







神经网络入门
nn.Module
点击 PyTorch官网文档
torch.nn 中的 nn 是 neural network 的英文缩写
Module 简介
Module 是我们最常用的一个模块,其作用是给所有的神经网络提供一个基本的骨架

官方案例:
import torch.nn as nn
import torch.nn.functional as F
"""
定义了一个神经网络,名叫Model,继承自 nn.Module类
"""
class Model(nn.Module):
def __init__(self): # 进行初始化
super(Model, self).__init__() # 必须的步骤,调用父类的初始化函数
self.conv1 = nn.Conv2d(1, 20, 5) # 进行卷积,自己设置的操作
self.conv2 = nn.Conv2d(20, 20, 5) # 进行卷积,
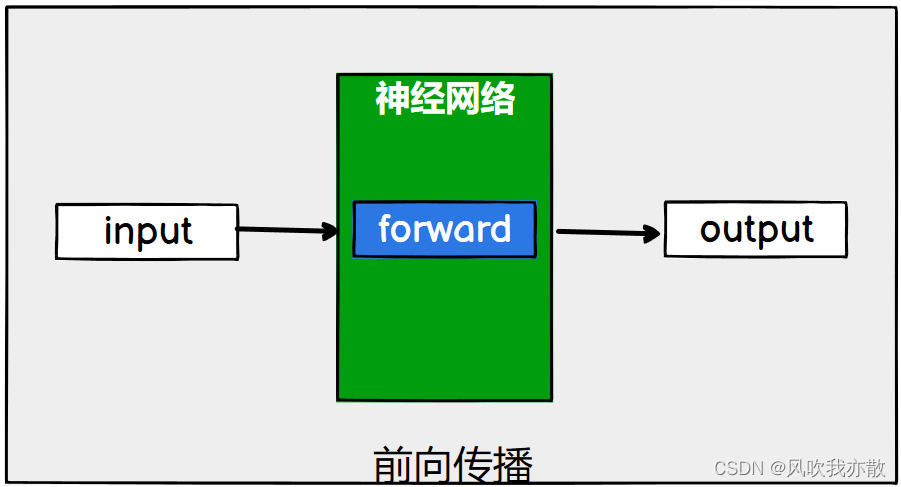
def forward(self, x): # 前向传播; self: 表示是这个类,必需参数; x: 输入
x = F.relu(self.conv1(x)) # 对输入进行卷积[conv1(x)],再进行一次非线性处理[relu()]
return F.relu(self.conv2(x)) # 对上面的结果, 再进行一次卷积和非线性处理并返回
forward:前向传播
Module小案例:
import torch
from torch import nn
"""
创建一个神经网络, 名为Model
作用是将输入加1, 然后返回
"""
class Model(nn.Module):
# 快捷键: CTRL + O
def __init__(self) -> None:
super().__init__()
def forward(self, input):
output = input + 1
return output
model = Model() # 拿 Model 模板创建一个神经网络
x = torch.tensor(1.0) # 给输入赋值
output = model(x) # 将 x 输入神经网络,得到输出
print(output)
Convolution
torch.nn 是对 torch.nn.functional 的封装,在 torch.nn.functional 中找到 conv2d 的介绍
conv2d 是对2d 图像的卷积操作
参数:

- input 输入数据,要求tensor类型 (最小批数,通道个数,高,宽)
- weight 卷积核,即权重(输出通道,一般取1,高,宽)
- bias 偏置
- stride 步进,可以设置成一个数或者一个元组(默认为 1 )
- 一个数:横向步进和纵向步进一样
- 一个元组:(sH, sW),横向步进: sH, 纵向步进: sW
- padding 对图像两边填充n个像素,默认不填充,
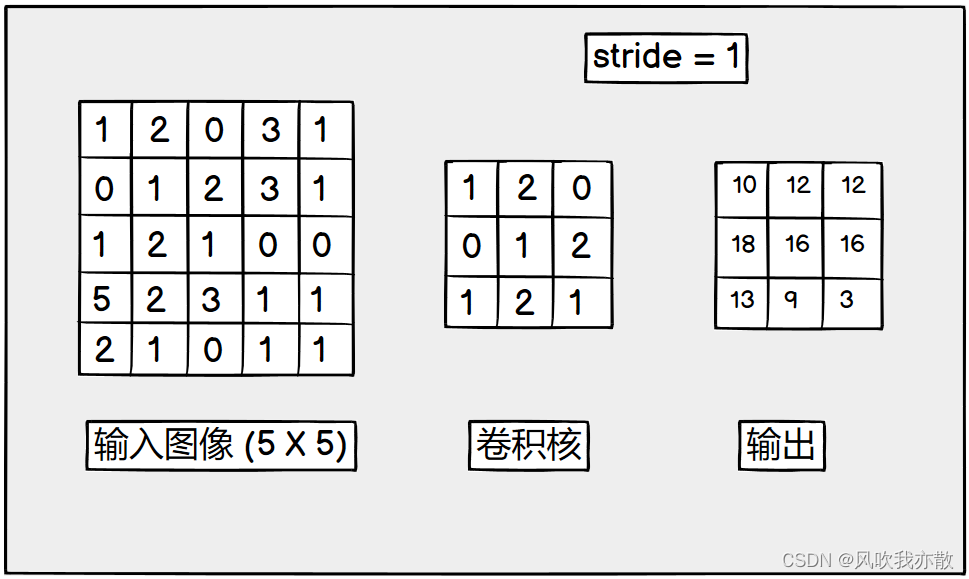
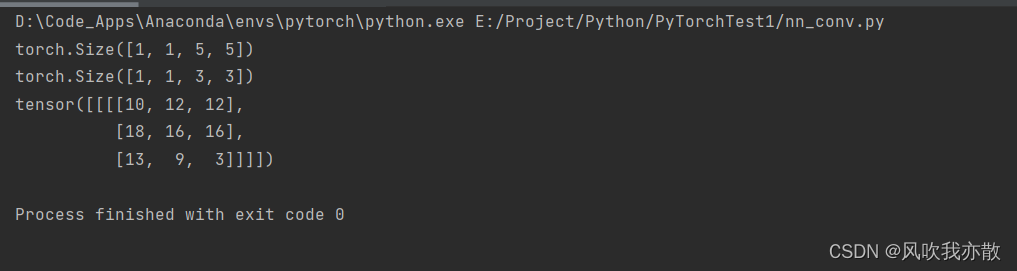
import torch
import torch.nn.functional as F
# input 表示输入,tensor类型; [[]] 表示一个二维矩阵; 有几个 [] 就表示几维矩阵
input = torch.tensor([[1, 2, 0, 3, 1], # 第一行数据
[0, 1, 2, 3, 1], # 第二行数据
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 卷积核
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
"""
上面的 input, kernel 的尺寸只有高和宽, 不符合 conv2d() 参数要求
使用 reshape() 进行尺寸变换
"""
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3,))
print(input.shape)
print(kernel.shape)
output = F.conv2d(input, kernel, stride=1) # 进行卷积
# output = F.conv2d(input, kernel, stride=2)
print(output)
最大池化
最大池化的目的是保留数据的特征但是数据量减少,网络训练更快
nn.MaxPol2d 下采样
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XlUUoOGU-1643364453198)(C:\Users\14158\AppData\Roaming\Typora\typora-user-images\image-20220127100000011.png)]](https://i-blog.csdnimg.cn/blog_migrate/087b9e2d6b79bf417c91e6de6bbd8f61.png)
重要参数:
- kernel_size 取最大值的窗口
- stride 横向和纵向的步进
- padding 填充
- dilation 空洞卷积
- ceil_mode 向上取整 / 向下取整,默认是False
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pMxfmm0e-1643364453199)(C:\Users\14158\AppData\Roaming\Typora\typora-user-images\image-20220127103102007.png)]](https://i-blog.csdnimg.cn/blog_migrate/f8f4032fc6eb4ada39c944dc41718c25.png)
import torch
import torch.nn.functional as F
# input 表示输入,tensor类型; [[]] 表示一个二维矩阵; 有几个 [] 就表示几维矩阵
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1, 2, 0, 3, 1], # 第一行数据
[0, 1, 2, 3, 1], # 第二行数据
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]],dtype=torch.float32) # 将数据转换为float32类型,不然不符合输入数据类型
input = torch.reshape(input, (-1, 1, 5, 5)) # -1表示模糊形状,由 torch 计算
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
self.maxpool2 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output1 = self.maxpool1(input)
output2 = self.maxpool2(input)
return output1,output2
model = Model()
output1,output2 = model(input)
print(output1)
print(output2)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hHJPQsJL-1643364453199)(C:\Users\14158\AppData\Roaming\Typora\typora-user-images\image-20220127104259127.png)]](https://i-blog.csdnimg.cn/blog_migrate/fba42a5b33e020a52e908350c1113739.png)
直接演示:
import torch
import torch.nn.functional as F
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=True, download=True, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool(input)
return output
model = Model()
writer = SummaryWriter("logs_maxpool")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output = model(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
在终端输入:tensorboard --logdir="logs_maxpool"
打开网站,可以看到,图片变得很模糊,但是还能分辨出明显的特征和,这就是最大池化,类似于马赛克。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fwNe3h1Z-1643364453199)(C:\Users\14158\AppData\Roaming\Typora\typora-user-images\image-20220127110821785.png)]](https://i-blog.csdnimg.cn/blog_migrate/5d2a36519d26ff8fa83bf24238ac5788.png)
非线性激活
非线性激活的作用主要是给神经网络引入一些非线性特质
这里简单介绍一下ReLU()
import torch
from torch import nn
from torch.nn import ReLU
input = torch.tensor([[1, -0.5], [-1, 3]])
print(input)
output = torch.reshape(input, (-1, 1, 2, 2))
class Model(nn.Module):
def __init__(self) -> None:
super(Model, self).__init__()
"""
inplace 是否替换,
如果是True, 直接替换
如果是False, 会保留原值,返回一个新值(默认,防止数据丢失)
"""
self.relu = ReLU(inplace=False)
def forward(self, input):
output = self.relu(input)
return output
model = Model()
output = model(input)
print(output)
可以看到 -0.5,-1被截断了,变为0
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pGanx5kN-1643364453200)(C:\Users\14158\AppData\Roaming\Typora\typora-user-images\image-20220127123139543.png)]](https://i-blog.csdnimg.cn/blog_migrate/34827e51e7c09580c533c10538362717.png)
对数据集进行操作:
import torch
import torchvision
from torch import nn
from torch.nn import ReLU
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("dataset", train=True, download=True, transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Model(nn.Module):
def __init__(self) -> None:
super(Model, self).__init__()
"""
inplace 是否替换,
如果是True, 直接替换
如果是False, 会保留原值,返回一个新值(默认,防止数据丢失)
"""
self.relu = ReLU(inplace=False)
def forward(self, input):
output = self.relu(input)
return output
model = Model()
writer = SummaryWriter("logs_relu")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("relu_input", imgs, global_step=step)
output = model(imgs) # 从神经网络中得到输出
writer.add_images("relu_output", output, step)
step += 1
writer.close()
线性层
flatten(): 将输入展成一行
t = torch.tensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]])
torch.flatten(t)
torch.flatten(t, start_dim=1)
简单的网络模型
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Model(nn.Module):
def __init__(self) -> None:
super().__init__()
"""
Conv2d(3, 32, 5)
输入通道数是3
输出通道数是32
卷积核大小是5
"""
self.conv1 = Conv2d(3, 32, 5, padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(1024, 64)
self.linear2 = Linear(64, 10)
def forward(self, input):
input = self.conv1(input) # 对输入卷积
input = self.maxpool1(input) # 池化
input = self.conv2(input) # 卷积
input = self.maxpool2(input) # 池化
input = self.conv3(input) # 卷积
input = self.maxpool3(input) # 池化
input = self.flatten(input) # 展平
input = self.linear1(input) # 线性化
input = self.linear2(input) # 线性化
return input
model = Model()
print(model)
input = torch.ones(64, 3, 32, 32)
output = model(input)
print(output.shape)
引入Sequential()
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Model(nn.Module):
def __init__(self) -> None:
super().__init__()
"""
Conv2d(3, 32, 5)
输入通道数是3
输出通道数是32
卷积核大小是5
"""
self.conv1 = Conv2d(3, 32, 5, padding=2)
self.maxpool1 = MaxPool2d(2)
self.conv2 = Conv2d(32, 32, 5, padding=2)
self.maxpool2 = MaxPool2d(2)
self.conv3 = Conv2d(32, 64, 5, padding=2)
self.maxpool3 = MaxPool2d(2)
self.flatten = Flatten()
self.linear1 = Linear(1024, 64)
self.linear2 = Linear(64, 10)
self.model = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, input):
input = self.model(input)
return input
model = Model()
print(model)
input = torch.ones(64, 3, 32, 32)
output = model(input)
print(output.shape)
在网页上查看:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rNKqIqr1-1643364453200)(C:\Users\14158\AppData\Roaming\Typora\typora-user-images\image-20220127163249367.png)]](https://i-blog.csdnimg.cn/blog_migrate/c1627a1732b52910c4142134edde61be.png)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









