







 本文详细介绍了Hadoop集群的启动与配置过程,包括使用start-dfs.sh脚本启动集群,通过web端监控HDFS状态,以及如何将MapReduce程序打包成jar并在集群上运行,涉及数据上传、jar包上传及结果查看等关键步骤。
本文详细介绍了Hadoop集群的启动与配置过程,包括使用start-dfs.sh脚本启动集群,通过web端监控HDFS状态,以及如何将MapReduce程序打包成jar并在集群上运行,涉及数据上传、jar包上传及结果查看等关键步骤。
1、启动已经搭建好的hdfs集群:start-dfs.sh
2、打开web端http://www.fxb1:50070/
3、将事先写好的mapreducer打成jar包
代码部分
Mapper部分
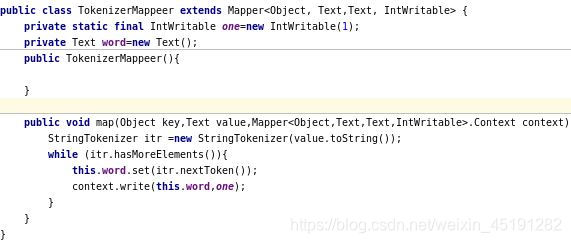
reducer部分
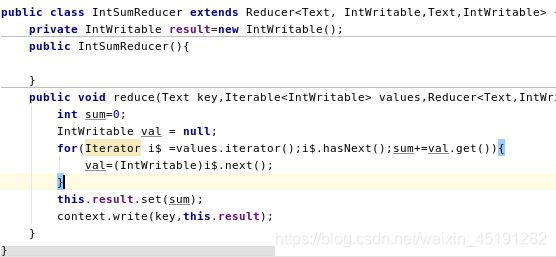
main主类
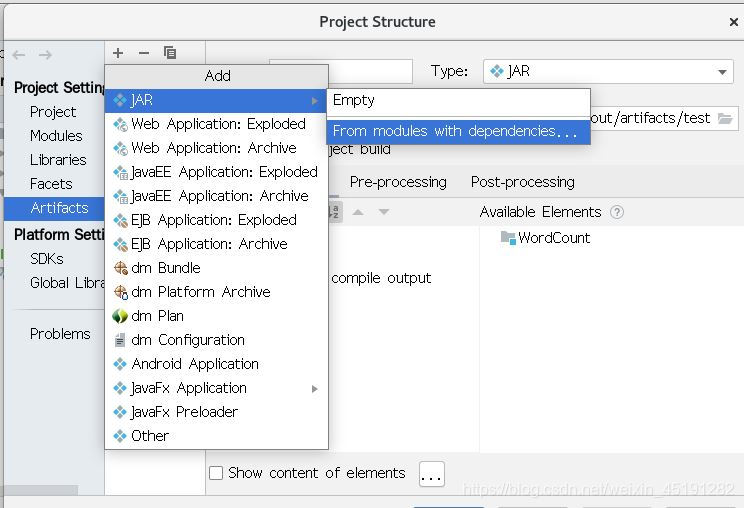
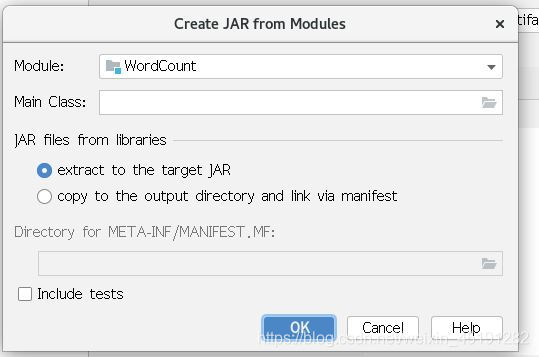
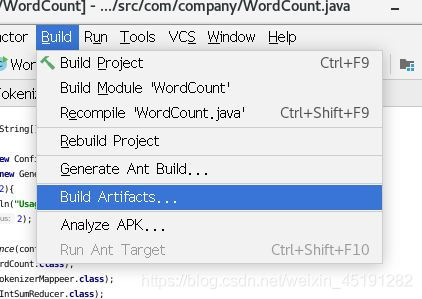
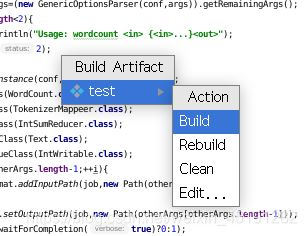
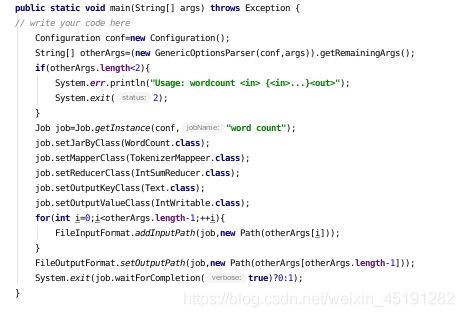 4、打jar包
4、打jar包

5、上传到集群运行
(1)上传要处理的数据a.txt b.txt
hadoop fs -put a.txt /user/fxb1/input/
hadoop fs -put b.txt /user/fxb1/input/
(2)上传jar包
hadoop jar test.jar input output(input–>未处理数据存放位置,output处理后数据存放位置)
(3)查看结果(略)

















01-01
 1万+
1万+
1万+
05-05
194
194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









