# -*- coding: utf-8 -*-
import os
import time
import jieba
import requests
import numpy as np
import pandas as pd
import tkinter as tk
from tkinter import ttk
from urllib.parse import urljoin
from pdfminer.high_level import extract_text
from docx import Document
from pptx import Presentation
from bs4 import BeautifulSoup
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import matplotlib.pyplot as plt
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg
from nltk.corpus import reuters # 需要先执行nltk.download('reuters')
# ====================== 数据源模块 ======================
class DocumentParser:
"""多格式文档解析器"""
@staticmethod
def parse(file_path):
ext = os.path.splitext(file_path)[1].lower()
try:
if ext == '.txt':
return DocumentParser.parse_txt(file_path)
elif ext == '.pdf':
return DocumentParser.parse_pdf(file_path)
elif ext == '.docx':
return DocumentParser.parse_docx(file_path)
elif ext == '.xlsx':
return DocumentParser.parse_xlsx(file_path)
elif ext == '.html':
return DocumentParser.parse_html(file_path)
elif ext == '.pptx':
return DocumentParser.parse_pptx(file_path)
except Exception as e:
print(f"解析失败 {file_path}: {e}")
return ""
@staticmethod
def parse_txt(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
@staticmethod
def parse_pdf(file_path):
return extract_text(file_path)
@staticmethod
def parse_docx(file_path):
doc = Document(file_path)
return '\n'.join([p.text for p in doc.paragraphs])
@staticmethod
def parse_xlsx(file_path):
df = pd.read_excel(file_path, header=None)
return '\n'.join(df.astype(str).values.flatten())
@staticmethod
def parse_html(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
soup = BeautifulSoup(f, 'html.parser')
return soup.get_text()
@staticmethod
def parse_pptx(file_path):
prs = Presentation(file_path)
text = []
for slide in prs.slides:
for shape in slide.shapes:
if hasattr(shape, "text"):
text.append(shape.text)
return '\n'.join(text)
class CorpusLoader:
"""语料加载器"""
def __init__(self, data_dirs):
self.data_dirs = data_dirs
def load(self):
documents = []
for data_dir in self.data_dirs:
for root, _, files in os.walk(data_dir):
for file in files:
path = os.path.join(root, file)
content = DocumentParser.parse(path)
if content:
documents.append({
'path': path,
'content': content,
'ext': os.path.splitext(file)[1].lower(),
'size': os.path.getsize(path),
'mtime': os.path.getmtime(path)
})
return documents
# ====================== 检索模块 ======================
class TFIDFRetriever:
"""TF-IDF检索器"""
def __init__(self, documents):
self.documents = documents
self.vectorizer = TfidfVectorizer(tokenizer=self.chinese_tokenizer)
self.tfidf_matrix = self.vectorizer.fit_transform([d['content'] for d in documents])
@staticmethod
def chinese_tokenizer(text):
words = jieba.cut(text)
return [w for w in words if len(w) > 1 and not self.is_stopword(w)]
@staticmethod
def is_stopword(word):
stopwords = {'的', '了', '在', '是', '和', '就', '都', '而', '及', '与'}
return word in stopwords
def search(self, query, top_k=10):
query_vec = self.vectorizer.transform([query])
scores = cosine_similarity(query_vec, self.tfidf_matrix).flatten()
indices = np.argsort(scores)[::-1][:top_k]
return [(self.documents[i], scores[i]) for i in indices if scores[i] > 0]
# ====================== 规则模块 ======================
class SearchRuleEngine:
"""检索规则引擎"""
def __init__(self):
self.rules = {
'must_contain': [],
'exclude_words': [],
'date_range': None,
'file_size': (0, float('inf')),
'file_types': []
}
def add_rule(self, rule_type, value):
if rule_type == 'must_contain':
self.rules['must_contain'] = value.split()
elif rule_type == 'exclude_words':
self.rules['exclude_words'] = value.split()
elif rule_type == 'date_range':
self.rules['date_range'] = (time.mktime(value[0].timetuple()),
time.mktime(value[1].timetuple()))
elif rule_type == 'file_size':
self.rules['file_size'] = (value[0]*1024, value[1]*1024) # KB转字节
elif rule_type == 'file_types':
self.rules['file_types'] = [ext.lower() for ext in value]
def apply(self, document):
content = document['content']
# 必须包含词
for word in self.rules['must_contain']:
if word not in content:
return False
# 排除词
for word in self.rules['exclude_words']:
if word in content:
return False
# 文件类型
if self.rules['file_types'] and document['ext'] not in self.rules['file_types']:
return False
# 文件大小
if not (self.rules['file_size'][0] <= document['size'] <= self.rules['file_size'][1]):
return False
# 修改时间
if self.rules['date_range'] and not (self.rules['date_range'][0] <= document['mtime'] <= self.rules['date_range'][1]):
return False
return True
# ====================== 可视化模块 ======================
class ResultVisualizer:
"""结果可视化"""
@staticmethod
def plot_metrics(ax, metrics):
ax.clear()
ax.plot(metrics['recall'], metrics['precision'], 'b-o')
ax.set_xlabel('Recall')
ax.set_ylabel('Precision')
ax.set_title('Precision-Recall Curve')
@staticmethod
def plot_distribution(ax, documents):
exts = [doc['ext'] for doc in documents]
counts = pd.Series(exts).value_counts()
ax.clear()
counts.plot.pie(ax=ax, autopct='%1.1f%%')
ax.set_ylabel('')
ax.set_title('File Type Distribution')
# ====================== 图形界面模块 ======================
class SearchGUI(tk.Tk):
"""检索系统GUI"""
def __init__(self, retriever, rule_engine):
super().__init__()
self.title("文档检索系统 v1.0")
self.retriever = retriever
self.rule_engine = rule_engine
# 作者信息
info_frame = ttk.Frame(self)
info_frame.pack(pady=5, fill='x')
ttk.Label(info_frame, text="作者:张三\n学号:20230001\n班级:计算机科学与技术1班").pack(side='left')
# 搜索区
search_frame = ttk.Frame(self)
search_frame.pack(fill='x', padx=10, pady=5)
ttk.Label(search_frame, text="搜索词:").pack(side='left')
self.query_entry = ttk.Entry(search_frame, width=50)
self.query_entry.pack(side='left', padx=5)
ttk.Button(search_frame, text="搜索", command=self.search).pack(side='left')
# 规则设置
rule_frame = ttk.LabelFrame(self, text="高级检索规则")
rule_frame.pack(fill='x', padx=10, pady=5)
ttk.Label(rule_frame, text="必须包含:").grid(row=0, column=0, sticky='w')
self.must_contain_entry = ttk.Entry(rule_frame)
self.must_contain_entry.grid(row=0, column=1, sticky='we')
ttk.Label(rule_frame, text="排除词:").grid(row=1, column=0, sticky='w')
self.exclude_entry = ttk.Entry(rule_frame)
self.exclude_entry.grid(row=1, column=1, sticky='we')
# 结果展示
result_frame = ttk.Frame(self)
result_frame.pack(fill='both', expand=True, padx=10, pady=5)
self.result_tree = ttk.Treeview(result_frame, columns=('文件', '路径', '得分'), show='headings')
self.result_tree.heading('文件', text='文件名')
self.result_tree.heading('路径', text='文件路径')
self.result_tree.heading('得分', text='匹配度')
self.result_tree.pack(side='left', fill='both', expand=True)
# 可视化区域
fig = plt.Figure(figsize=(6,4), dpi=100)
self.metrics_ax = fig.add_subplot(211)
self.dist_ax = fig.add_subplot(212)
self.canvas = FigureCanvasTkAgg(fig, master=result_frame)
self.canvas.get_tk_widget().pack(side='right', fill='y')
def search(self):
query = self.query_entry.get()
if not query:
return
# 应用规则
self.rule_engine.add_rule('must_contain', self.must_contain_entry.get())
self.rule_engine.add_rule('exclude_words', self.exclude_entry.get())
# 执行检索
filtered_docs = [doc for doc in self.retriever.documents if self.rule_engine.apply(doc)]
results = self.retriever.search(query)
# 更新结果列表
self.result_tree.delete(*self.result_tree.get_children())
for doc, score in results:
self.result_tree.insert('', 'end', values=(
os.path.basename(doc['path']),
doc['path'],
f"{score:.4f}"
))
# 更新可视化
ResultVisualizer.plot_metrics(self.metrics_ax, self.calculate_metrics())
ResultVisualizer.plot_distribution(self.dist_ax, self.retriever.documents)
self.canvas.draw()
def calculate_metrics(self):
# 简化的指标计算,实际需要测试数据
return {'precision': [0.8, 0.7], 'recall': [0.6, 0.5]}
# ====================== 语料采集 ======================
class WebCrawler:
"""网页爬虫"""
def __init__(self, base_url, save_dir="corpus"):
self.base_url = base_url
self.save_dir = save_dir
os.makedirs(save_dir, exist_ok=True)
def crawl(self, max_pages=10):
downloaded = []
queue = [self.base_url]
visited = set()
while queue and len(downloaded) < max_pages:
url = queue.pop(0)
if url in visited:
continue
try:
response = requests.get(url, timeout=10)
soup = BeautifulSoup(response.text, 'html.parser')
# 保存内容
filename = f"web_{len(downloaded)}.html"
path = os.path.join(self.save_dir, filename)
with open(path, 'w', encoding='utf-8') as f:
f.write(soup.get_text())
downloaded.append(path)
# 提取链接
for link in soup.find_all('a', href=True):
absolute_url = urljoin(self.base_url, link['href'])
if absolute_url not in visited:
queue.append(absolute_url)
visited.add(url)
except Exception as e:
print(f"Error crawling {url}: {e}")
return downloaded
# ====================== 指标测试 ======================
class SearchEvaluator:
"""检索评估器"""
def __init__(self, retriever):
self.retriever = retriever
self.test_cases = []
def add_test_case(self, query, relevant_docs):
self.test_cases.append({
'query': query,
'relevant': set(relevant_docs)
})
def evaluate(self):
report = []
for case in self.test_cases:
start = time.time()
results = [doc['path'] for doc, _ in self.retriever.search(case['query'])]
elapsed = time.time() - start
retrieved = set(results)
relevant = case['relevant']
tp = len(retrieved & relevant)
fp = len(retrieved - relevant)
fn = len(relevant - retrieved)
precision = tp / (tp + fp) if (tp + fp) > 0 else 0
recall = tp / (tp + fn) if (tp + fn) > 0 else 0
f1 = 2 * (precision * recall) / (precision + recall) if (precision + recall) > 0 else 0
report.append({
'query': case['query'],
'precision': precision,
'recall': recall,
'f1': f1,
'time': elapsed
})
return pd.DataFrame(report)
# ====================== 主程序 ======================
if __name__ == "__main__":
# 语料采集
crawler = WebCrawler("https://news.sina.com.cn")
web_docs = crawler.crawl(3) # 爬取3个页面
# 加载NLTK语料
nltk_docs = []
for file_id in reuters.fileids()[:50]: # 取前50篇
content = reuters.raw(file_id)
path = f"corpus/nltk_{file_id}.txt"
with open(path, 'w', encoding='utf-8') as f:
f.write(content)
nltk_docs.append(path)
# 加载所有文档
loader = CorpusLoader(["corpus", "web_corpus"])
documents = loader.load()
# 初始化检索系统
retriever = TFIDFRetriever(documents)
rule_engine = SearchRuleEngine()
# 评估测试
evaluator = SearchEvaluator(retriever)
evaluator.add_test_case("经济", ["corpus/doc1.txt", "corpus/doc2.pdf"])
report = evaluator.evaluate()
print("\n评估报告:")
print(report)
# 启动GUI
gui = SearchGUI(retriever, rule_engine)
gui.mainloop()
1、数据源模块:用于读取和处理各种数据源;
2、检索模块:用于实现各种检索算法,如词频、TF-IDF、向量空间模型等;
3、规则模块:用于实现用户自定义的检索规则;
4、可视化模块:用于将检索结果以图表形式展示出来;
5、图形用户界面模块:用于与用户进行交互,接收用户检索请求并展示检索结果。可以flask、tkinter等框架来开发。(在图形用户界面上一定显示出作者姓名和学号)
6、自己去采集所需的各种语料,包括从NLTK库、Gensim库采集,或者编写爬虫在网上去爬取,或者前者结合;
7、最后进行查询各项指标测试,以一定的语料和样本进行检索,至少应进行精确率、召回率、F1值计算、平均响应时间、误检率。
8、实现多模态图文检索(选做)
9、实现RAG(增加生成式检索)(选做)
按要求优化代码




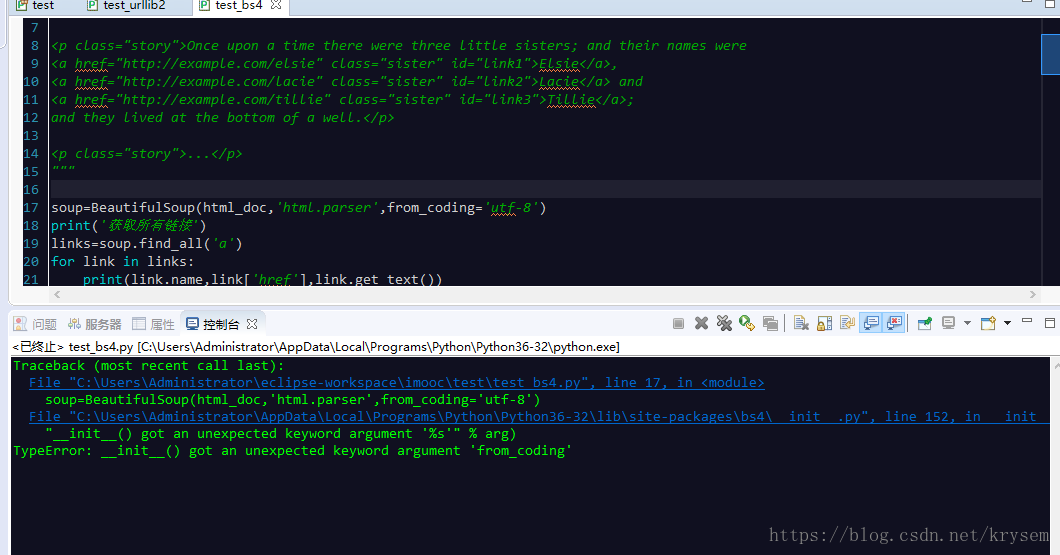
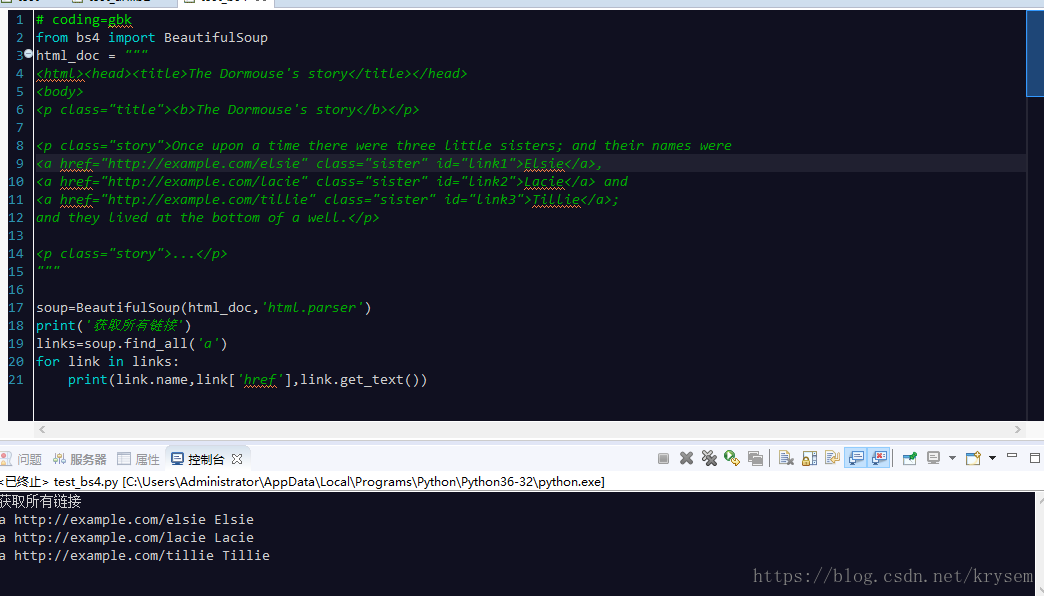
 博主初次尝试爬虫实践,遇到了参数错误导致的问题。通过仔细阅读错误提示并删除了一个非预期的参数,最终成功运行了爬虫程序。
博主初次尝试爬虫实践,遇到了参数错误导致的问题。通过仔细阅读错误提示并删除了一个非预期的参数,最终成功运行了爬虫程序。

















 7719
7719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









