







 本文介绍了无监督学习中的聚类算法,特别是K-均值算法。聚类算法在市场分割、社交网络分析和计算机管理等领域有广泛应用。K-均值是一个迭代过程,通过选择初始聚类中心,计算每个数据点的归属,更新聚类中心,直到中心点不再变化。文章还讨论了优化目标、随机初始化的影响以及选择聚类数的方法——肘部法则。
本文介绍了无监督学习中的聚类算法,特别是K-均值算法。聚类算法在市场分割、社交网络分析和计算机管理等领域有广泛应用。K-均值是一个迭代过程,通过选择初始聚类中心,计算每个数据点的归属,更新聚类中心,直到中心点不再变化。文章还讨论了优化目标、随机初始化的影响以及选择聚类数的方法——肘部法则。
一、无监督学习
1.1 无监督学习介绍
监督学习:有一个有标签的训练集,目标是找到能够区分正样本和负样本的决策边界要据此拟合一个假设函数。
非监督学习:数据没有附带任何标签。在非监督学习中,需要将一系列无标签的训练数据,输入到一个算法中,让算法帮助寻找数据的内在结构
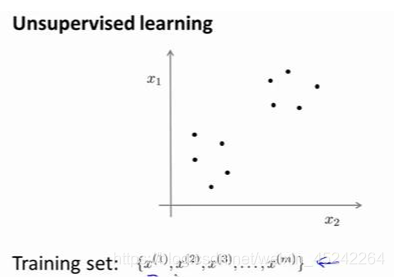
如图可以分为两个分开的点集(簇),一个能够找出这些点集的算法,称为聚类算法
1.2 聚类算法的作用
1.市场分割:数据库中存储了许多客户信息,希望将他们分成不同的客户群,对不同类型的客户分别销售产品,提供更适合的服务。
2.社交网络分析:关注一群人,关注社交网络,比如你经常和哪些人联系,这些人又经常给哪些人发邮件,由此找到关系密切的人群。
3.计算机管理:用聚类算法组织计算机集群,管理数据中心。知道哪些计算机经常协作工作,就可以重新分配资源,布局网络,优化数据中心和数据通信。
二、K-均值算法
2.1 算法介绍
K-均值是最普及的聚类算法。
算法接受一个未标记的数据集,然后将数据聚类成不同的组。
K-均值是一个迭代算法,假设想将数据聚类
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









