






1.网络剪枝:网络中的很多参数没有用到。训练出一个大模型—>评估神经元或者权重的重要性—>移除—>将新网络放到原来的数据上fine-tuning(一次减掉太多会有损害,进行迭代删除)
为什么不直接训练一个小模型:大模型比较容易优化。
对权重进行剪枝,网络变得不规则,权重被剪掉的部分补0。对神经元进行剪枝,将神经元和它前后连接的权重都去掉。在实践过程中我们可以感受到大的网络比小的网络更容易训练,而且也有越来越多的实验证明大的网络比小的网络更容易收敛到全局最优点而不会遇到局部最优点和鞍点的问题。
2.知识蒸馏:先训练一个大模型,再训练一个小模型去学习大模型。
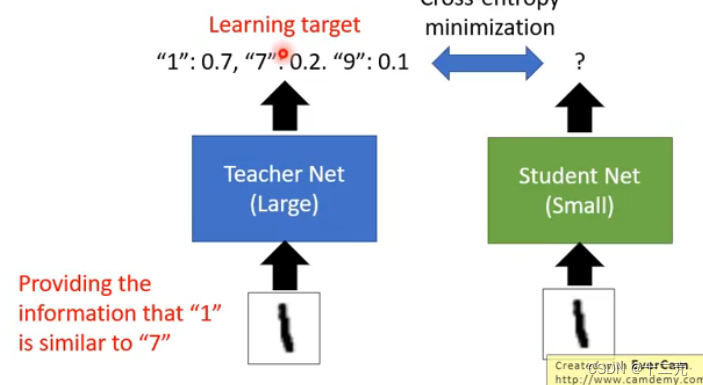
student原本学习只能学习到label告诉它这个图片是1,但是和teacher net学习的时候,会告诉他这个图片是1的概率是0.7,是7的概率是0.2,是9的概率是0.1。
调整最终输出的sofmax层来避免Teacher Network输出类似独热编码的标签:
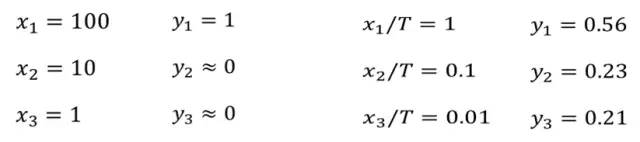
3.参数量化
(1)用更少的bits来表示一个参数
(2)权重聚类
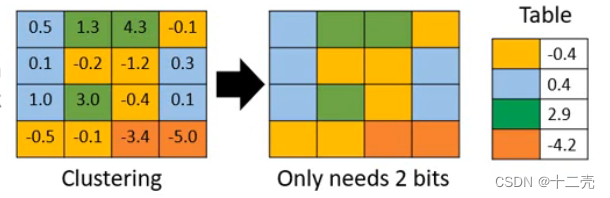
(3)常出现的用较少的bits代表,不常见的用较多的bits代表(霍夫曼编码)
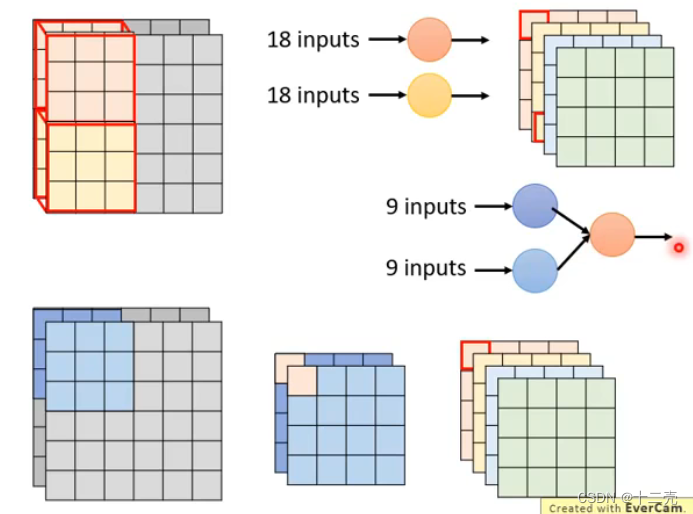
4.架构设计
对于前馈网络来说我们可以尝试在两层之间添加一个神经元较少的层来达到减少参数的目的,比如在下图中我们在节点数为M和N的两层之间添加一个节点数为K的层,K比起M和N一般较小,则参数量由M×N变为K×(M+N):
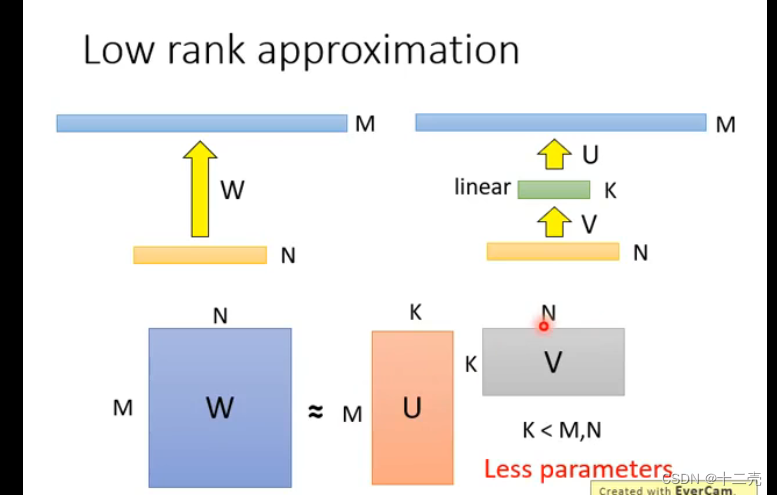
原来vs现在 采用中间一层减少参数
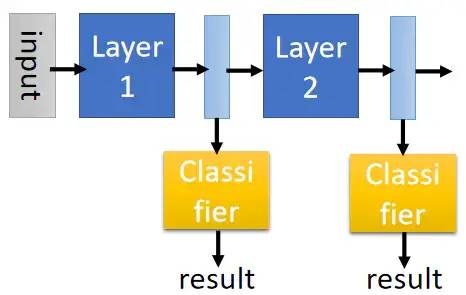
5.动态计算
希望可以动态地调整需要的计算资源,训练多个不同规模的模型,但是这样消耗大量的存储空间。提出intermedia layer方法,在浅层(中间层)直接输出结果。损失一定的准确率但是消耗的空间少。

















 1625
1625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









