







人工智能技术: 机器学习之决策树大作业
以西瓜集 2.0 为建模数据,采用交叉验证方法进行数据训练集和验证集的划分,实现决策树 “预剪枝”算法,要求:尽可能充分利用有限的西瓜集 2.0 数据所提供信息,建立泛化能力强的 决策树模型。(2)提交报告内包含交叉验证部分和决策树建模部分核心程序截图;(3) 对建 模结果要有分析部分。
理论定义
优秀的决策树:
优秀的决策树不仅对数据具有良好的拟合效果,而且对未知的数据具有良好的泛化能力,优秀的决策树具有以下优点:1.深度小;2.叶节点少;3深度小并且叶节点少.
剪枝的目的:处理决策树的过拟合问题。
预剪枝:生成过程中,对每个结点划分前进行估计,若当前结点的划分不能提升 [泛化能力] ,则停止划分,记当前结点为叶结点。
预剪枝的方法:
限定决策树的深度;设定一个阈值;设置某个指标,比较节点划分前后的泛化能力
交叉验证:
如果给定样本数据充足,进行模型选择的一种简单方法是随机地将数据集切分为3部分,分为训练集、验证集和测试集。
简单交叉验证:随机将数据划分为两部分,训练集和测试集。
数据处理
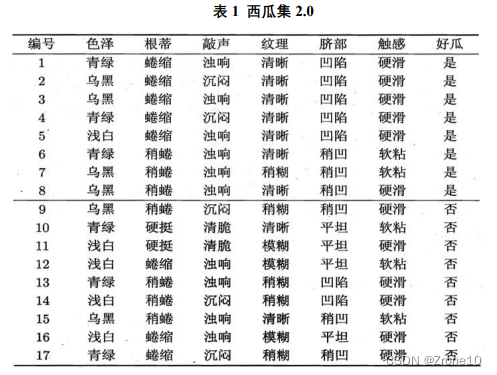
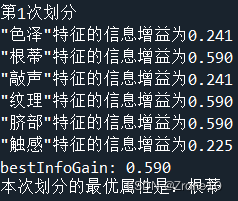
整个西瓜集2.0使用ID3算法生成的决策树:
简单交叉验证:随机将数据划分为两部分,训练集和测试集,各50%。
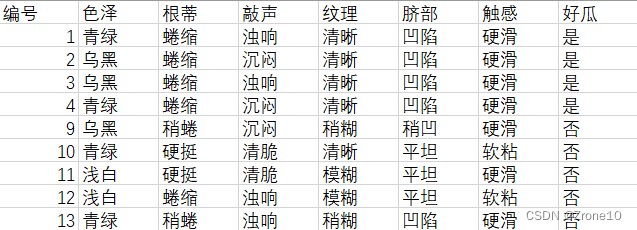
训练集
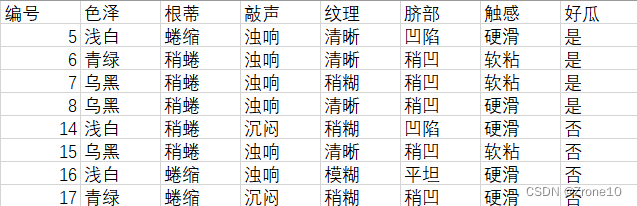
测试集
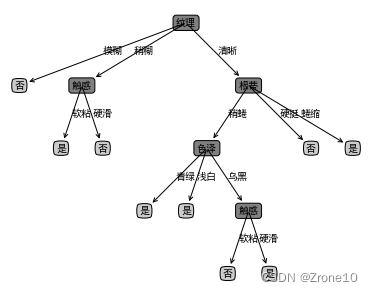
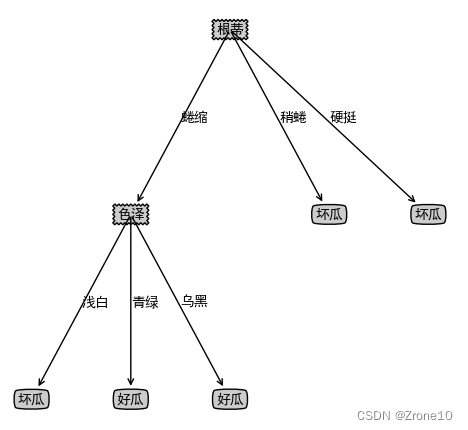
训练集ID3算法生成的决策树:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









