯
//JavaScript示例,计算a+b和a*b。
function add(a,b)
{
var sum=a+b;
console.log('%d + %d equals to %d',a,b,sum);
}
function mut(a,b)
{
var prod=a * b;
console.log('%d * %d equals to %d',a,b,prod);
}

以百度主页为列
import requests
>>> r=requests.get("http://www.baidu.com")
>>> r.status_code
200
>>> r.enconding='utf-8'
>>> r.text
输出如下
'<!DOCTYPE html>\r\n<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>ç\x99¾åº¦ä¸\x80ä¸\x8bï¼\x8cä½\xa0å°±ç\x9f¥é\x81\x93</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=ç\x99¾åº¦ä¸\x80ä¸\x8b class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>æ\x96°é\x97»</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>å\x9c°å\x9b¾</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>è§\x86é¢\x91</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>è´´å\x90§</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>ç\x99»å½\x95</a> </noscript> <script>document.write(\'<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=\'+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ \'" name="tj_login" class="lb">ç\x99»å½\x95</a>\');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">æ\x9b´å¤\x9a产å\x93\x81</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>å\x85³äº\x8eç\x99¾åº¦</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使ç\x94¨ç\x99¾åº¦å\x89\x8då¿\x85读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>æ\x84\x8fè§\x81å\x8f\x8dé¦\x88</a> 京ICPè¯\x81030173å\x8f· <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>\r\n'
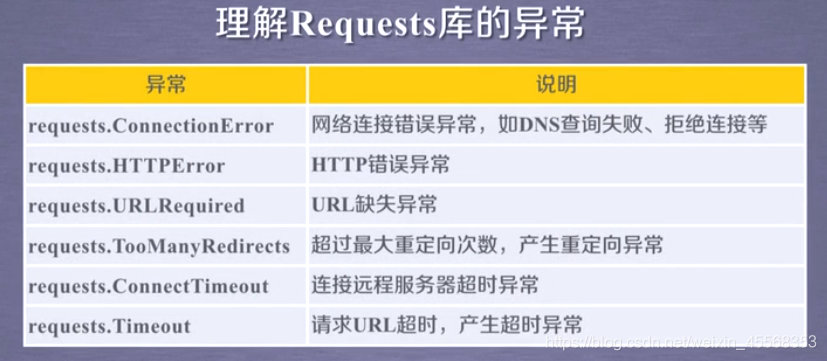
这章重中之中 了解request
request库的七种主要方法

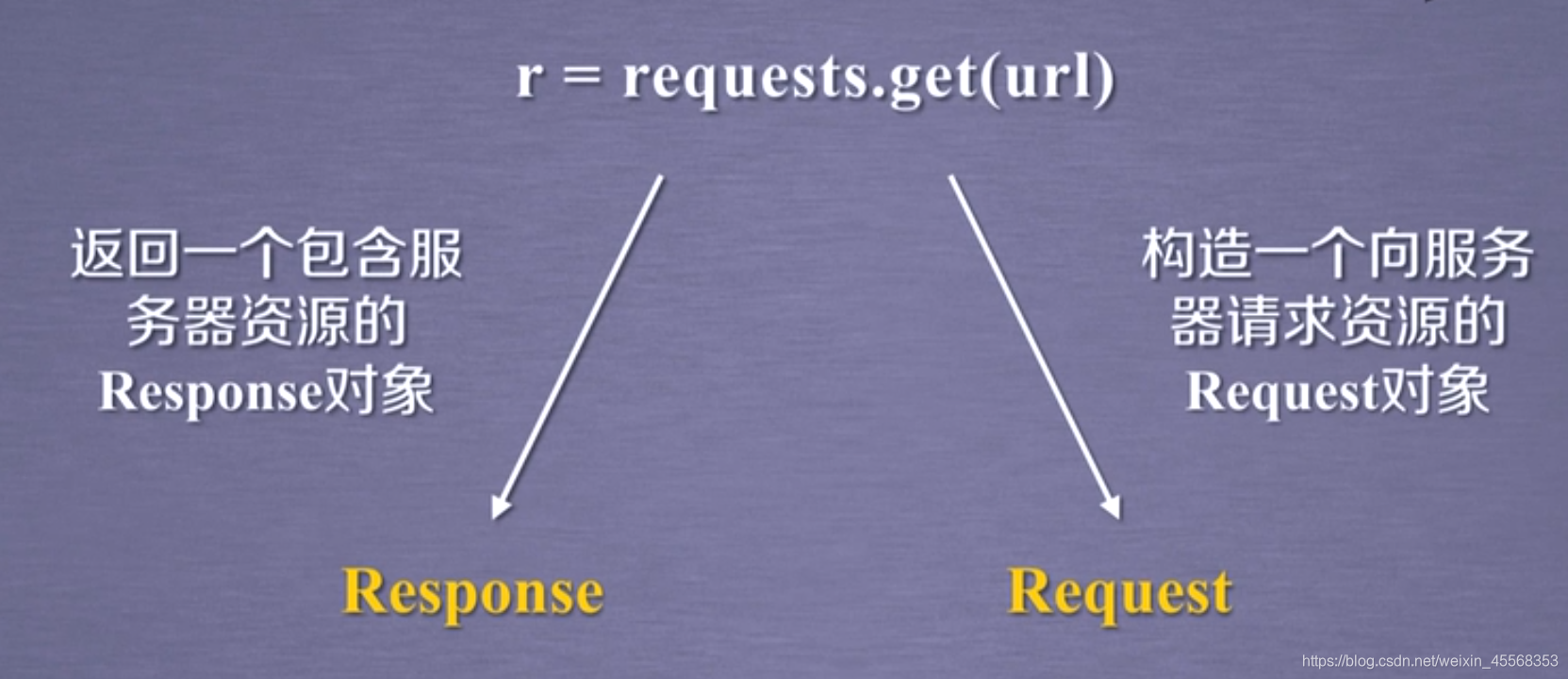
完整参数
requests.get(url,params=None,**kwargs)

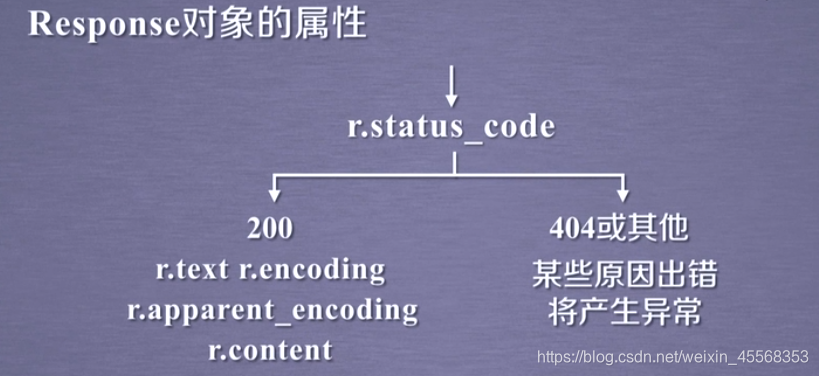
print(r.status_code)输出状态码、若输出为200则访问成功,否则失败


ISO-8859-1不能解析中文

http协议












类人行为的时候(访问次数和内容很少)可以不遵守robots协议。

京东商品页面的爬取
r=requests.get("https://item.jd.com/100008348530.html")
r.encoding=r.apparent_encoding
print(r.text[:1000])
爬取亚马逊
kv={'user-agent':'Mozilla/5.0'}
url="https://www.amazon.cn/dp/B07KS2SZ6Z/ref=sr_1_3?dchild=1&keywords=Champion&p_n_global_store_origin_marketplace=1827360071%7C1844252071%7C1879515071%7C1901313071&qid=1587366221&sr=8-3"
r=requests.get(url,headers=kv)
print(r.status_code)
print(r.request.headers)
print(r.text[:1000])
访问失败的时候,可能是改网站限制了爬虫爬取。可以更改头目录
网络图片的爬取和存储
网络图片链接的格式:
http://www.example.com/picture.jpg
path='D:/python/abc.jpg'
url="http://image.nationalgeographic.com.cn/2017/0211/20170211061910157.jpg"
r=requests.get(url)
print(r.status_code)
with open(path,'wb') as f:
f.write(r.content)
f.close()

IP地址归属地的自动查询
http://m.ip138.com/ip.asp?ip=ipaddress

1

















 776
776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









