







 本文详细介绍了Apache Spark中Key-Value类型RDD的主要操作,包括reduceByKey、groupByKey、combineByKey、aggregateByKey等,并通过实例展示了这些操作的具体应用。
本文详细介绍了Apache Spark中Key-Value类型RDD的主要操作,包括reduceByKey、groupByKey、combineByKey、aggregateByKey等,并通过实例展示了这些操作的具体应用。
文章目录
Key-Value类型
reduceByKey()按照K聚合V
1)函数签名:
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
2)功能说明:该操作可以将RDD[K,V]中的元素按照相同的K对V进行聚合。其存在多种重载形式,还可以设置新RDD的分区数。
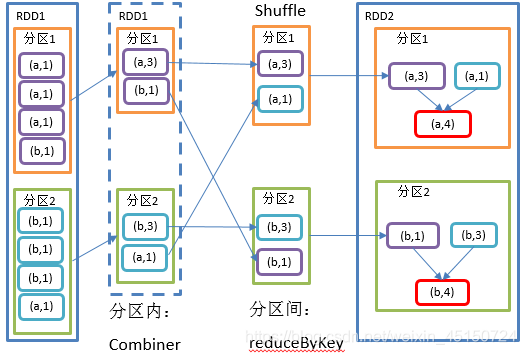
3)需求说明:统计单词出现次数
可以发现在分区内就进行了聚合操作。然后分区间进行分组,就是会进行一个shuffle,然后再进行对应的累加。
object KeyValue02_reduceByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd = sc.makeRDD(List(("a",1),("b",5),("a",5),("b",2)))
//3.2 计算相同key对应值的相加结果
val reduce: RDD[(String, Int)] = rdd.reduceByKey((v1,v2) => v1+v2)
//3.3 打印结果
reduce.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
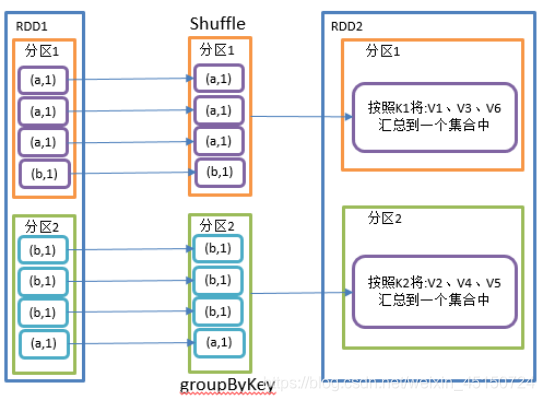
groupByKey()按照K重新分组
功能说明
groupByKey对每个key进行操作,但只生成一个seq,并不进行聚合,也就是直接进行shuffle。
该操作可以指定分区器或者分区数(默认使用HashPartitioner)
object KeyValue03_groupByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd = sc.makeRDD(List(("a",1),("b",5),("a",5),("b",2)))
//3.2 将相同key对应值聚合到一个Seq中
val group: RDD[(String, Iterable[Int])] = rdd.groupByKey()
//3.3 打印结果
group.collect().foreach(println)
//3.4 计算相同key对应值的相加结果
group.map(t=>(t._1,t._2.sum)).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
combineByKey()
1)函数签名:
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)]
(1)createCombiner(转换数据的结构): combineByKey() 会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键相同。如果这是一个新的元素,combineByKey()会使用一个叫作createCombiner()的函数来创建那个键对应的累加器的初始值。
(2)mergeValue(分区内): 如果这是一个在处理当前分区之前已经遇到的键,它会使用mergeValue()方法将该键的累加器对应的当前值与这个新的值进行合并。
(3)mergeCombiners(分区间): 由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器,就需要使用用户提供的mergeCombiners()方法将各个分区的结果进行合并。
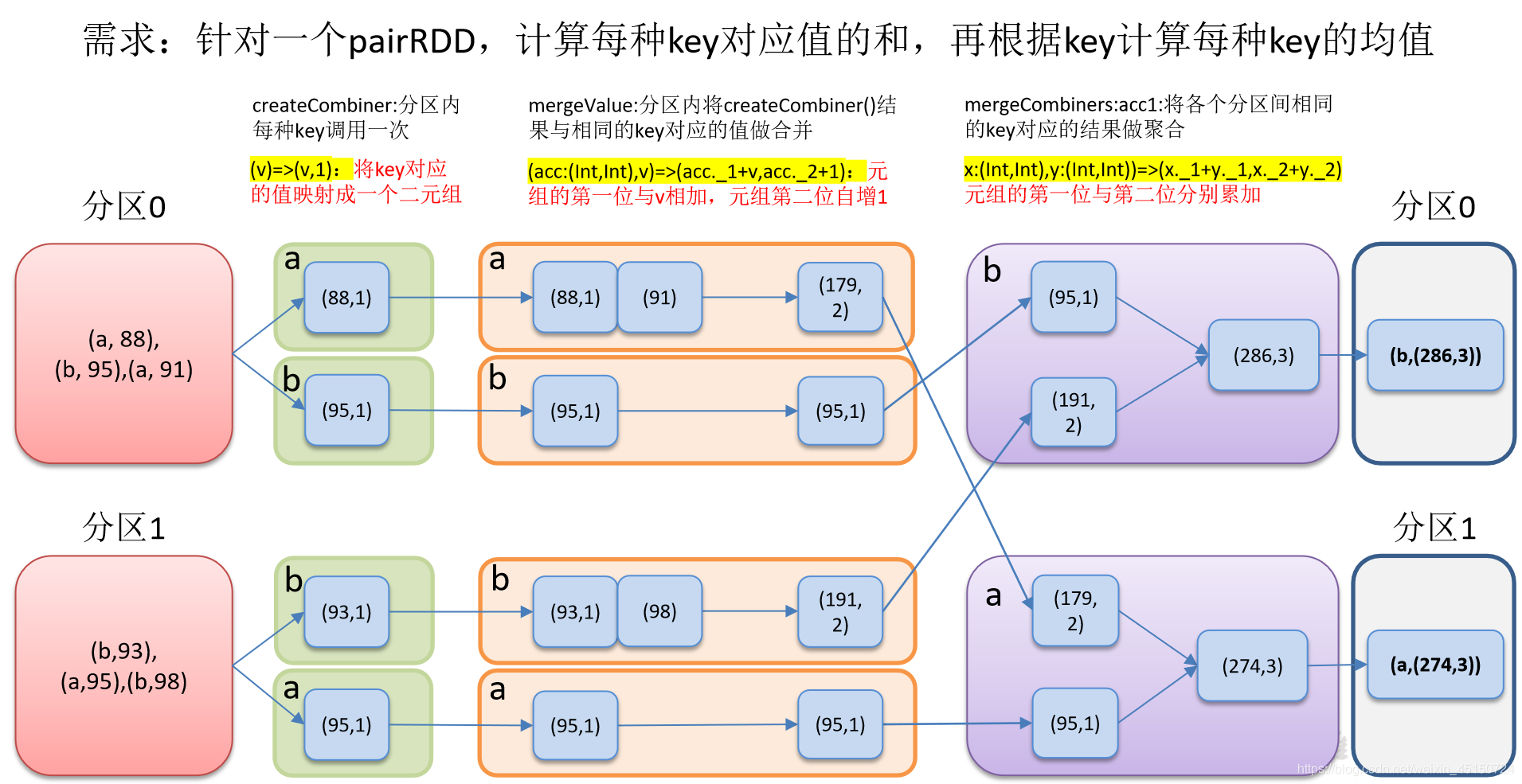
需求: 创建一个pairRDD,根据key计算每种key的均值。(先计算每个key出现的次数以及可以对应值的总和,再相除得到结果)
每个分区内
也就是,每个key值对应的累加器的初始值。初始值什么意思?就是每个分区第一次执行这个key,就是只执行一次。(一个分区中的一个key,初始化一次)
(acc: (Int, Int), v) => (acc._1 + v,acc._2 + 1)
第一个acc是之前累加过的,(累加的值,累加的个数);
v是同一个key的值,因为是一个一个的累加,直接acc中对应的值加上v这个值。因为个数是1,所以直接用acc累加的个数加上1,就是累加过后的数目。
不同分区间
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2)
表示的是每个分区的数据进行相加,也就是不同的分区之间的同一个key的数据进行相加。值进行相加,次数进行相加。
代码实现
object KeyValue06_combineByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3.1 创建第一个RDD
val list: List[(String, Int)] = List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98))
val input: RDD[(String, Int)] = sc.makeRDD(list, 2)
//3.2 将相同key对应的值相加,同时记录该key出现的次数,放入一个二元组
val combineRdd: RDD[(String, (Int, Int))] = input.combineByKey(
(_, 1), //就是(值,1),每个分区某个key对应的初始值,这里就是转换结构的关键。
(acc: (Int, Int), v) => (acc._1 + v,acc._2 + 1),
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2)
)
//3.3 打印合并后的结果
combineRdd.collect().foreach(println)
//3.4 计算平均值
combineRdd.map {
case (key, value) => {
(key, value._1 / value._2.toDouble)
}
}.collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
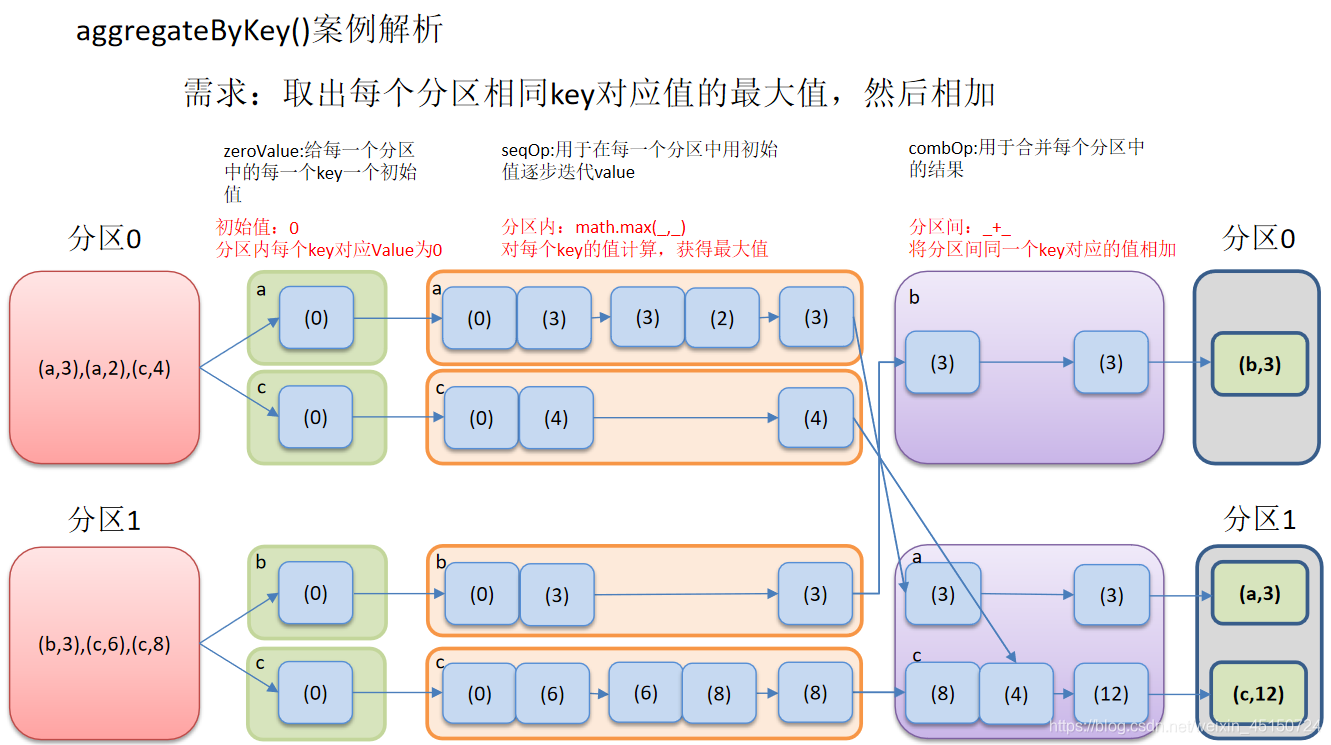
aggregateByKey()按照K处理分区内和分区间逻辑
需求:每个分区中的最大值进行累加。

object KeyValue04_aggregateByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(String, Int)] = sc.makeRDD(List(("a", 3), ("a", 2), ("c", 4), ("b", 3), ("c", 6), ("c", 8)), 2)
//3.2 取出每个分区相同key对应值的最大值,然后相加
//这里的0是初始值。
rdd.aggregateByKey(0)(math.max(_, _), _ + _).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
foldByKey()分区内和分区间相同的aggregateByKey()
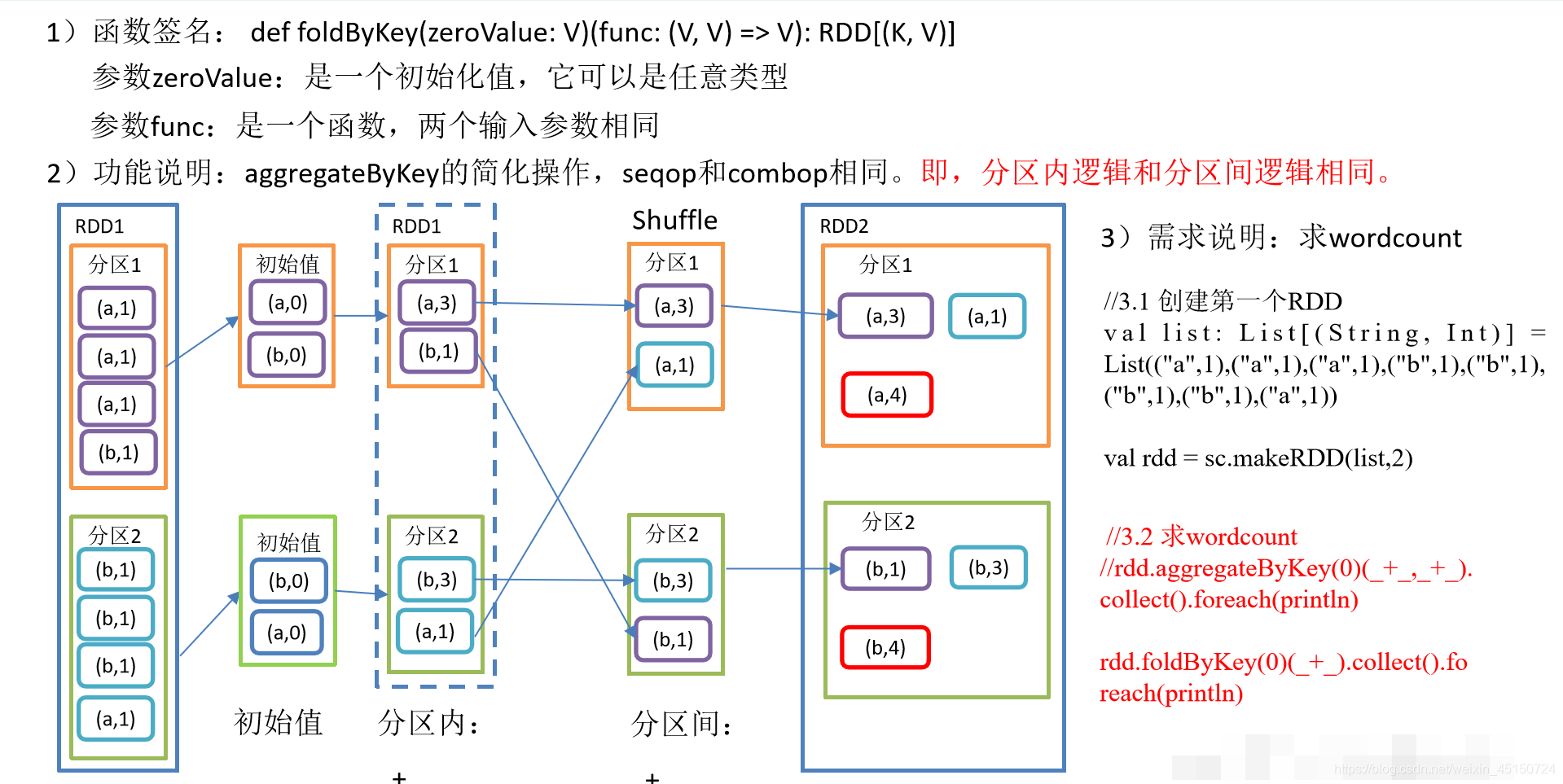
object KeyValue05_foldByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val list: List[(String, Int)] = List(("a",1),("a",1),("a",1),("b",1),("b",1),("b",1),("b",1),("a",1))
val rdd = sc.makeRDD(list,2)
//3.2 求wordcount
//rdd.aggregateByKey(0)(_+_,_+_).collect().foreach(println)
//因为分区间和分区内的逻辑相同,所以只有一个位置即可。
rdd.foldByKey(0)(_+_).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
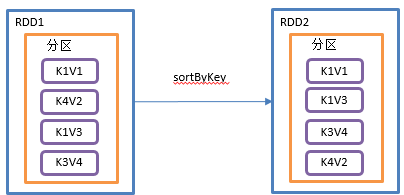
sortByKey()按照K进行排序
1)函数签名:
def sortByKey(
ascending: Boolean = true, // 默认,升序
numPartitions: Int = self.partitions.length) : RDD[(K, V)]
2)功能说明
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
3)需求说明:创建一个pairRDD,按照key的正序和倒序进行排序。
object KeyValue07_sortByKey {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
//3.2 按照key的正序(默认顺序)
rdd.sortByKey(true).collect().foreach(println)
//3.3 按照key的倒序
rdd.sortByKey(false).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
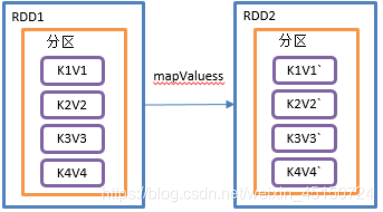
mapValues()只对V进行操作
1)函数签名:def mapValues[U](f: V => U): RDD[(K, U)]
2)功能说明:针对于(K,V)形式的类型只对V进行操作
3)需求说明:创建一个pairRDD,并将value添加字符串"|||"
object KeyValue08_mapValues {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (1, "d"), (2, "b"), (3, "c")))
//3.2 对value添加字符串"|||"
rdd.mapValues(_ + "|||").collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
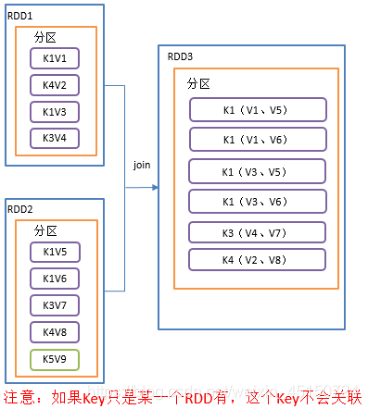
join()连接
1)函数签名:
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, W))]
2)功能说明
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD
3)需求说明:创建两个pairRDD,并将key相同的数据聚合到一个元组。
从这个图中可以看出,分区1中key1有v1,v2。分区2中key1有v5,v6。显然在key1的这种情况下,有4中组合。
object KeyValue09_join {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c")))
//3.2 创建第二个pairRDD
val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1, 4), (2, 5), (4, 6)))
//3.3 join操作并打印结果
rdd.join(rdd1).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
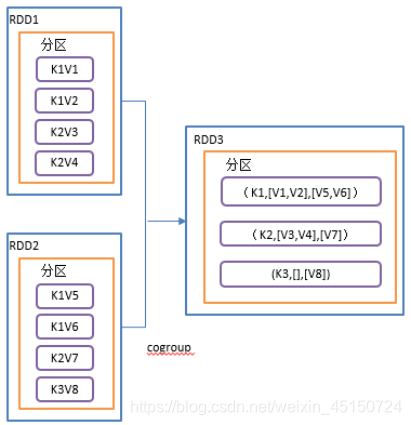
cogroup()类似全连接,但是在同一个RDD中对key聚合
1)函数签名:def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]
2)功能说明
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable,Iterable))类型的RDD
操作两个RDD中的KV元素,每个RDD中相同key中的元素分别聚合成一个集合。
3)需求说明:创建两个pairRDD,并将key相同的数据聚合到一个迭代器。
类似于join那种full join,没有join上的写null。这不过这里啥也没有。
object KeyValue10_cogroup {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并设置App名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//3具体业务逻辑
//3.1 创建第一个RDD
val rdd: RDD[(Int, String)] = sc.makeRDD(Array((1,"a"),(2,"b"),(3,"c")))
//3.2 创建第二个RDD
val rdd1: RDD[(Int, Int)] = sc.makeRDD(Array((1,4),(2,5),(4,6)))
//3.3 cogroup两个RDD并打印结果
// (1,(CompactBuffer(a),CompactBuffer(4)))
// (2,(CompactBuffer(b),CompactBuffer(5)))
// (3,(CompactBuffer(c),CompactBuffer()))
// (4,(CompactBuffer(),CompactBuffer(6)))
rdd.cogroup(rdd1).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}

















 545
545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









