







本篇内容以知识整理为主,会结合萨特吉-萨尼的数据结构书籍和网络上的一些知识整理做一下总结,语言使用c++,有问题请及时指正,欢迎交流。
1、字典
1、字典定义
字典是一些元素的集合,每个元素有一个称作key的域,不同元素的key各不相同。满足以下特征:
- 字典是非线性结构容器
- key-value键值对的数据集合
- 可变的,无须的,key不重复
- key值必须可hash
2、字典常见操作
set(key,value):向字典中添加新元素。
remove(key):通过使用键值来从字典中移除键值对应的数据值。
has(key):如果某个键值存在于这个字典中,则返回true,反之则返回false。
get(key):通过键值查找特定的数值并返回。
clear():将这个字典中的所有元素全部删除。
size():返回字典所包含元素的数量。与数组的length属性类似。
keys():将字典所包含的所有键名以数组形式返回。
values():将字典所包含的所有数值以数组形式返回。
2、跳表
1、什么是i级链元素
背景:在一个使用有序链表描述的具有n 个元素的字典中进行搜索,至多需进行n 次比较。如果在链中部节点加一个指针,则比较次数可以减少到n/2+1。搜索时,首先将欲搜索元素与中间元素进行比较。如果欲搜索的元素较小,则仅需搜索链表的左半部分,否则,只要在链表右半部分进行比较即可。
进阶:通常0级链包括n个元素,1级链包括n/2个元素,2级链包括n/4个元素,i级链包括 n/2i 个元素。
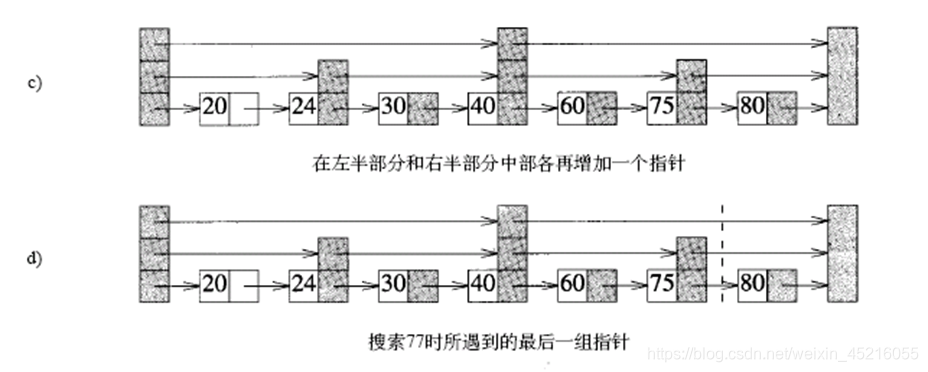 定义:当且仅当一个元素在0~i 级链上,但不在i+1级(若该链存在)链上时,称该元素是i 级链元素。
定义:当且仅当一个元素在0~i 级链上,但不在i+1级(若该链存在)链上时,称该元素是i 级链元素。
 40是2级链上唯一的元素,24、75是1级链元素。20、30、60、80是0级链元素。
40是2级链上唯一的元素,24、75是1级链元素。20、30、60、80是0级链元素。
2、什么是跳表
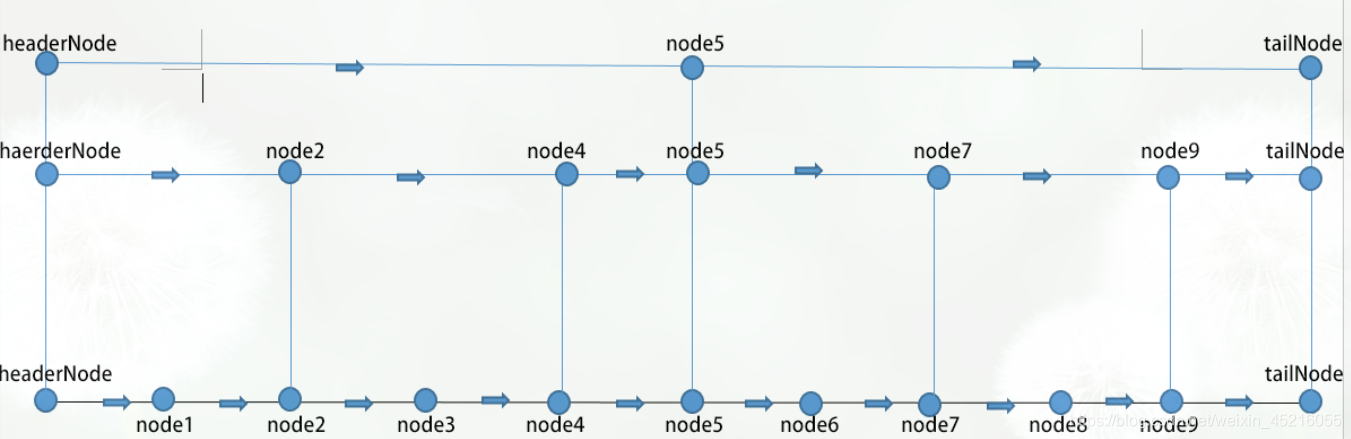
跳表是一个包含n个元素的单链表,且满足以下条件:
(1)在单链表的结点中,每隔2i个元素,就增加一个i级指针,0≤i≤⌈log2n⌉;
(2)其头节点为Head,是一个大小为⌈log2n⌉的一维指针数组,里面只存放指向i级的第一个级指针,0≤i≤⌈log2n⌉,不存放实际数据元素,它和同i级的指针构成一个存放指针的i级单链表;
(3)其尾结点为Tail,是一个可以存放实际数据元素的指针,通常该元素值设为一个较大的数值,作为查找退出的哨兵。
3、跳表的实现
template<class K, class E>
pair<const K, E> *skipNode<K, E>::find(const K& theKey)
{
skipNode<K, E>* beforeNode = headerNode;
for(int i = curLevels; i >= 0; --i) //降级
{
while(beforeNode->next[i]->element.first < theKey)
beforeNode = beforeNode->next[i]; //跳转到同一级的下一个
}
//跳出存在两种可能
//1.找到了,此时 if(beforeNode->next[0]->element.first == theKey)
//2.没找到,此时 if(beforeNode->next[0]->element.first > theKey)
if(beforeNode->next[0]->element.first == theElement.first)
return &beforeNode->next[0]->element;
return NULL;
}
3、散列表(Hash table)
1、散列表定义
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
散列函数:一种可以在元素关键字的值和该元素的存储位置之间建立映射的函数,即Loc=HF(Key)。
散列表:是一段连续的内存空间,考虑是连续的有限内存空间,使用顺序存储结构来实现
哈希冲突:不同关键字经过散列函数映射到相同地址的现象,关键字称为同义词。
2、散列函数创建方法
1、直接定址法
2、平方取中法
3、除留余数法
思想:f(k) = k % D
其中k为关键字,D是散列表的大小(即位置数),%为求模操作符。
散列表中的位置号从0到D-1,每一个位置称为桶(bucket)。
f(k)是存储关键字为k的元素的起始桶(home bucket)。在良性情况下,起始桶中所存储的元素即是关键字为K的元素。
 散列表ht,桶号从0到10。表中有3个元素,除数D为11。因为80%11=3,则80的位置为3,40%11=7,65%11=10。每个元素都在相应的桶中。散列表中余下的桶为空。
散列表ht,桶号从0到10。表中有3个元素,除数D为11。因为80%11=3,则80的位置为3,40%11=7,65%11=10。每个元素都在相应的桶中。散列表中余下的桶为空。

















 660
660

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









