







 本文详细阐述了进程和线程的概念、状态模型及其控制方法,包括进程控制块、三状态模型、挂起模型等,同时对比了用户线程与内核线程的特点。
本文详细阐述了进程和线程的概念、状态模型及其控制方法,包括进程控制块、三状态模型、挂起模型等,同时对比了用户线程与内核线程的特点。
文章目录
进程和线程表征操作系统的运行过程是如何维护的。
7.1 进程
7.1.1 进程的概念
进程是一个具有一定独立功能的程序在一个数据集合上的一次动态执行过程。
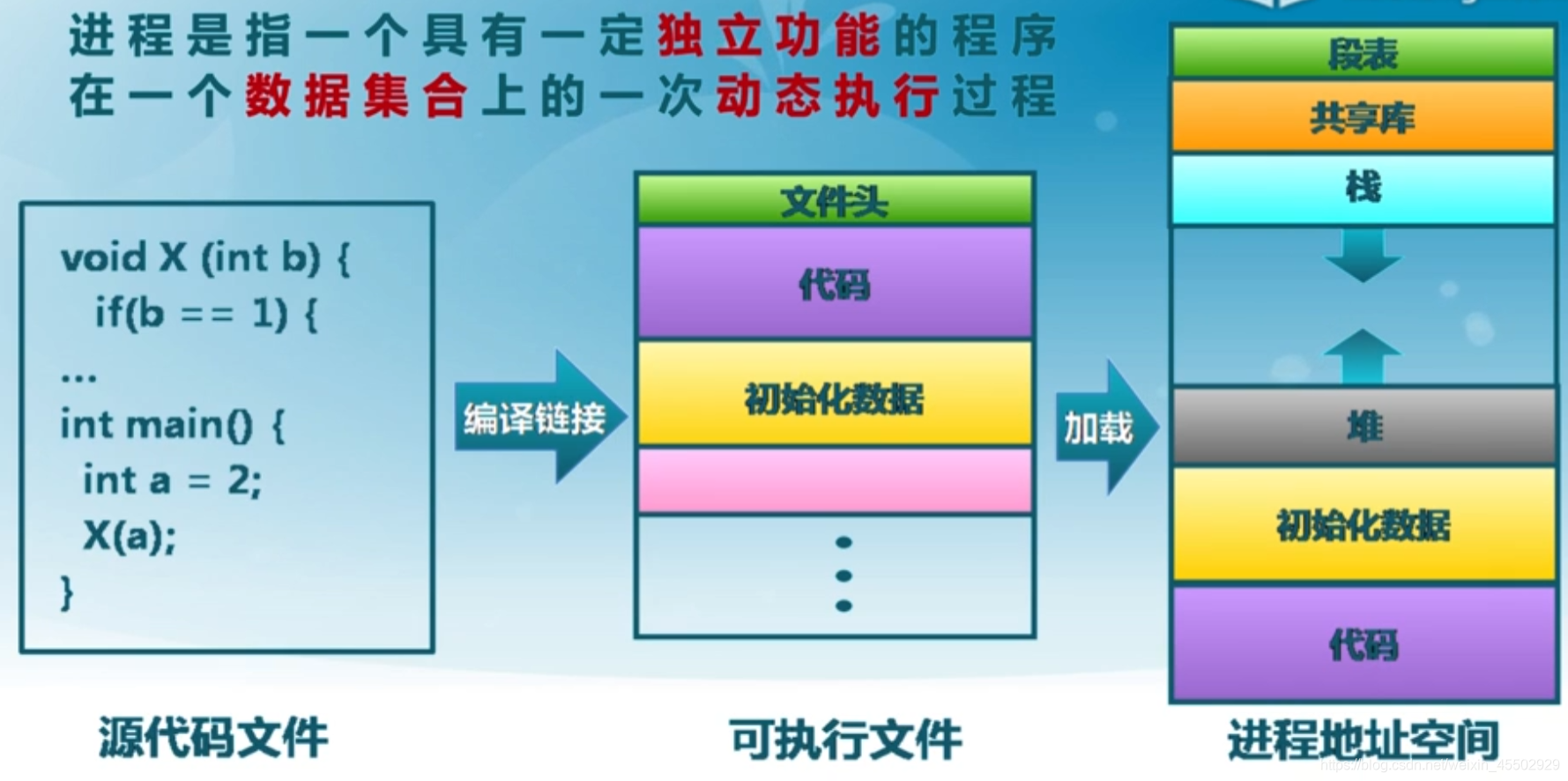
这里特别注意程序和进程之间的关系:
- 程序=文件(静态的可执行文件)
- 进程=程序+执行过程(数据和和运行过程)
- 进程是程序的超集,还包括数据和进程控制块。
区别:
- 同一个程序的多次执行过程对应为不同进程
- 进程是动态的,程序是静态的
- 进程是暂时的,程序是永久的
进程的特征:
- 动态性:动态创建、结束
- 并发性:可以独立调度并占用处理器运行
- 独立性:不同的进程的工作互不影响
- 制约性:因访问共享数据、资源或进程间同步产生制约关系
共享和独立需要有一定限度,进程之间不仅需要去耦合,但不能忘记相互协作的初衷
执行进程需要内存和CPU共同工作:
- 内存负责保存代码和数据
- CPU负责执行指令
7.1.2 进程控制块
进程控制块包括:
- 进程标识信息
- 处理器现场保存
- 进程控制信息
进程控制信息:
- 调度和状态信息
- 进程间通信
- 存储管理信息
- 进程使用资源
- 数据结构连接
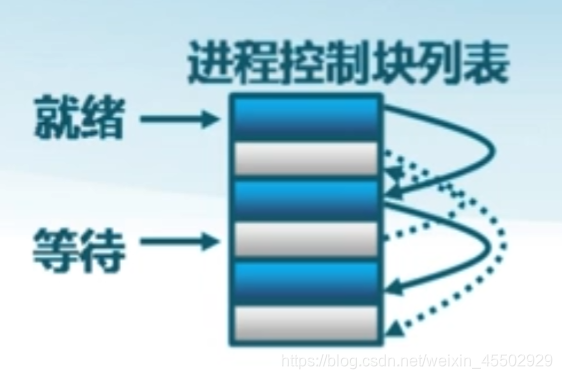
进程控制块的组织:
-
链表:各种状态形成不同的链表,多个状态对应多个不同的链表
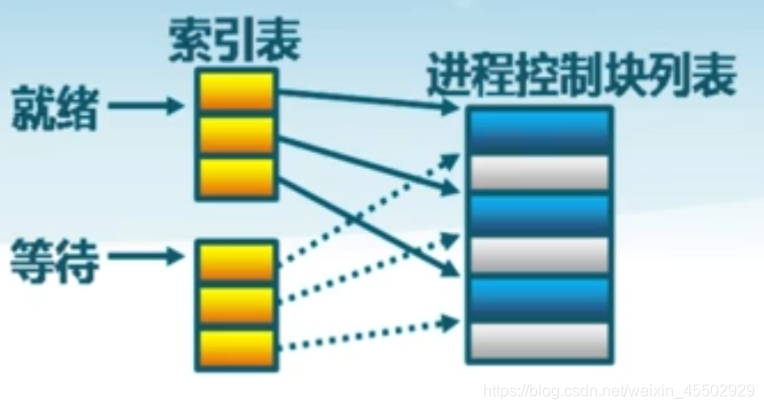
-
索引表:同一个状态的进程归入一个索引表(由索引指向)
7.1.3 进程状态
进程的生命周期划分:
创建、执行、等待、抢占、唤醒、结束
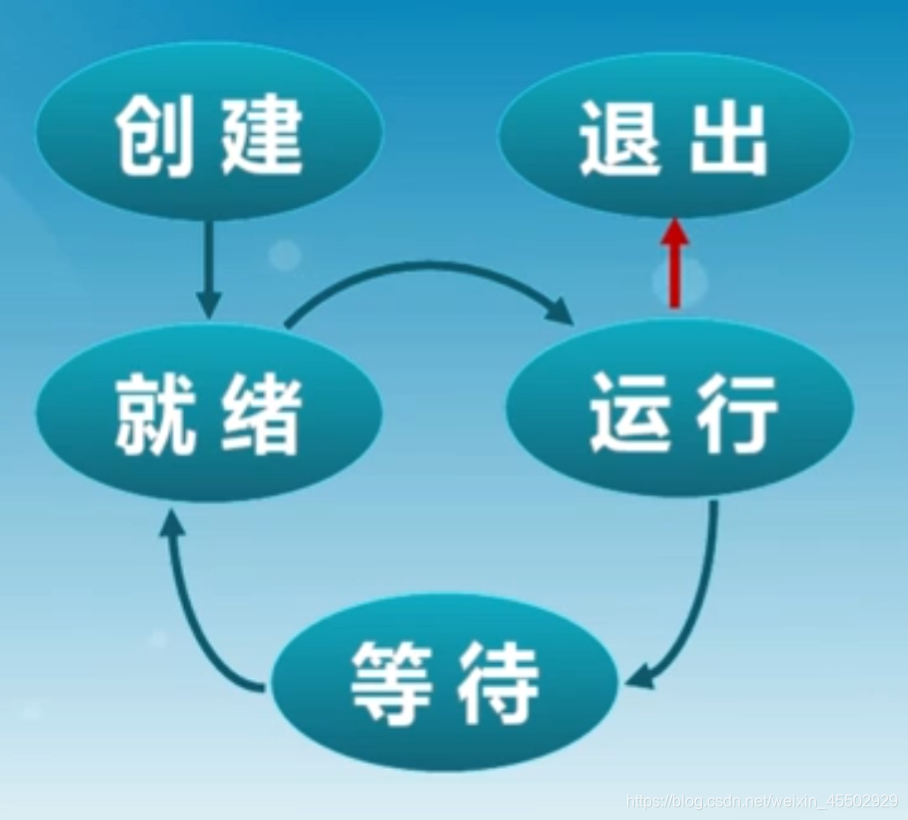
进程创建
- 系统初始化时
- 用户请求创建新进程
- 正在运行的进程执行了创建进程的系统调用
创建好进程之后,放入就绪队列,等待调度。
选择就绪队列中的进程进入运行的选择算法就是调度算法。
进程进入等待(阻塞)的情况
- 请求并等待系统服务,无法马上完成
- 启动某种操作,不能马上完成(比如硬盘读写)
- 需要的数据没有到达
只有进程自身才能知道何时需要等待某种事件的发生。
sleep函数调用就是这种情况。
进程会被抢占的情况:
- 高优先级进程就绪
- 进程执行当前时间用完
进程结束的情况:
- 正常退出(自愿)
- 错误退出(自愿)
- 致命错误(强制)
- 被其他进程kill(强制)
对于单个进程是上述的循环,但操作系统整体的运行模式是多个进程之间交替切换。
7.1.4 三状态进程模型
上节中介绍的五个状态,有三个是核心,构成主要的循环。这就是经典的三状态进程模型。
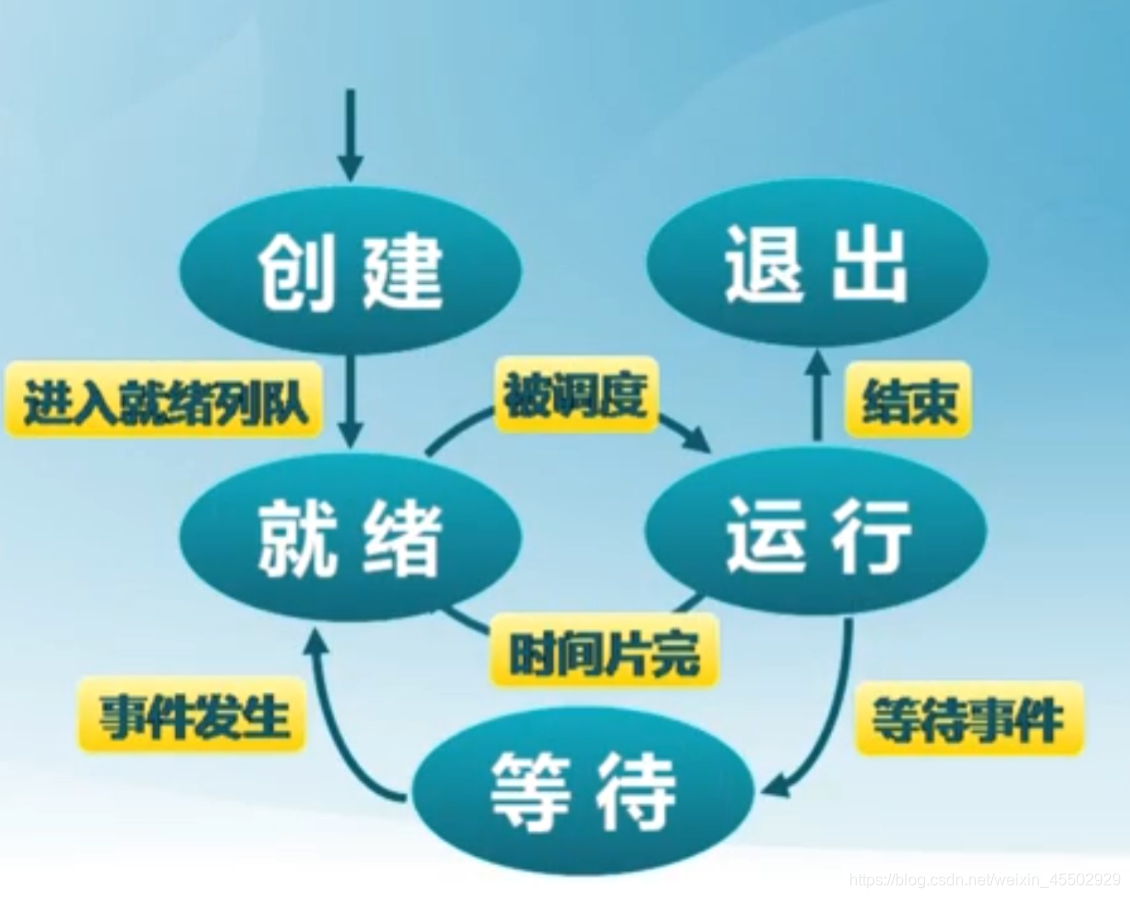
- 当程序被创建完成之后,一切就绪准备运行时,变为就绪状态
- 处于就绪状态的进程被进程调度程序选中后,就分配到处理器上来运行,进入运行状态。
- 处于运行状态的进程在其运行过程中,由于分配给它的时间片用完,让出处理器,返回就绪状态。
- 当进程请求某资源且必须等待时,进入等待状态。
- 进程要等待某时间到来时,它从阻塞状态变到就绪状态。
- 当进程表示它已经完成或者因出错,进程由运行过程退出。
在看OS源码时,注意寻找每个状态的标识符和入口。
7.1.5 挂起进程模型
在上述的三状态模型的基础上,我们引入外存,增加一系列挂起状态,包括就绪挂起和等待挂起,从而进一步缓解内存的空间压力。
将优先级较低的的进程挂起,是通用的策略。
几个典型的状态变迁如下:
- 等待到等待挂起:没有进程出于就绪态,或就绪过程需要挤占更多内存
- 就绪到就绪挂起:高优先级等待进程遇到低优先级就绪进程,认为前者将更快就绪,所以后者就绪挂起
- 运行到就绪挂起:高优先级等待挂起因事件出现而进入就绪挂起。(我的理解是一种特殊的插队机制)
- 等待挂起到就绪挂起:当有等待挂起进程因相关事件出现而发生转换
- 就绪挂起到就绪:没有就绪进程或挂起就绪进程优先级高于就绪进程
- 等待挂起到等待:当一个进程释放足够内存,并有高优先级等待挂起进程
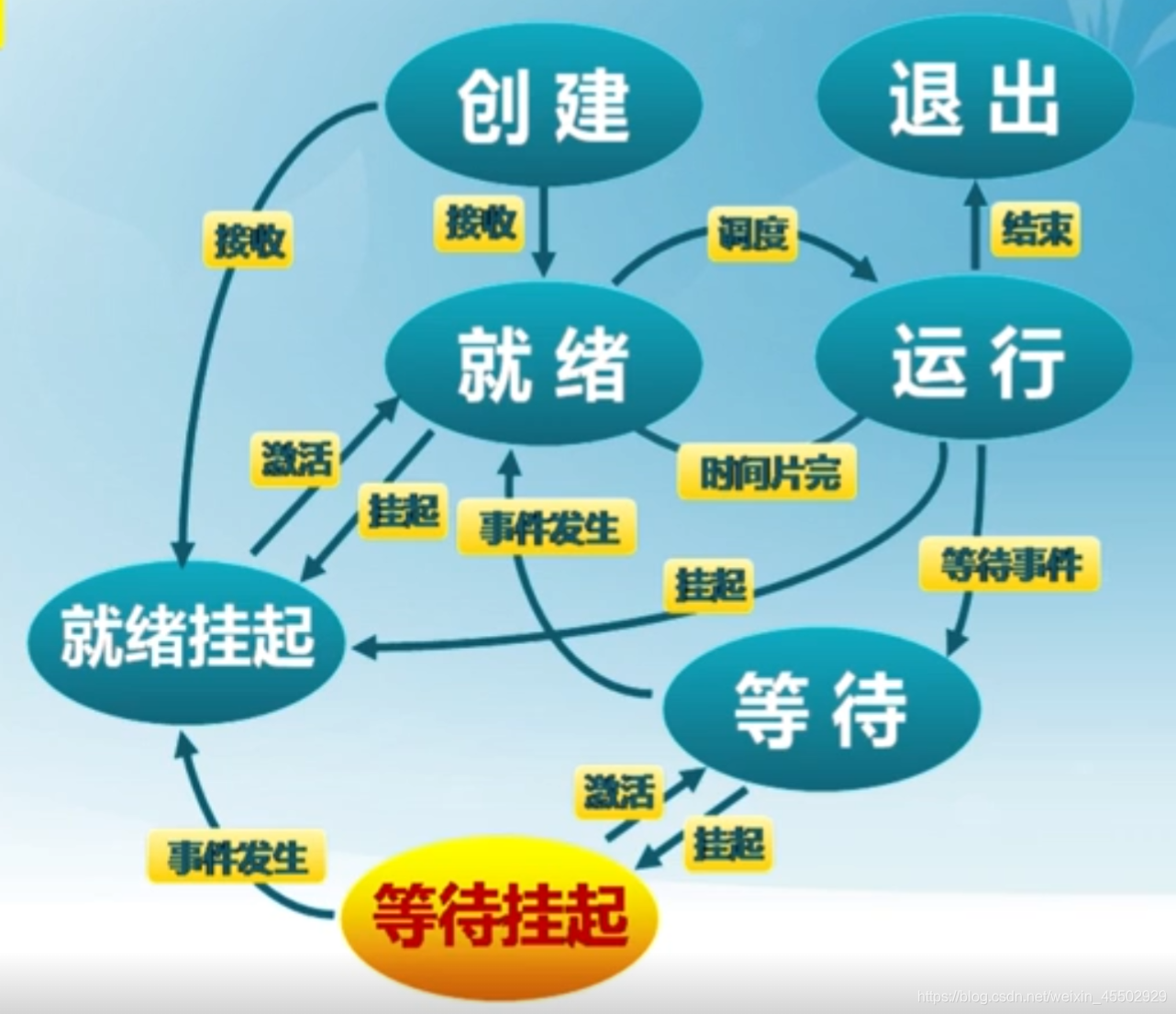
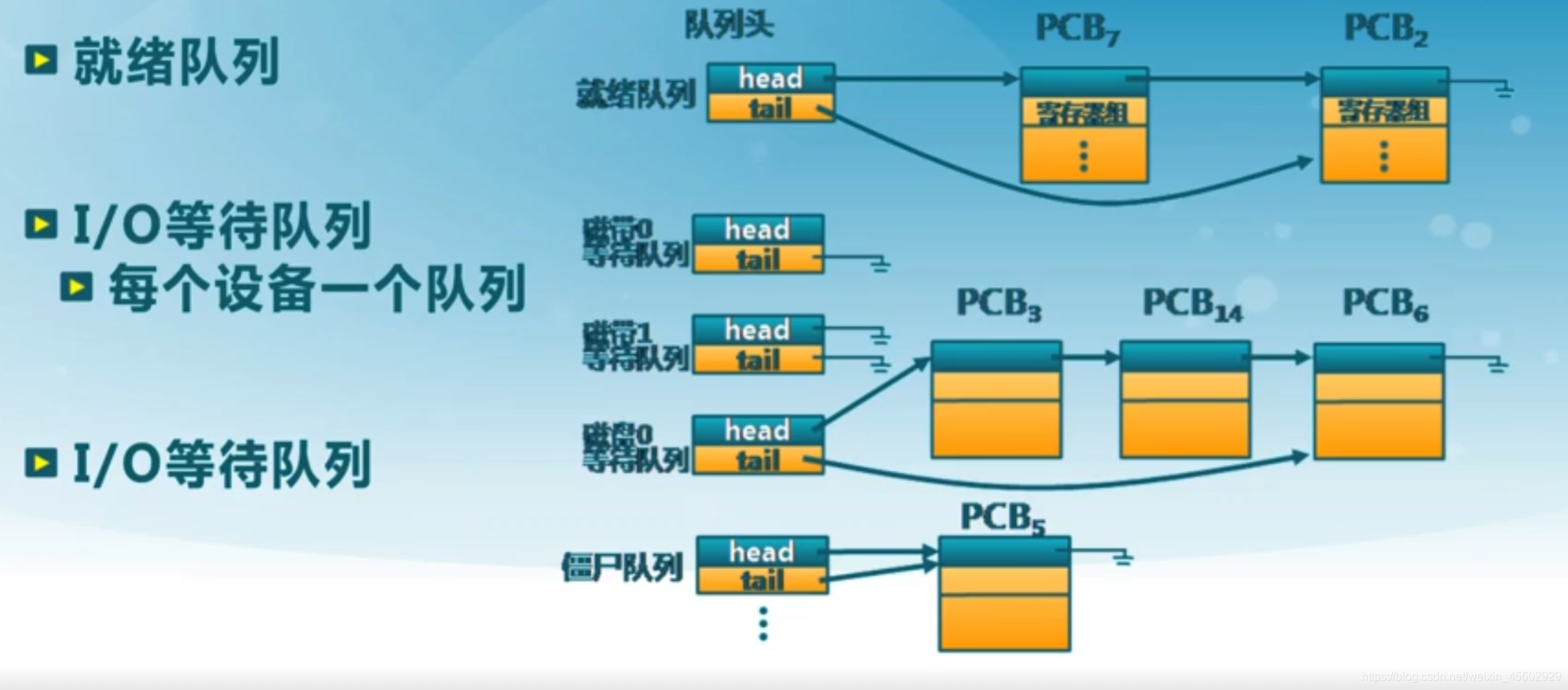
7.1.6 状态队列
(此部分略讲)
由操作系统来维护一组队列,来表示系统中所有进程的当前状态,称为状态队列。在调度过程中状态变化时,PCB在状态队列间切换。
7.2 线程
7.2.1 背景和需求
如果要实现可同步进行且相互通信的三个流程,用进程就不行了。
进程可以实现了并行化,但是
- 进程间相对隔离的性质和这个目标相悖
- 使用进程的开销过大,需要各自开辟一块相类似的进程控制块
所以我们引入在同一个进程当中并行设计的线程机制。
7.2.2 线程的概念
线程的概念:
- 进程的一部分
- 描述指令流执行状态,是进程中指令执行流的最小单元
- 是CPU调度的基本单位。
- 线程之间可以并发执行,其之间共享相同的地址空间。
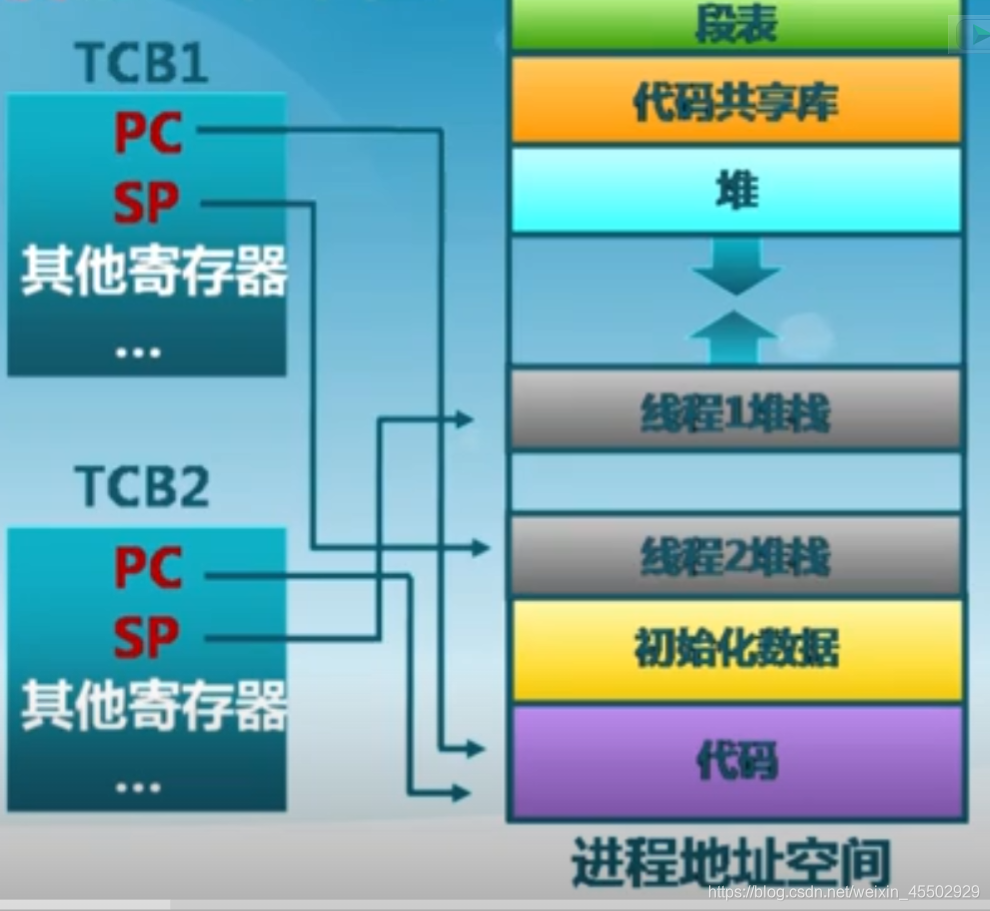
在这种层面上讲,进程是资源分配单位,线程是CPU调度单位,线程只描述在进程资源环境中的指令流执行状态,只有独享指令流执行的必要资源,比如寄存器和栈。
这使得进程内部并发成为可能。
线程机制的优点:
- 一个进程中存在多个线程
- 各个线程之间可以并发执行
- 各个线程间可以共享地址空间和文件等资源
- 不通过内核就可以进行高效的线程间通信
但由于各个线程之间去耦合程度较低,因而如果一个线程出现问题,其他线程可能随之崩溃。
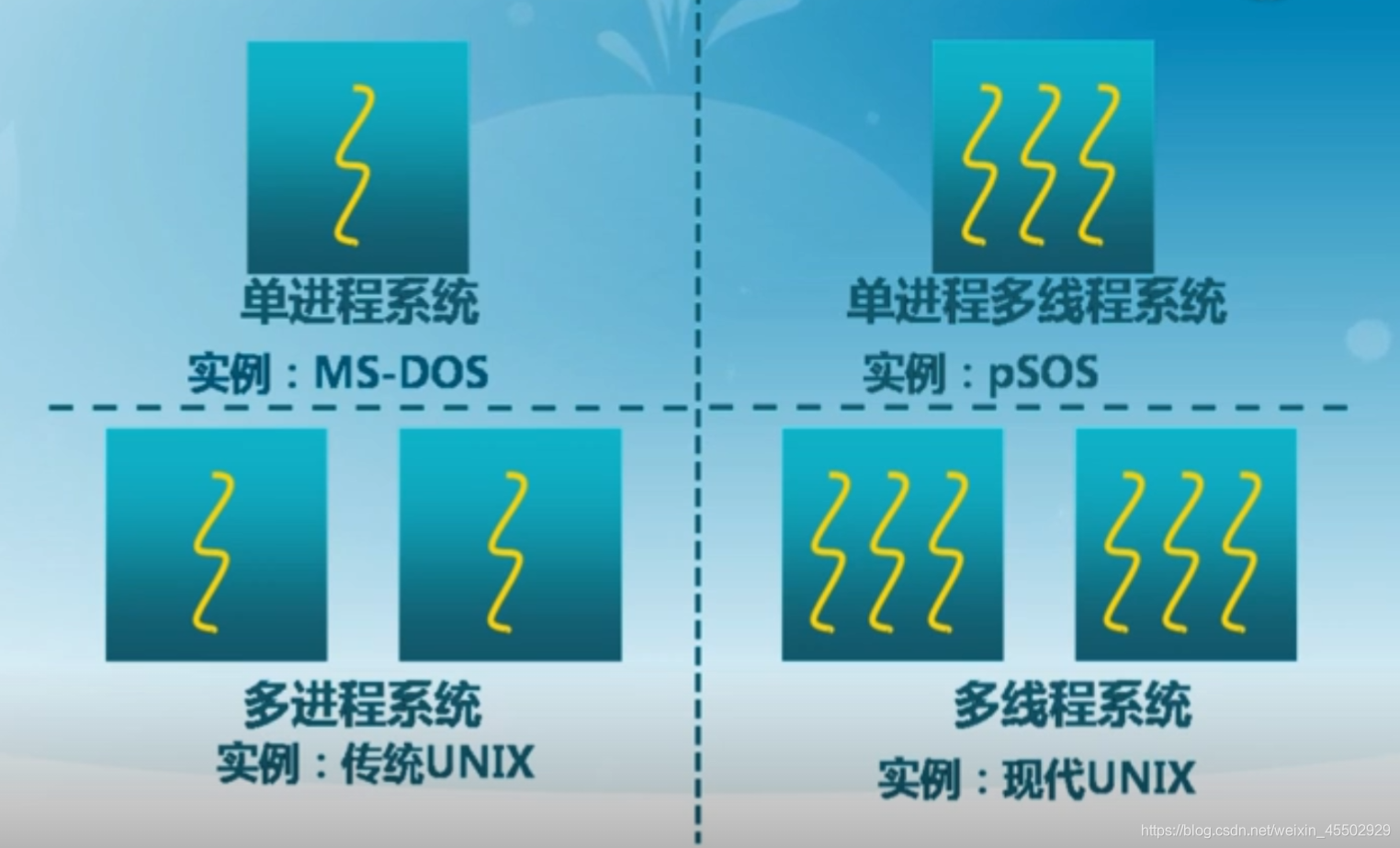
历史上不同操作系统对于并行机制的支持
7.2.3 用户线程
线程有三种主要的实现模式,本节的用户线程和下一节的内核线程是两种主流的实现方式。
- 用户线程是在用户空间中实现的,例如POSIX Pthreads,Mach C-threads,Solaris threads。
- 内核线程是在操作系统内核中实现的,Windows,Solaris,Linux等后来都有支持。
- 后来也出现了结合了用户线程和内核线程两种机制优点的轻权进程,在内核中实现,但也支持用户线程,比如Solaris Lightweight Process
我们首先来讨论用户线程:
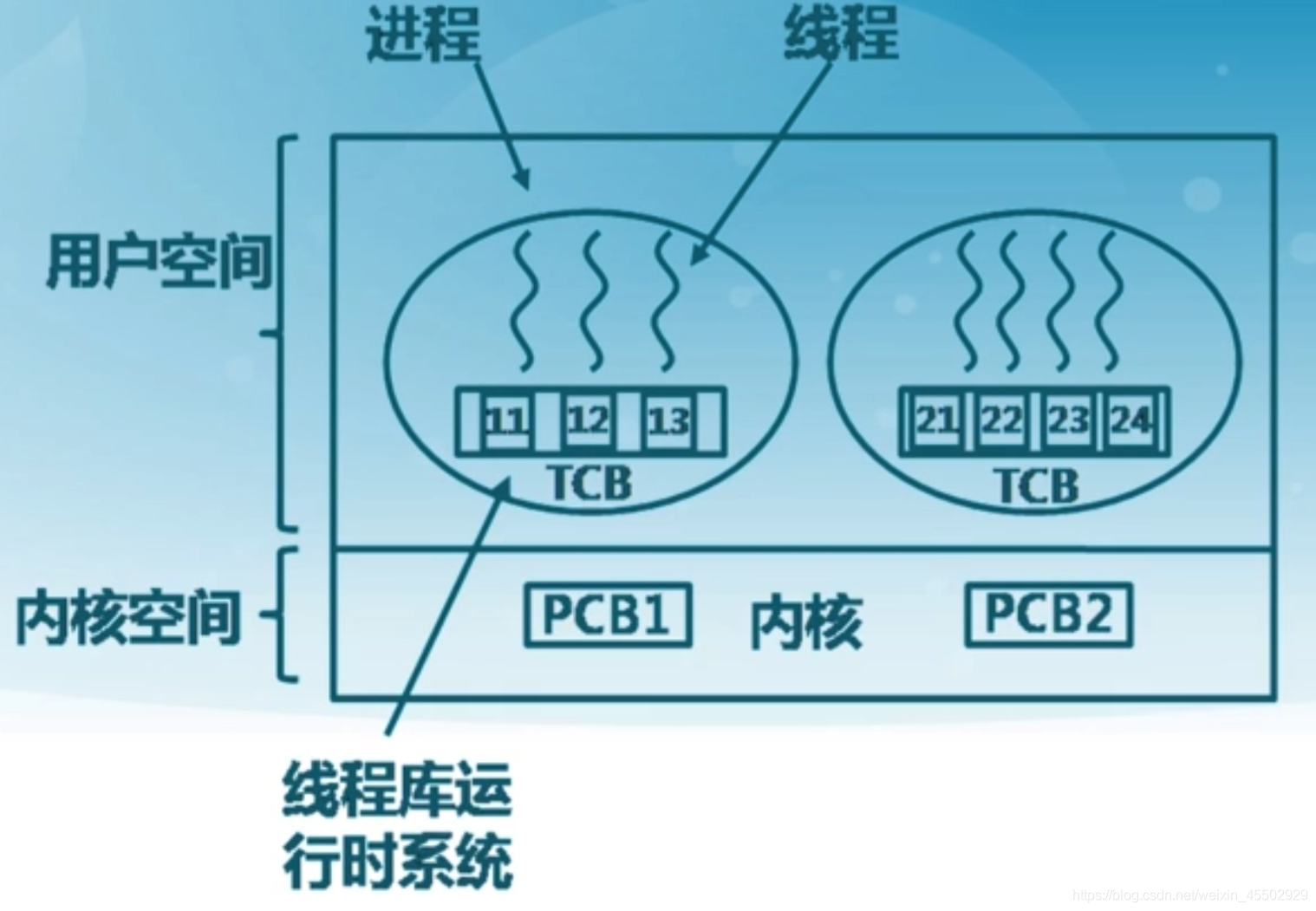
用户线程的特征:
- 不依赖操作系统内核:内核不了解用户线程的存在;可用于不支持线程的OS
- 在用户空间实现线程机制:每个进程由私有的线程控制块(TCB)列表,TCB由线程库函数维护
- 同一进程内的用户线程切换速度快:无需OS内核特权级转换等等开销
- 允许每个进程拥有自己的线程调度算法:程序员可以根据实际情况设计更适合程序的调度
当然也有缺点:
- 线程发起系统调用而阻塞时,则整个进程进入等待。
- 由于不和内核作用,所以不支持基于线程的处理器抢占。
- 只能按进程分配CPU时间:多个线程的进程中,每个线程所能分到的时间片较少
上述的缺点都是由于用户态的设计不与内核作用的结果,一方面不依赖,但一方面也不能实现最好的优化。
这就是工程的权衡。
7.2.4 内核线程
由于上述缺点,所以如果在内核当中实现线程将会更加合适。在内核中直接用PCB链接TCB并进行操作,就可以让处理器更加了解当前工作的线程机制。从而克服上述的问题。
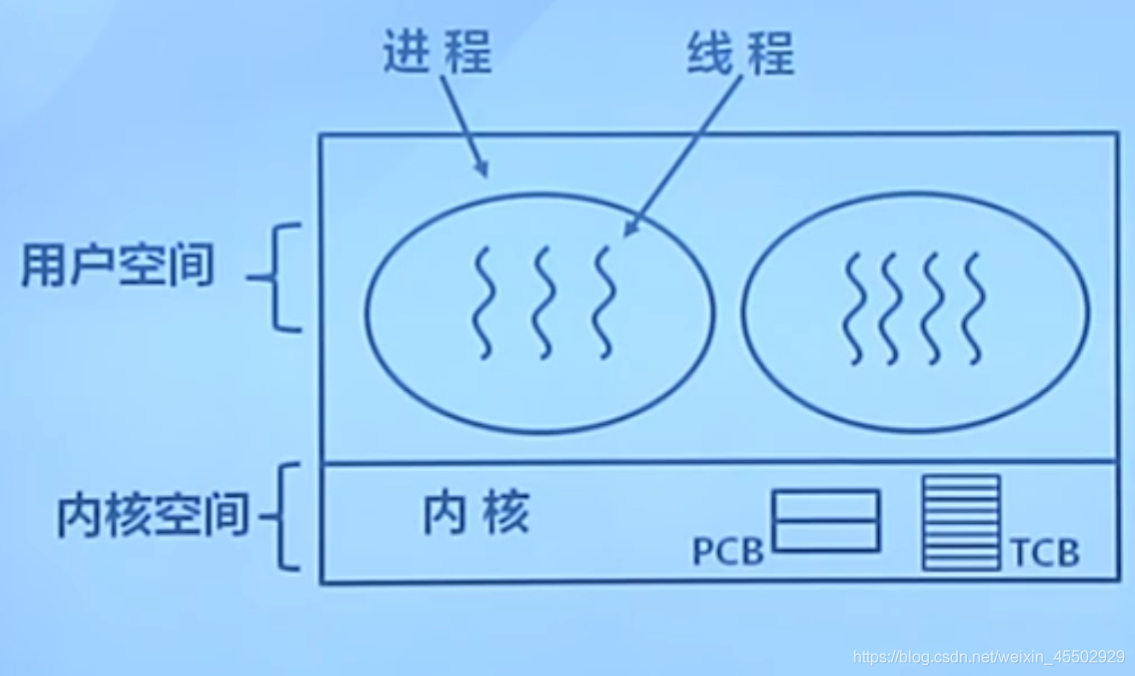
内核线程的特征:
- 由内核维护PCB和TCB:
- 线程执行系统调用而被阻塞时,可以不影响其他线程
- 线程的创建、中止、切换的开销相对较大
- 以线程为单位进行CPU时间分配,进一步优化资源利用
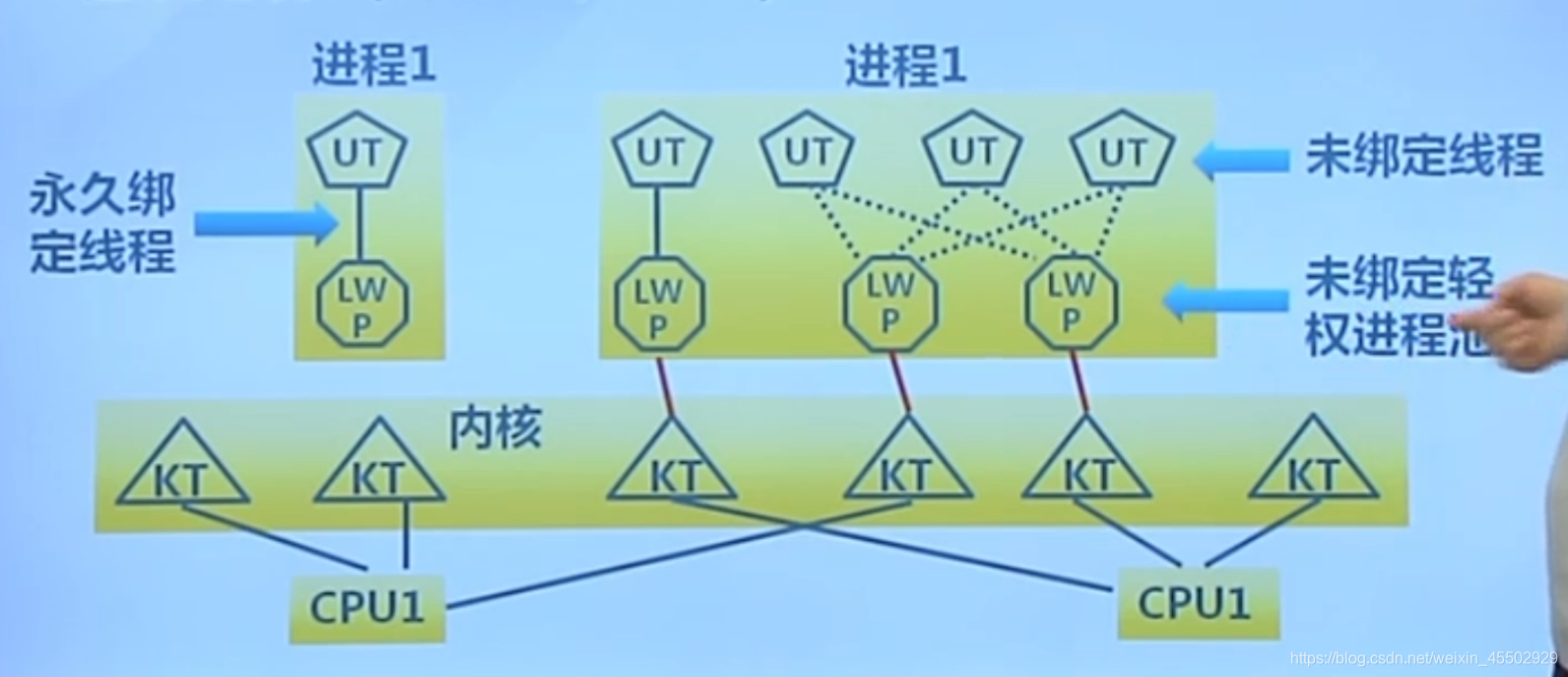
Solaris提出的轻权进程能进一步解决内核线程开销大的问题,一个进程可有一个或多个轻权进程,每个轻权进程由一个单独的内核线程来支持。但后续由于过于复杂,轻权进程的实际表现并不理想。
常见的实现架构中,用户线程和内核线程的对应关系有如下三种:
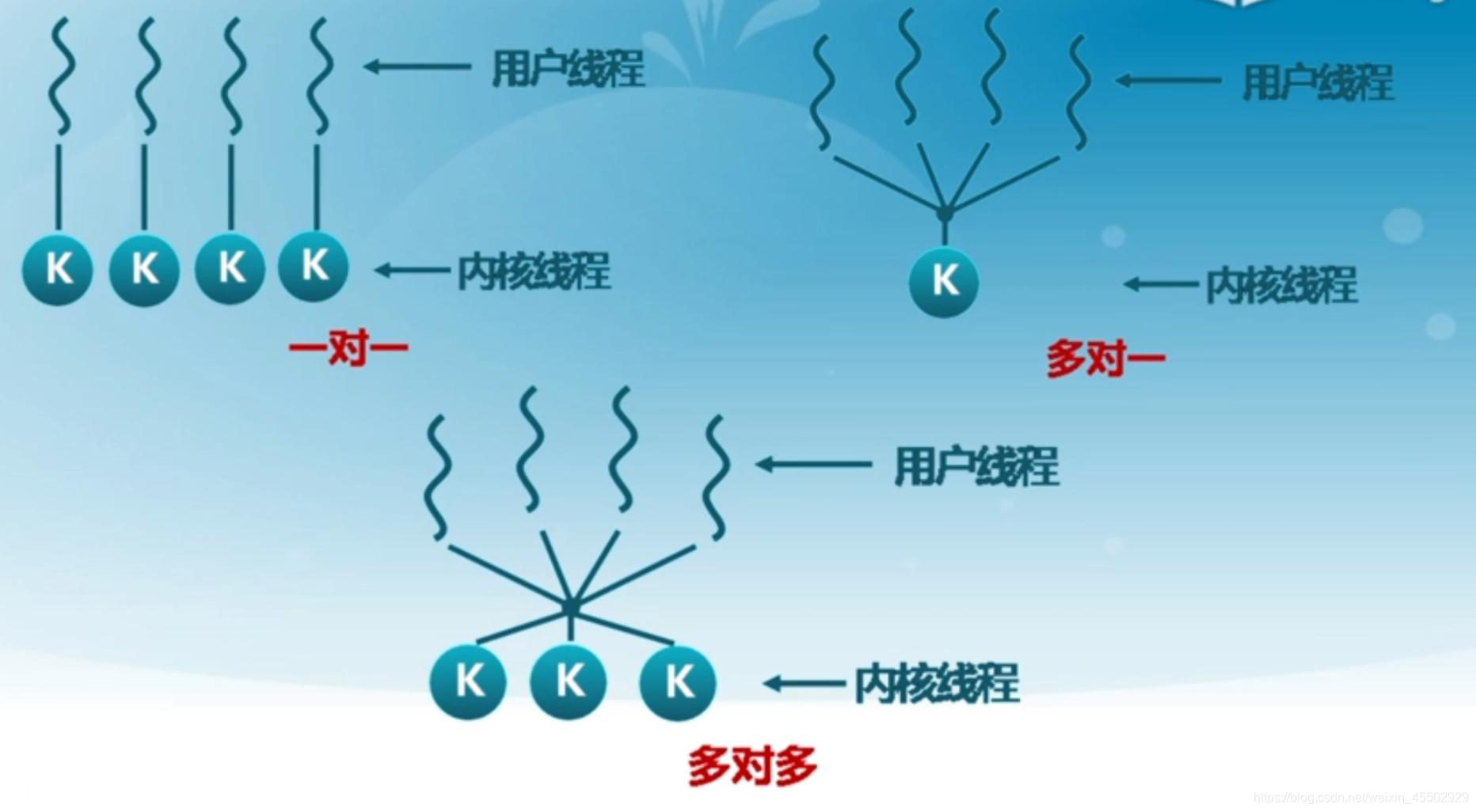
具体的实践告诉我们,一对一的实现是比较好的。
7.3 进程控制
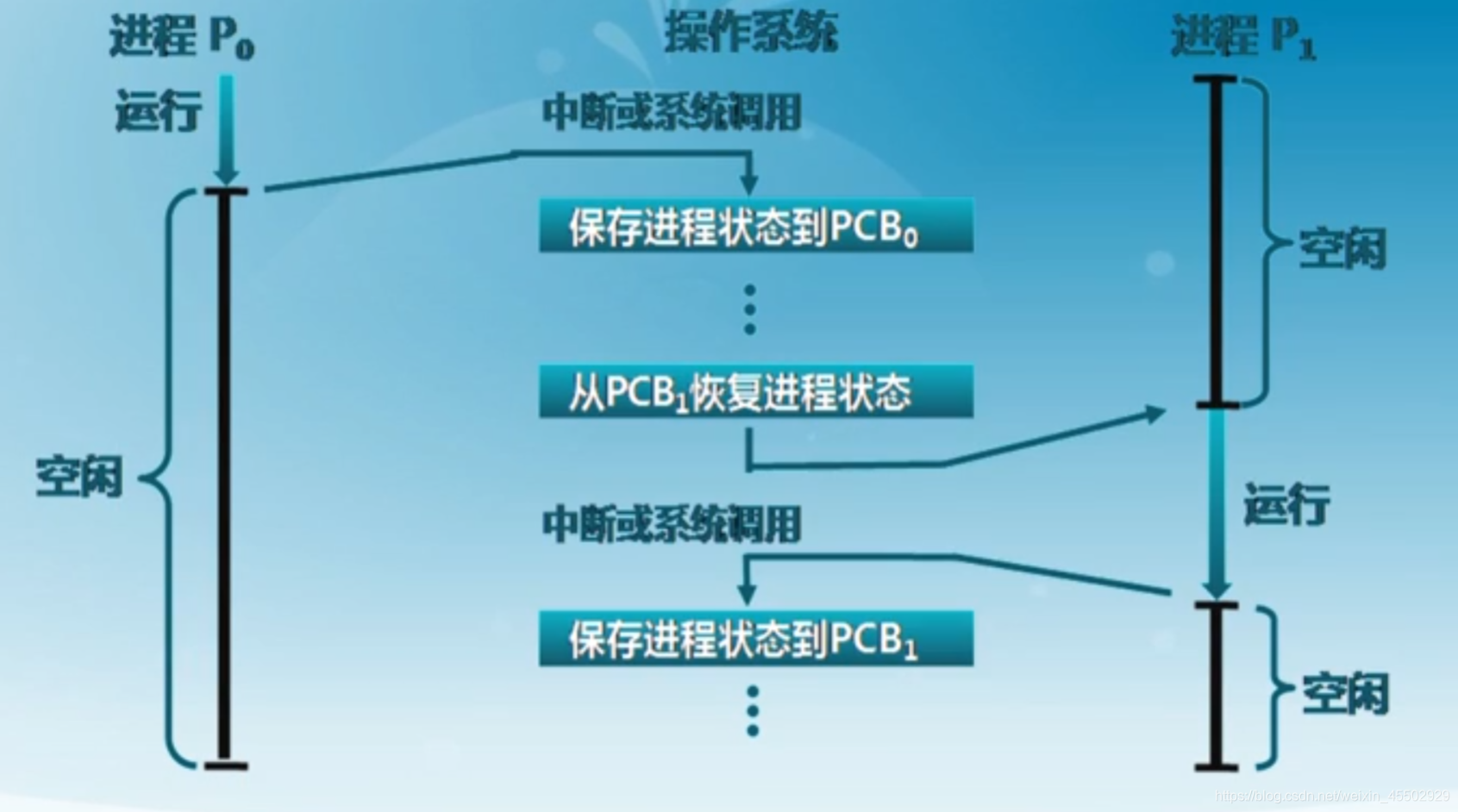
7.3.1 进程切换
也可以叫上下文切换,和OpenGL的上下文类似,相当于一套开发的设定数据的环境和状态机。
重要的上下文信息包括:
- 寄存器
- CPU状态
- 内存地址空间
暂停当前运行进程,从运行状态变为其他状态
调度另一个进程从就绪状态变成运行状态
- 切换前,保存进程上下文
- 切换后,恢复进程上下文
- 要求快速切换
切换的模式图如下
内核为每个进程维护了对应的进程控制块,内核将相同状态的进程的PCB放置在同一队列。
7.3.2 进程创建
利用fork和exec创建进程的示例:
int pid = fork();
if (pid == 0) {
exec("program", argc, argv0, argv1, ...);
}
fork通过复制创建一个继承的子进程
- 复制父进程的所有变量和内存
- 复制父进程的所有CPU寄存器(有一个寄存器除外)
fork()的返回值:
- 子进程的fork()返回0
- 父进程的fork()返回子进程标识符
- fork()的返回值可以方便后续使用,子进程可以使用getpid()获取PID
fork执行过程对于子进程而言,是在调用时间对父进程地址空间的一次复制。fork得到的子进程和父进程只有上述的返回值不同。
利用这个特点就可以进行多进程操作:
main()
{
int childPID;
s_1;
childPID = fork();
if (childPID == 0)
<子进程执行>
else{
<父进程执行>
wait();
}
s_2;
}
这里是一个创建的实例:
int main()
{
pid_t pid;
int i;
for (i = 0; i < LOOP; i++)
{
/*fork another process */
pid = fork();
if (pid < 0){ // if error occurred
fprintf(stderr, "Fork failed");
exit(-1);
}
else if (pid == 0){ //child process
fprintf(stdout, "i=%d, pid=%d, parent pid=%d\n", I, getpid(), getppid());
}
wait(NULL);
exit(0);
}
}
这个代码开始运行之后,每一个现存的进程都会进行fork复制。如下:
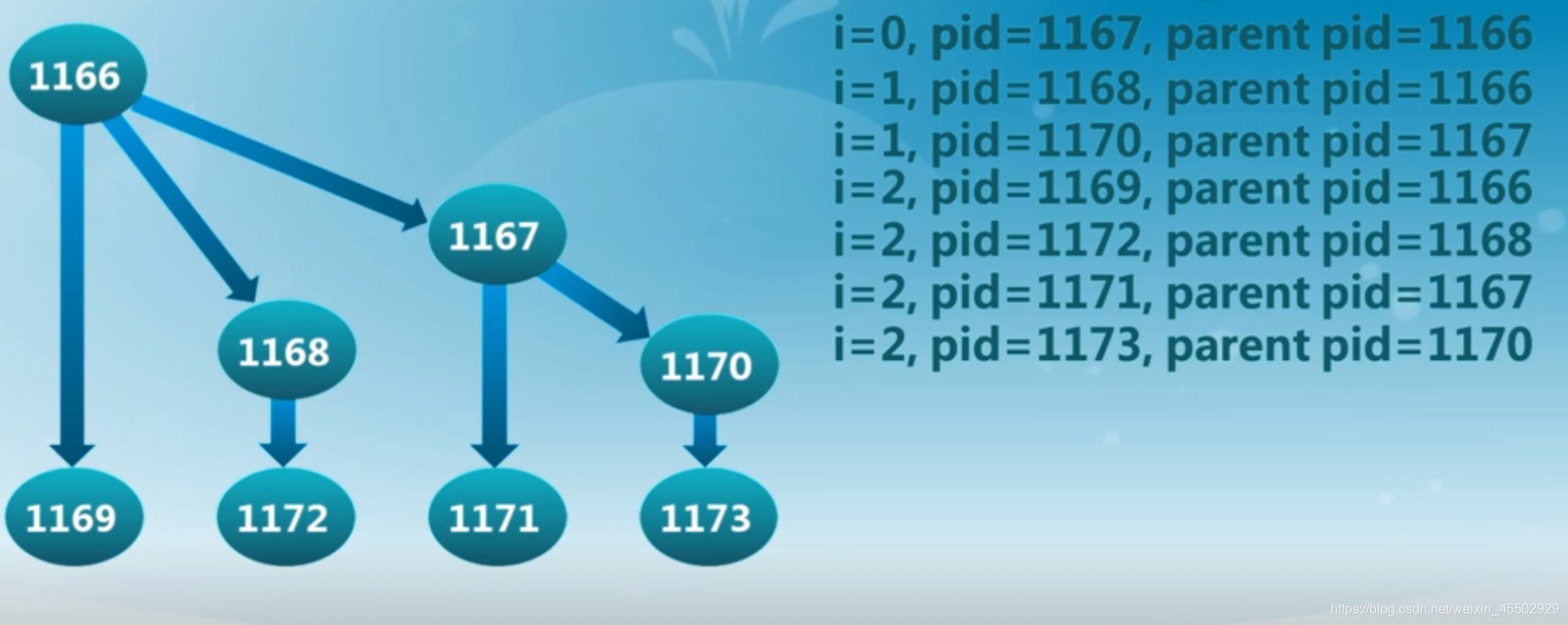
7.3.3 进程加载
执行系统调用exec()时,进行程序加载操作。
exec(),允许程序加载一个完全不同的程序,并从main开始执行(和操作系统启动时的思路类似)
运行进程加载时指定启动参数。(argc,argv)
exec调用成功时,还是相同的进程,但是运行了不同的程序。
代码段、堆栈和堆都完全重写。
在99%的情况下,我们在调用fork()之后,我们都会使用系统调用exec(),加载新程序取代当前运行进程。
因而
- 在fork操作中内存复制是没有作用的
- 子进程将可能关闭打开的文件和链接
因而在创建进程时,可以不再创建一个同样的内存映像,将fork和exec结合起来,成为轻量级fork,接口为vfork()。
现在vfork使用Copy on write技术实现
7.3.4 进程等待和退出
wait()系统调用用于父进程等待子进程的结束
- 子进程结束时,通过exit()向父进程返回一个值
- 父进程通过wait()接受并处理返回值
wait()系统调用的功能:
- 有子进程存活时,父进程进入等待状态,等待子进程的返回结果(exit值作为wait的返回值)
- 有僵尸子进程时,wait立即返回其中一个值
- 无子进程时,wait立刻返回
exit()系统调用用于进程结束时,完成进程资源的回收
- 将调用参数作为进程的“结果”
- 关闭所有打开的文件等占用资源、释放内存、释放大部分进程相关的内核数据结构
- 检查是否父进程存活
- 如果存活,保留结果的值,直到父进程需要它,进入僵尸(zombie)状态
- 如果没有,释放所有的数据结构,进程结果
进程中止是最终的垃圾收集(资源回收)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









