






OGB的4大上分技巧
抛开GNN架构,只看最简单有效的OGB上分技巧。本文整理的看到的一些OGB上分技巧,并将其总结为以下4类:
模型融合
预训练
平滑
3种Dropout
模型融合
模型融合,可能是打比赛上分最直接也最有效的方法之一了。那么在GNN场景下该怎么做模型融合呢?下面这篇文章给出了自己的答案。

最简单的融合方法可能是融合多个不同的GNN,比如GCN+GAT+GraphSAGE。但是,本文的做法“ an ensemble of three graph neural networks models based on GIN, Bayesian Neural Networks and DiffPool. Our approach outperforms the provided baseline by 7.6%.” 稍微有所不同,将GIN,BNN和DiffPool融合在一起就可以得到显著的提升。比较好奇作者如何想到将BNN也融合进去的。
从下图的实验结果来看,ensemble之后确实在MAE上提升非常显著。
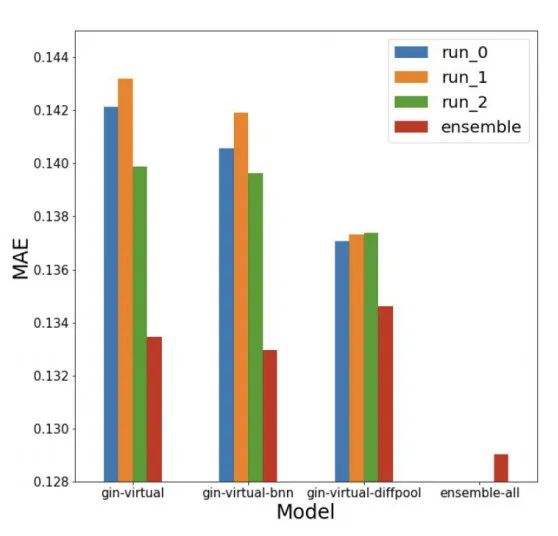
更多细节见原文:
https://arxiv.org/pdf/2106.15529.pdf
预训练
GNN的预训练也是近期研究热点,有很多文章都在做,效果也非常好。
下面这篇文章将多种自监督辅助任务/预训练技术用于提升GNN在OGB上的表现。

首先是Geometry-level的辅助任务。考虑到本文主要做分子图的预测,那么化学键的长度和角度是非常重要的。这可能需要一些化学背景。不过直观的想一些,键长可以一定程度反映相似度,键角可以一定程度反映位置。这对于提升GNN的表示能力是很关键的。相关论文可以参考
19ICML P-GNN Position-aware Graph Neural Networks
20ICLR Geom-GCN- Geometric Graph Convolutional Networks
20NIPS DE Distance Encoding – Design Provably More Powerful Graph Neural Networks for Structural Representation Learning
然后是Topology-level的Context Prediction。这里的context指的就是节点周围的邻居结构。作者这里实际做法比较有趣,将邻居节点排序,映射为字符串context string,再哈希成一个整数ID。不同整数代表了不同的邻居结构。最后,通过一个MLP将节点表示映射为邻居结构的ID,即:希望节点能够预测其周围的结构。
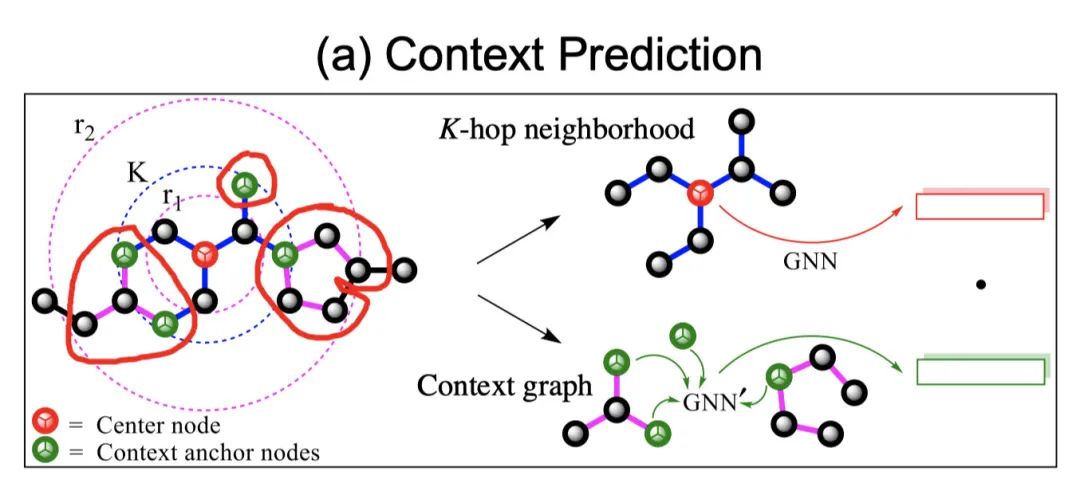
做法和20ICLR Strategies for Pre-training Graph Neural Networks比较像。
具体细节见原文:
https://arxiv.org/pdf/2106.14494.pdf
平滑
平滑公式如下
感觉本质和 19ICLR PPNP Predict then Propagate Graph Neural Networks meet Personalized PageRank 差不多。
虽然作者叫做平滑,但是感觉上述公式本质混合了节点的自身信息+邻居信息,也可以解决过平滑现象。
3种Dropout
综合一下,OGB中的Dropout也有大概3种方式:
DNN中最常见的drop,随机失活一部分神经元。
DropEdge,每次聚合邻居的时候,随机扔掉一些边。可能有助于提升泛化能力。
DropCoefficient,模型权重中小于某个阈值的置0。

















 1594
1594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









