







笔记:计算机视觉与深度学习-北邮-鲁鹏-2020年录屏
写在开头(重复的)
1.课程来源:B站视频.
2.笔记目的:个人学习+增强记忆+方便回顾
3.时间:2021年4月9日
4.同类笔记链接:(钩子:会逐渐增加20210428)
第一讲.第二讲.第三讲.第四讲.第五讲.第六讲.第七讲.第八讲.第九讲.第十讲.第十一讲.番外篇一个简单实现.第十二讲.第十三讲.第十四讲完结.
5.请一定观看视频课程,笔记是对视频内容的有限度的重现和基于个人的深化理解。
6.注意符号 SS:意味着我的个人理解,非单纯授课内容,有可能有误哦。
—以下正文—
一、本章解决什么问题
1.什么是图像分类任务?它有哪些应用场合?
(答:找特征,贴标签)
2.图像分类任务有哪些难点?
3.基于规则的方法是否可行?
4.什么是数据驱动的图像分类范式?
5.常用的分类任务评价指标是什么?
二、图像分类任务有哪些难点
- 1.从广义来讲:跨越语义鸿沟
- 2.视角:比如同一人脸的不同角度
- 3.光照:背光和面光造成色彩变化极大
- 4.尺度:车载识别系统中,远近大小的人都要识别到
- 5.遮挡:虹膜,只露出一半的虹膜
- 6.形变:比如猫是液体的。。。。。
- 7.背景杂波:雪地中的北极狐,背景对图像造成干扰。
- 8.类内形变:各种设计感强的凳子
- 9.运动模糊:感应器成像的技术性特点,对我们图像识别造成的困扰。
- 10.类别繁多:
三、基于规则的分类方法是否可行
不行!
四、什么是数据驱动的图像分类范式(28:28)
(一)数据驱动的图像分类方法的步骤
- 1.数据集构建
- 1.1 有监督数据集
- 1.2 无监督的数据集
- 2.分类器设计与学习(核心)
- 2.1 数学模型
- 2.2 根据数学模型构建分类器
- 2.3 从数据集中学习用于分类器的未知参数
- 3.分类器决策
(二)分类器的设计与学习
- 1.基本流程图
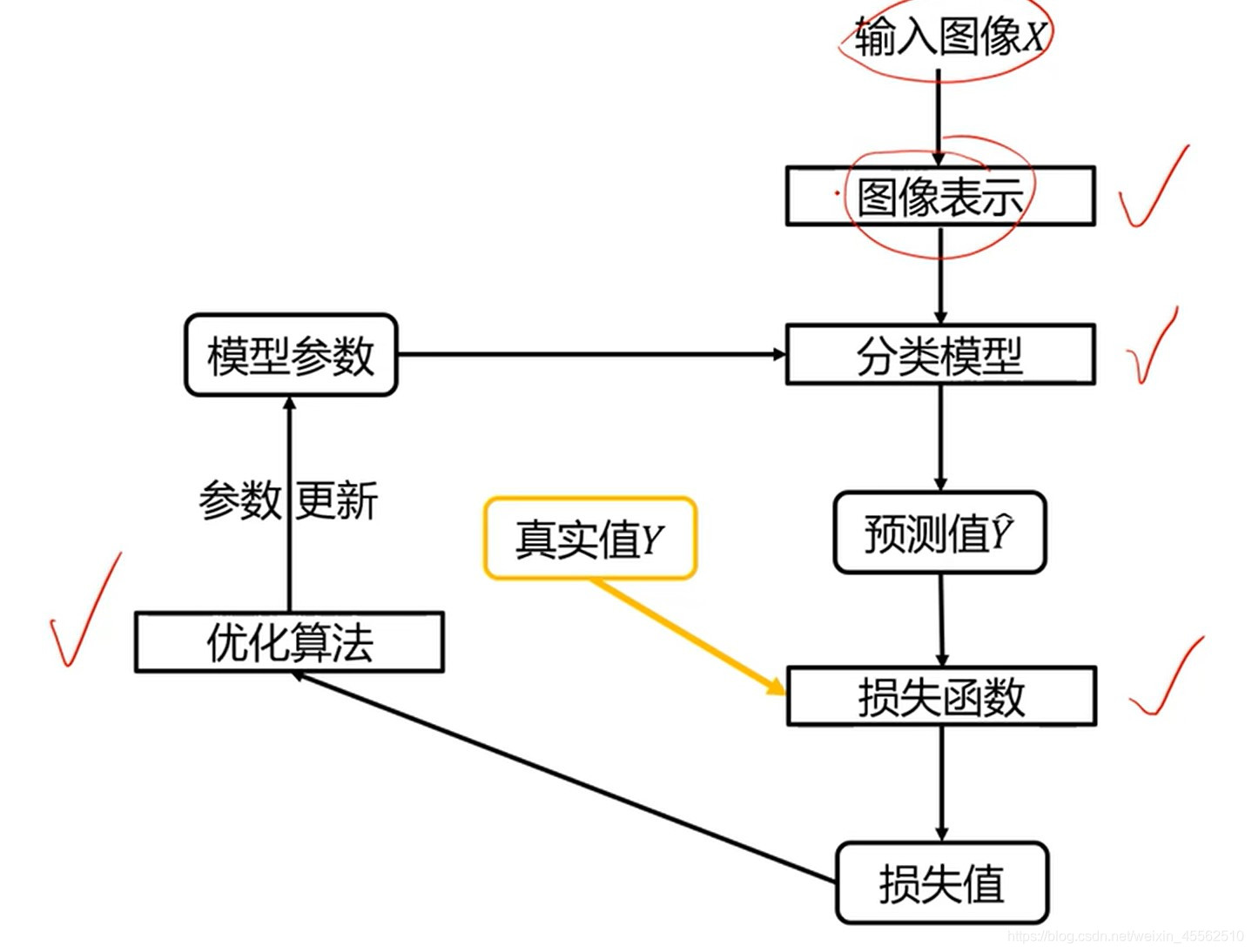
- 1.1图像表示:设计出的系统是需要输入图像?向量?要不要抽取特征?
- 1.2分类模型:不论模型好坏,都会输出一个预测值,通过与真实值的对比得到损失值。
- 1.3优化算法:调整参数,降低损失值。
- 1.4循环,得到性能合理的分类器。
- 2.图像表示方法
- 2.1像素表示(本课程重点)
- 2.2全局特征表示(如GIST(频率特征))(适用于风景类、城市建筑等大场景分类,不适用于细节分类)
- 2.3局部特征表示(如SIFT特征+词袋模式)
- 3.分类器
- 3.1分类器的分类(O(∩_∩)O)
- 近邻分类器
- 贝叶斯分类器
- 线性分类器(主讲)
- 支撑向量机分类器(线性分类器拓展)
- 神经网络分类器(主讲)
- 随机森林
- Adaboost
- 3.2学习分类器的目的:分类器是工具,首先要会使用,其次要学习源码以便于做针对性改造。
- 3.1分类器的分类(O(∩_∩)O)
- 4.优化函数
- 4.1一阶方法:梯度下降、随机梯度下降、小批量随机梯度下降(主讲)
- 4.2二阶方法:牛顿法、BFGS、L-BFGS (注:BFGS法(BFGS method)是一种拟牛顿法,指用BFGS矩阵作为拟牛顿法中的对称正定迭代矩阵的方法,由于BFGS法对一维搜索的精度要求不高,并且由迭代产生的BFGS矩阵不易变为奇异矩阵,因而BFGS法比DFP法在计算中具有更好的数值稳定性。)
- 5.训练过程做的事情
- 5.1数据集划分
- 5.2数据预处理
- 5.3数据增强(旋转、裁剪等等)(使数据集尽可能的多)
- 5.4欠拟合与过拟合:减小算法复杂度、使用权重正则项、使用droput正则化
- 5.5超参数调整
- 5.6模型集成
五、常用的分类任务指标(45:18)
1.top1与top5
六、线性分类器(47:30)
(一)简介
- 1.采用数据集简介—CIFAR10数据集:开放的,包含50000张训练样本、10000张测试样本分为飞机、汽车、鸟、猫、鹿、狗、蛙、马、船、卡车10个类别,图像为彩色图像,图像大小32*32。
- 2.分类器设计全部知识点分布
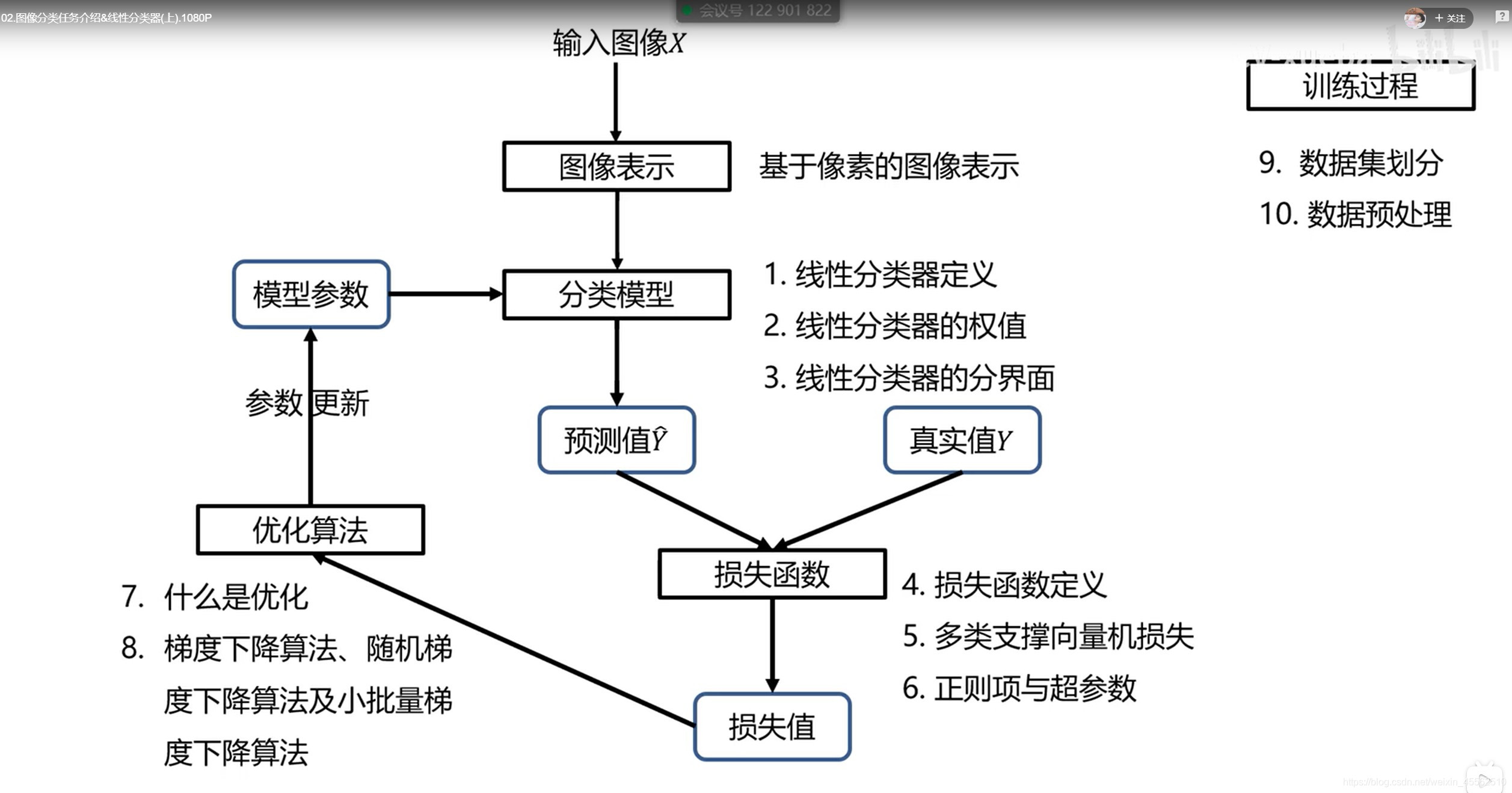
(二)图像表示
- 1.图像类型:Binary(黑白图)、Gray Scale(灰度图0-255)、color(RGB)
(三)分类模型
- 1.线性分类器定义
- 1.1为什么学?线性分类器形式简单、容易理解。同时,通过层级结构(神经网络)或者高维映射(支撑向量机)可以形成功能强大的非线性模型。(大样本王者-神经网络,小样本王者-支撑向量机)
- 1.2定义:线性分类器是一种线性映射,讲输入的图像特征映射为类别分数。
- 1.3注:如何理解老师在视频56分提到的,我们使用的图像是3072维的?答:本课程使用的数据集是CIFAR10数据集,图像规格3232彩色,则有维度=3232*3=3072维。
- 1.4线性分类器的线性,就体现在向量w与向量x的乘积上。
- 1.5计算方法与决策方法:

- 1.6线性分类器实例(注意左下角决策步骤)
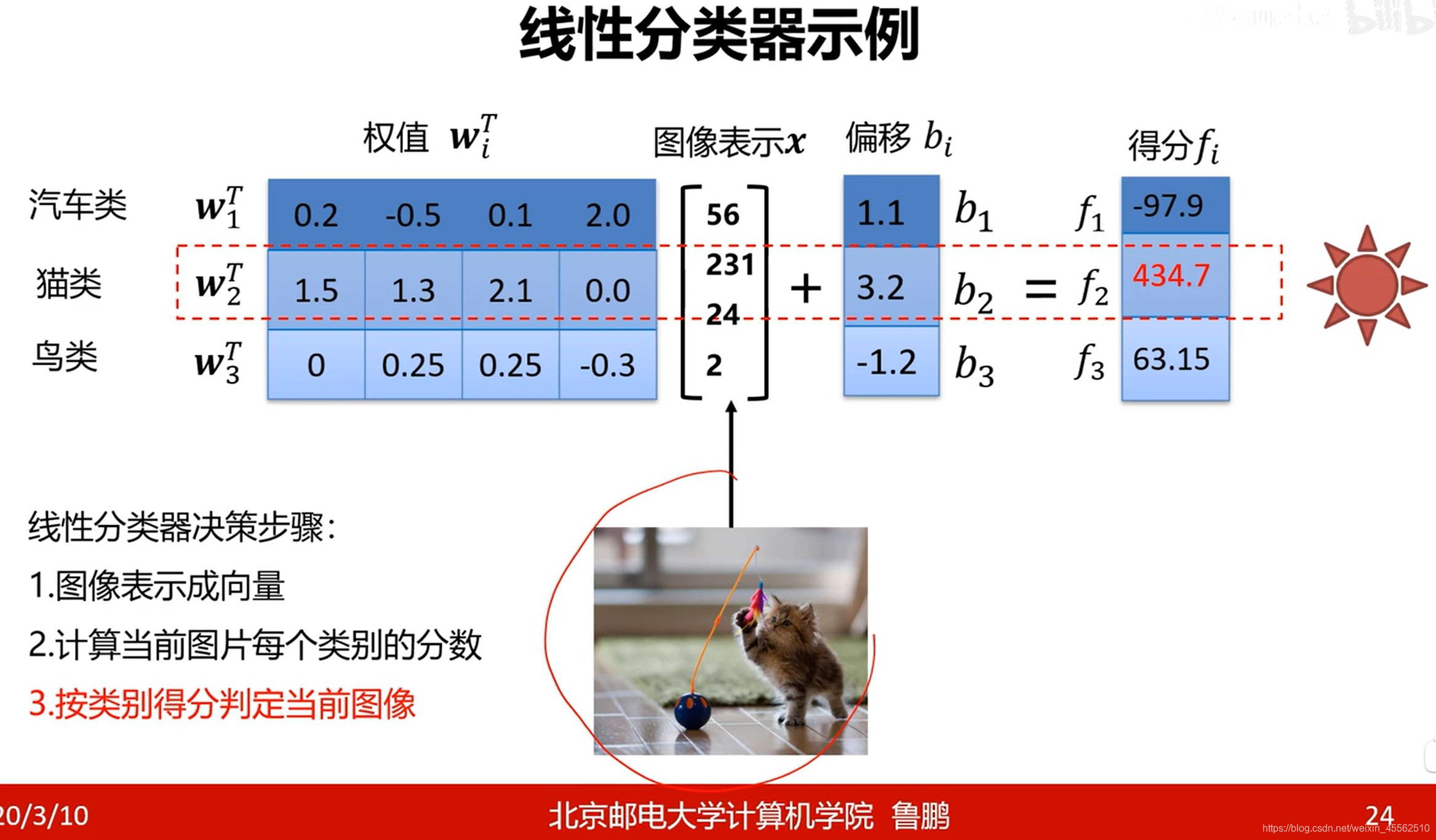
- 1.7线性分类器的矩阵表示

- 2.线性分类器的权值向量
- 2.1权值看作是一种模板,将其按照图像的格式输出后,会发现就是一张有着标签物体特征的模糊图片
- 2.2输入图像与评估模板的匹配程度越高,分类器输出的分数就越高。(SS这一点体现在向量w与向量x的乘积中。)
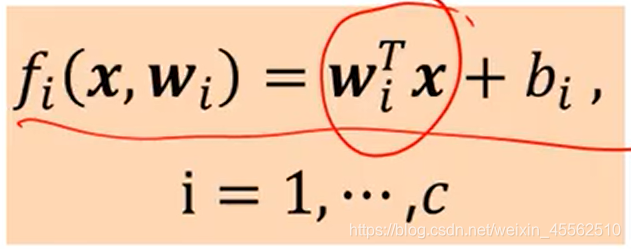
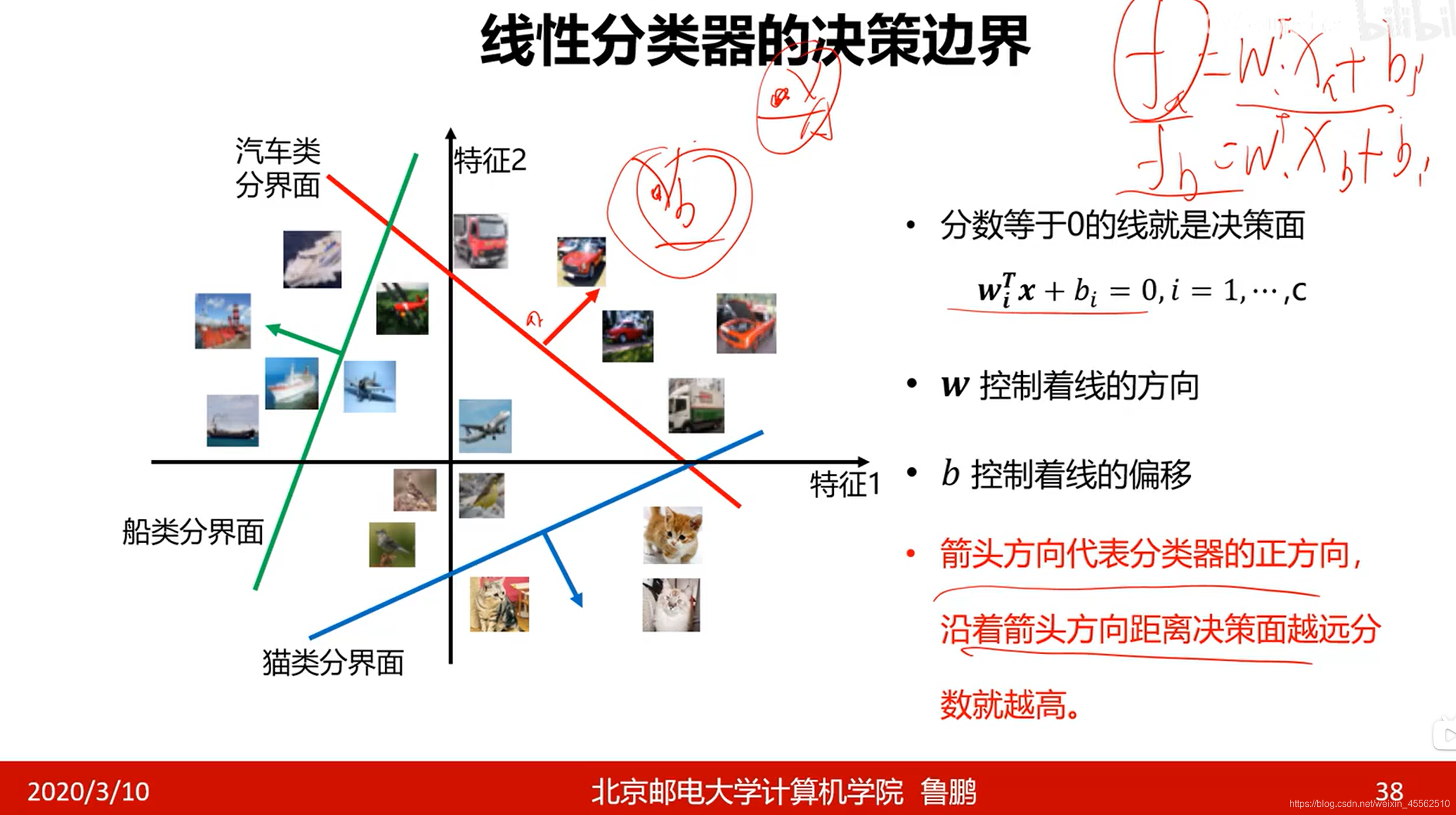
- 3.线性分类器的决策边界
- 3.1 SS如何理解线性分类器的决策边界?
- 首先它不是一条线,决策边界应当是一个n维向量空间(n等于wi的维数)中的i个“面”(i,既标签的个数)。每一个“面”是由方程wx + b = 0 定义的。面区分内外。(SS代入线性代数的思维区思考这一部分!!!!)
(四)损失函数
- 1.损失函数的定义
- 1.1定义:损失函数搭建了模型性能与模型参数之间的桥梁,指导模型参数优化。
- 1.2损失函数在工作时,一般有如下规定:一是损失函数是一个函数,用于度量给定分类器的预测值与真实值的不一致程度,其输出通常是一个非负值;二是损失函数输出的非负实值可以作为反馈信号来对分类器参数进行调整,以降低当前示例对应的损失值,提升分类器的分类效果。
- 1.3损失函数的一般数学定义:

PS:W中包含了 权值向量w 和 偏移量b 。
- 2.多类支撑向量机的损失(一种具体的方法)
- 2.1多类支撑向量机-第i张图片在第j号分类标签的权值向量下的分数Sij的计算(注意体会)
 * 2.2 第i个样本的多类支撑向量机损失函数定义如下:(i、j含义与上文有变化,请注意理解)
* 2.2 第i个样本的多类支撑向量机损失函数定义如下:(i、j含义与上文有变化,请注意理解)
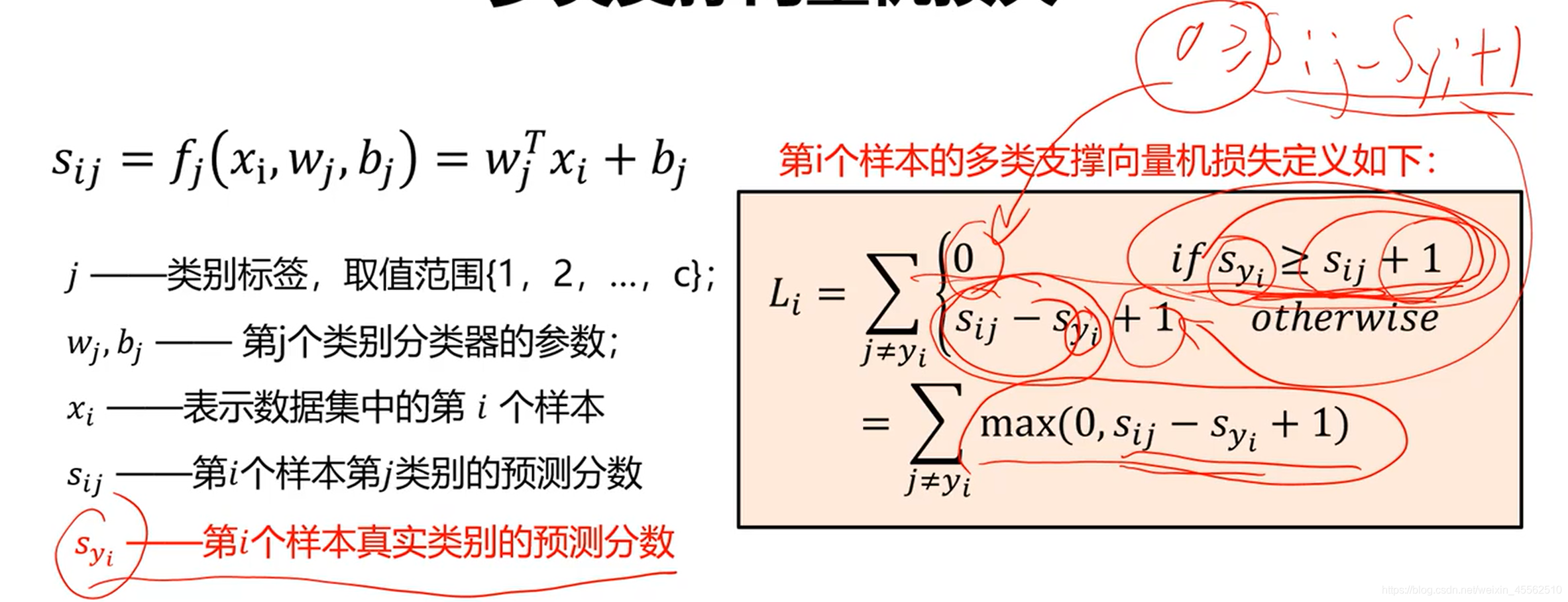
SS:关键在于理解if Syi > Sij + 1;其中 +1 是降低判断的敏感度的,可以不去理解;Syi是在现模型下,i图片应该正确的标签的得分,Sij是现模型下i图片其他标签的得分。若Syi大,则说明模型正确;若Sij大,则说明标签与图片不符,由于是有监督的训练,图片是正确的,则说明标签贴错,则说明模型需调整。调整函数为上图所示。
- 2.1多类支撑向量机-第i张图片在第j号分类标签的权值向量下的分数Sij的计算(注意体会)
- 2.3多类支撑向量机的损失计算的例子
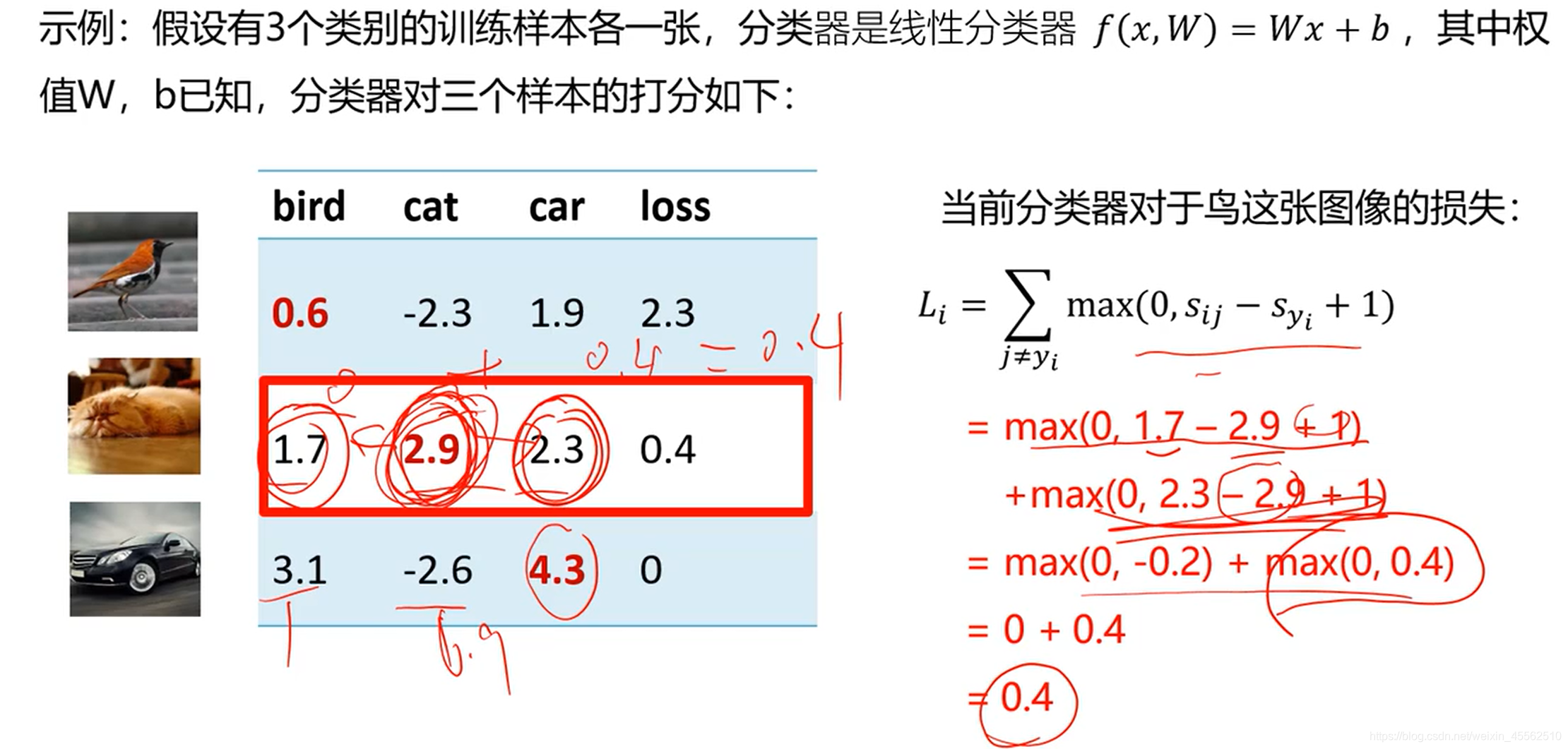
分类器针对整个图集的损失 L :

(视频87:04至89:24,是为不会的同学进行的重复讲解)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









