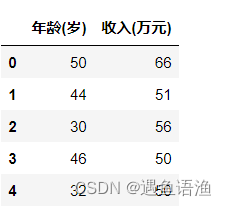
1.读取数据
import pandas as pd
data = pd.read_excel('客户信息.xlsx')
data.head()
2.可视化展示
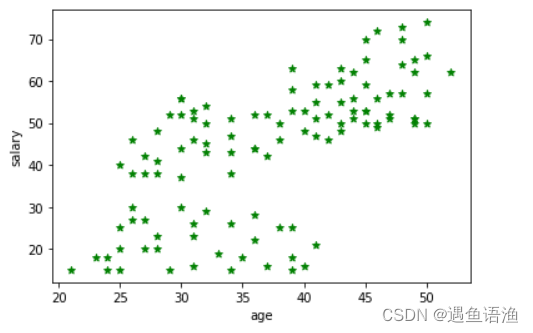
import matplotlib.pyplot as plt
plt.scatter(data.iloc[:, 0], data.iloc[:, 1], c="green", marker='*') # 以绿色星星样式绘制散点图
plt.xlabel('age') # 添加x轴名称
plt.ylabel('salary') # 添加y轴名称
plt.show()
3.数据建模
from sklearn.cluster import KMeans
kms = KMeans(n_clusters=3, random_state=123)
kms.fit(data)
label = kms.labels_
label = kms.fit_predict(data)
print(label)

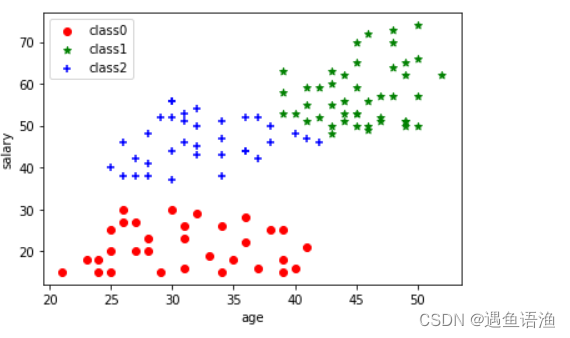
4.建模效果可视化展示
plt.scatter(data[label == 0].iloc[:, 0], data[label == 0].iloc[:, 1], c="red", marker='o', label='class0') # 以红色圆圈样式绘制散点图并加上标签
plt.scatter(data[label == 1].iloc[:, 0], data[label == 1].iloc[:, 1], c="green", marker='*', label='class1') # 以绿色星星样式绘制散点图并加上标签
plt.scatter(data[label == 2].iloc[:, 0], data[label == 2].iloc[:, 1], c="blue", marker='+', label='class2') # 以蓝色加号样式绘制散点图并加上标签
plt.xlabel('age') # 添加x轴名称
plt.ylabel('salary') # 添加y轴名称
plt.legend() # 设置图例
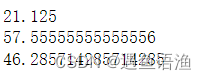
5.查看各标签人的收入均值
print(data[label == 0].iloc[:, 1].mean()) # 看下分类为标签0的人的收入均值,iloc[:, 1]为data表格的第二列,也即“收入”列
print(data[label == 1].iloc[:, 1].mean())
print(data[label == 2].iloc[:, 1].mean())





 这篇博客展示了如何使用Python的pandas库读取Excel数据,并通过matplotlib进行数据可视化。接着,运用sklearn的KMeans算法进行客户分群,创建了3个不同的客户群体。最后,对每个群体的平均收入进行了计算,并用不同颜色和形状的标记在散点图上展示分群结果,便于观察各群体特征。
这篇博客展示了如何使用Python的pandas库读取Excel数据,并通过matplotlib进行数据可视化。接着,运用sklearn的KMeans算法进行客户分群,创建了3个不同的客户群体。最后,对每个群体的平均收入进行了计算,并用不同颜色和形状的标记在散点图上展示分群结果,便于观察各群体特征。

















 406
406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









