







 本文详细解析了LeNet-5模型,首个成功应用于数字识别的卷积神经网络,介绍了其7层结构,包括卷积层、池化层和全连接层的参数与连接数,并提供了MINIST数据集上的程序设计实例。
本文详细解析了LeNet-5模型,首个成功应用于数字识别的卷积神经网络,介绍了其7层结构,包括卷积层、池化层和全连接层的参数与连接数,并提供了MINIST数据集上的程序设计实例。
LeNet-5模型是第一个成功应用于数字识别问题的卷积神经网络,在MINIST数据集上,LeNet-5模型可达到99.2%的正确率。LeNet模型总共有7层,下图展示了LeNet-5模型的架构。
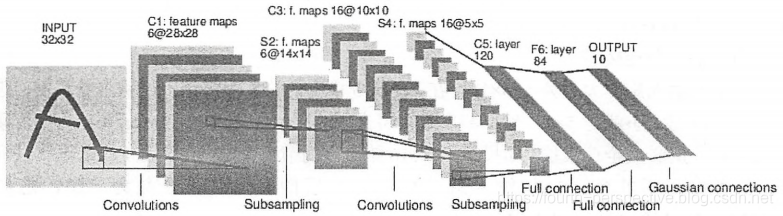
1.LeNet-5模型结构说明:
第一层 卷积层:
输入为原始图像像素,大小为32x32x1;
该卷积层过滤器尺寸为5x5,深度为6,不使用全0填充,步长为1;
输出尺寸为32-5+1=28(非全0填充),深度为6;
该层参数个数为5x5x1x6+6=156个参数,其中6个为偏置项参数;
该层卷积层节点数为28x28x6=4704,每个节点和5x5=25个当前层节点相连,本卷积层总共有4704x(25+1)=122304个连接。
第二层 池化层:
这一层的输入为上一层的输出,是一个28x28x6的节点矩阵;
该池化层过滤器尺寸为2x2,长和宽的步长均为2;
输出尺寸为14x14x6。
第三层 卷积层:
本层输入矩阵大小为14x14x6;
该卷积层过滤器尺寸为5x5,深度为16,不使用全0填充,步长为1;
输出矩阵大小为10x10x16;
本层参数个数5x5x6x16+16=2416个参数,共有10x10x16x(25+1)=41600个连接。
第四层 池化层:
输入矩阵大小为10x10x16;
过滤器尺寸为2x2,步长为2;
输出矩阵大小为5x5x16.
第五层 全连接层:
输入矩阵大小为5x5x16;
过滤器尺寸为5x5,与全连接层没有区别;
输出节点数为120,共有5x5x16x120+120=41820个参数。
第六层 全连接层:
输入节点数为120个;
输出节点数为84个,共有120x84+84=10164个参数。
第七层 全连接层:
输入节点数为84个;
输出节点数为10个,共有84x10+10=850个参数。
2.LeNet-5模型程序设计(MINIST):
import tensorflow as tf
# 配置神经网络的参数。
INPUT_NODE = 784
OUTPUT_NODE = 10
IMAGE_SIZE = 28
NUM_CHANNELS = 1
NUM_LABELS = 10
# 第一层卷积层的尺寸和深度。
CONV1_DEEP = 32
CONV1_SIZE = 5
#第二层卷积层的尺寸和深度。
CONV2_DEEP = 64
CONV2_SIZE = 5
# 全连接层的节点个数。
FC_SIZE = 512
# 定义卷积神经网络的前向传播过程。参数train用于区分训练过程和测试过程。
def inference(input_tensor,train,regularizer):
# 申明第一层卷积层的变量并实现前向传播过程。
# 输出为28x28x32的矩阵。
with tf.variable_scope('layer1-conv1'):
conv1_weights = tf.get_variable(
"weight",[CONV1_SIZE,CONV1_SIZE,NUM_CHANNELS,CONV1_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv_biases = tf.get_variable("bias",
[CONV1_DEEP],initializer=tf.constant_initializer(0.0))
# 使用边长为5,深度为32的过滤器,移动步长为2,全0填充。
conv1 = tf.nn.conv2d(input_tensor,conv1_weights,strides=[1,1,1,1],padding='SAME')
relu1 = tf.nn.relu(tf.nn.bias_add(conv1,conv1_biases))
# 实现第二层池化层的前向传播过程,选用最大池化层。过滤器边长为2,全0填充且步长为2。
# 输入28x28x32矩阵;输出14x14x32矩阵。
with tf.name_scope('layer2-pool1'):pool1 = tf.nn.max_pool(
relu1,ksize-[1,2,2,1],strides=[1,2,2,1],padding='SAME')
# 申明第三层卷积层的变量并实现前向传播过程。
# 输入14x14x32的矩阵;输出14x14x64的矩阵。
with tf.variable_scope('layer3-conv2'):
conv2_weights = tf.get_variable(
"weight",[CONV2_SIZE,CONV2_SIZE,CONV1_DEEP,CONV2_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get.variable(
"bias",[CONV2_DEEP],
initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(
pool1,conv2_weights,strides=[1,1,1,1],padding='SAME')
relu2 = tf.nn.relu(tf.nn.bias_add(conv2,conv2_biases))
# 实现第四层池化层的前向传播过程。
# 输入为14x14x64矩阵;输出为7x7x64的矩阵。
with tf.name_scope('layer4-pool2'):
pool2 = tf.nn.max_pool(
relu2,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
# 将第四层池化层的输出转化为第五层全连接层的输入格式。
# 第四层输出为7x7x64矩阵,但是第五层需要的输入格式为向量,需要将7x7x64的矩阵拉成一个向量。
# pool2.get_shape函数可以得到第四层输出矩阵的维度而不需要手工计算。
pool_shape = pool2.get_shape().as_list()
nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
# 通过tf.reshape函数将第四层的输出变成一个batch的向量
reshaped = tf.reshape(pool12,[pool+shape[0],nodes])
# 申明第五层全连接层的变量并实现前向传播过程。
# 输入是拉直的一组向量,向量长度为3136,输出是一组长度为512的向量。
with tf.variable_scope('layer5-fcl'):
fcl_weights = tf.get_variable(
"weight",[nodes,FC_SIZE],
initializer=tf.truncatede_normal_initializer(stddev=0.1))
if regularizer !=None:
tf.add_to_collection('losses',regularizer(fcl_weights))
fcl_biases = tf.get_variable(
"bias",[FC_SIZE],initializer=tf.constant_initializer(0.1))
fcl = tf.nn.relu(tf.matmul(reshaped,fcl_weights) + fcl_biases)
if train: fcl = tf.nn.dropout(fcl, 0.5)
# 申明第六层全连接层的变量并实现前向传播过程。
# 输入为长度512的向量;输出为一组长度10的向量。通过Softmax得到最后分类结果。
with tf.variable_scope('layer6-fc2'):
fc2_weights = tf.get_variable(
"weight",[FC_SIZE,NUM_LABELS],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer !=None:
tf.add_to_collection('losses',regularizer(fc2_weights))
fc2_biases = tf.get_variable(
"bias",[NUM_LABELS],
initializer=tf.constant_initializer(0.1))
logit = tf.matmul(fc1, fc2_weights) + fc2_biases
# 返回第六层的输出。
return logit


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









