






 本文详细介绍了Spark中的各种算子,包括parallelize、map、flatMap、groupBy、filter、distinct、subtract、sample、takeSample、cache、persist、mapValues、combineByKey、reduceByKey、partitionBy、cogroup、join、leftOuterJoin、Action算子(如collect、foreach、saveAsTextFile)等。通过实例展示了这些算子的使用方法和应用场景,帮助读者深入理解Spark的计算模型和数据处理过程。
本文详细介绍了Spark中的各种算子,包括parallelize、map、flatMap、groupBy、filter、distinct、subtract、sample、takeSample、cache、persist、mapValues、combineByKey、reduceByKey、partitionBy、cogroup、join、leftOuterJoin、Action算子(如collect、foreach、saveAsTextFile)等。通过实例展示了这些算子的使用方法和应用场景,帮助读者深入理解Spark的计算模型和数据处理过程。
1.parallelize
1.解释
- 并行集合的创建(RDD)
使用已经存在的迭代器或者集合通过调用spark驱动程序提供的parallelize函数来创建并行集合
- 并行集合被创建用来在分布式集群上并行计算的。
2.例子
data = [1, 2, 3, 4, 5]
distData = sc.parallelize(data)
一旦创建RDD,RDD,就可以在集群上并行的去被操作。我们可以调用distData.reduce(lambda a, b:a + b)添加元素到list。之后在RDD上进行一些操作或者行动.
3.parallelize的一个重要的参数
就是分区数量。就是将RDD切分多少个分区。这个分区数目每个CPU一般是2-4个在你的集群上。通常,spark会自动设置这个数量在你的集群上。你也可以手动去传参,这个函数的第二个参数,比如`sc.parallelize(data, 5)。
map和mappartition算子
map算子
val a = sc.parallelize(1 to 20, 2)
def mapTerFunc(a : Int) : Int = {a*3}
val mapResult = a.map(mapTerFunc)
//val mapResult = a.map(a => {
// a*3
// })
println(mapResult.collect().mkString(","))
//案例2
val a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
val b = a.map(_.length)
val c = a.zip(b)
print(c.collect().mkString(""))
//方法2
val a = sc.parallelize(List("dog","salmon","salmon","rat","elephant"),3)
//val b = a.map(_.length)
//val c = a.zip(b)
//val c = a.zip(a.map(_.length))
//val mapFunc()
def mapFunc(a:String) : Int = {a.length()}
val res = a.zip(a.map(mapFunc))
println(res.collect().mkString(""))
}
}mappartition算子
//mappartitions低效用法
//大家通常的做法都是申请一个迭代器buffer,将处理后的数据加入迭代器buffer,然后返回迭代器。如下面的demo。
val a = sc.parallelize(1 to 20, 2)
def terFunc(iter: Iterator[Int]) : Iterator[Int] = {
var res = List[Int]()
while (iter.hasNext) {
val cur = iter.next;
res.::= (cur*3) ;
}
res.iterator
}
val result = a.mapPartitions(terFunc)
println(result.collect().mkString(","))
//res:30,27,24,21,18,15,12,9,6,3,60,57,54,51,48,45,42,39,36,33
/*
mappartitions高效用法
注意,上面的例子,会在mappartition执行期间,在内存中定义一个数组并且将缓存所有的数据。假如数据集比较大,内存不足,会导致内存溢出,任务失败。 对于这样的案例,Spark的RDD不支持像mapreduce那些有上下文的写方法。其实,有个方法是无需缓存数据的,那就是自定义一个迭代器类。如下例:
*/
val a = sc.parallelize(1 to 20, 5)
class CustomIterator(iter: Iterator[Int]) extends Iterator[Int] {
def hasNext : Boolean = {iter.hasNext}
def next : Int= {val cur = iter.next
cur*3}
}
val result = a.mapPartitions(v => new CustomIterator(v))
println(result.collect().mkString(","))
flatMap算子
val arr=sc.parallelize(Array(("A",1),("B",2),("C",3)))
arr.flatMap(x=>(x._1+x._2)).foreach(println)
arr.map(x=>(x._1+x._2)).foreach(println)
/*
flatMap结果
A
1
B
2
C
3
map结果
A1
B2
C3
*/
val x = sc.parallelize(1 to 10, 3)
//随机生成1-8的整数n,然后有n个【1,10】
x.flatMap(List.fill(scala.util.Random.nextInt(8))(_)).collect
/*
结果:
res1: Array[Int] = Array(1, 2, 3, 3, 3, 4, 4, 4, 4, 4, 4, 4, 4, 4, 5, 5, 6, 6, 6, 6, 6, 6, 6, 6, 7, 7, 7, 8, 8, 8, 8, 8, 8, 8, 8, 9, 9, 9, 9, 9, 10, 10, 10, 10, 10, 10, 10, 10)
实际使用场景
这个场景是我曾经在写代码过程中遇到的难题,在字符串中如何统计相邻字符对出现的次数。意思就是如果有A;B;C;D;B;C字符串,则(A,B),(C,D),(D,B)相邻字符对出现一次,(B,C)出现两次。
如有数据spark中flatMap函数用法--spark学习(基础)
A;B;C;D;B;D;C B;D;A;E;D;C A;B
统计相邻字符对出现次数代码如下
data.map(_.split(";")).flatMap(x=>{
for(i<-0 until x.length-1)
yield (x(i)+","+x(i+1),1)
}).reduceByKey(_+_).foreach(println)
/*
输出结果为:
(A,E,1)
(E,D,1)
(D,A,1)
(C,D,1)
(B,C,1)
(B,D,2)
(D,C,2)
(D,B,1)
(A,B,2)
*/glom
/* 官方文档: glom() Return an RDD created by coalescing all elements within each partition into a list. >>> rdd = sc.parallelize([1, 2, 3, 4], 2) >>> sorted(rdd.glom().collect()) [[1, 2], [3, 4]] 把rdd中的每个片段映射为一个列表 rdd = sc.parallelize([1, 2, 3, 4], 2) //rdd.collect()结果为[1,2,3,4] 说明rdd中的元素认为数字 //rdd.glom.collect()结果为[[1,2],[3,4]] 说明rdd中的元素已经变成了分片映射的列表 val a = sc.parallelize(1 to 10, 3) println(a.glom().collect.toString) res: Array[Array[Int]] = Array(Array(1, 2, 3), Array(4, 5, 6), Array(7, 8, 9, 10))
uion
使用 union 函数时需要保证两个 RDD1 与 RDD2 数据类型相同,返回的 RDD3 数据类型和 RDD1 与 RDD2 数据类型相同,并不去重,保存所有元素。如果想去重可以使用 distinct()。同时 Spark 还提供更为简洁的使用 union 的 API,通过 ++ 符号相当于 union 函数操作。
左侧大方框代表两个 RDD,大方框内的小方框代表 RDD 分区。右侧大方框代表合并后的 RDD,大方框内的小方框代表分区。
含有V1、V2、U1、U2、U3、U4的RDD和含有V1、V8、U5、U6、U7、U8的RDD合并所有元素形成一个RDD。V1、V1、V2、V8形成一个分区,U1、U2、U3、U4、U5、U6、U7、U8形成一个分区。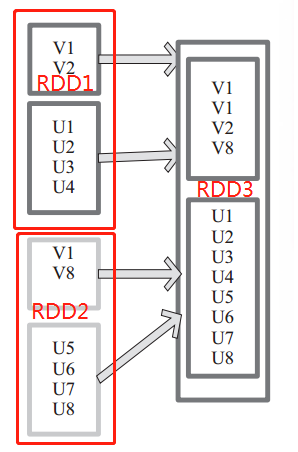
//代码
val a = sc.parallelize(1 to 2, 1)
val b = sc.parallelize(6 to 7, 1)
println((a ++ b).collect.mkString(","))
//res:1,2,6,7
cartesian(笛卡尔操作)
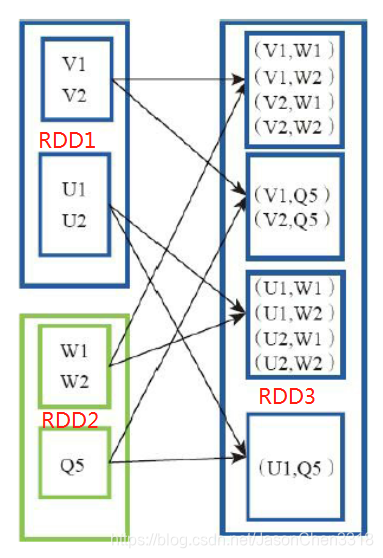
对 RDD1 和 RDD2 内 的 元 素 进 行 笛 卡 尔 积 操 作。 操 作 后, 内 部 实 现 返 回CartesianRDD。该操作不会执行shuffle操作。
例 如: V1 和 另 一 个 RDD 中 的 W1、 W2、 Q5 进 行 笛 卡 尔 积 运 算 形 成 (V1,W1)、(V1,W2)、 (V1,Q5)。
//代码
val x = sc.parallelize(List(1,2,3,4,5))
val y = sc.parallelize(List(6,7,8,9,10))
print(x.cartesian(y).collect.mkString(","))
//res:(1,7),(1,8),(1,9),(2,7),(2,8),(2,9),(3,7),(3,8),(3,9)
groupBy
groupBy :将元素通过函数生成相应的 Key,数据就转化为 Key-Value 格式,之后将 Key 相同的元素分为一组。
函数实现如下:
1)将用户函数预处理:
val cleanF = sc.clean(f)
2)对数据 map 进行函数操作,最后再进行 groupByKey 分组操作。
this.map(t => (cleanF(t), t)).groupByKey(p)
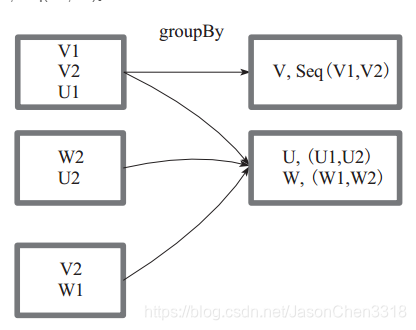
其中, p 确定了分区个数和分区函数,也就决定了并行化的程度。方框代表一个 RDD 分区,相同key 的元素合并到一个组。例如 V1 和 V2 合并为 V, Value 为 V1,V2。形成 V,Seq(V1,V2)。
在一个PairRDD或(k,v)RDD上调用,返回一个(k,Iterable<v>)。主要作用是将相同的所有的键值对分组到一个集合序列当中,其顺序是不确定的。groupByKey是把所有的键值对集合都加载到内存中存储计算,若一个键对应值太多,则易导致内存溢出。
思路:可以用之前求并集的union方法,将1,v2变为有相同键值的v,而后进行groupByKey
//代码
val a = sc.parallelize(1 to 9, 3)
println(a.groupBy(x => {
if (x % 2 == 0)
"even"
else
"odd" }).collect.mkString(","))
}
//res:(even,CompactBuffer(2, 4, 6, 8)),(odd,CompactBuffer(1, 3, 5, 7, 9))
filter
filter 函数功能是对元素进行过滤,对每个 元 素 应 用 f 函 数, 返 回 值 为 true 的 元 素 在RDD 中保留,返回值为 false 的元素将被过滤掉。 内 部 实 现 相 当 于 生 成 FilteredRDD(this,sc.clean(f))。
下面代码为函数的本质实现:
deffilter(f:T=>Boolean):RDD[T]=newFilteredRDD(this,sc.clean(f))
图中每个方框代表一个 RDD 分区, T 可以是任意的类型。通过用户自定义的过滤函数 f,对每个数据项操作,将满足条件、返回结果为 true 的数据项保留。例如,过滤掉 V2 和 V3 保留了 V1,为区分命名为 V’1。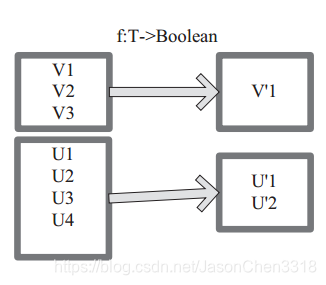
//代码
val a = sc.parallelize(1 to 10, 3)
val b = a.filter(_ % 2 == 0)
println(b.collect.mkString(","))
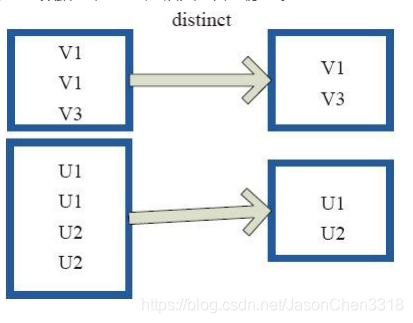
//res:2,4,6,8,10distinct(去重)
distinct将RDD中的元素进行去重操作。图9中的每个方框代表一个RDD分区,通过distinct函数,将数据去重。 例如,重复数据V1、 V1去重后只保留一份V1。
返回一个源数据集去重之后的新数据集,即去重,并局部无序而整体有序返回。(详细介绍见Spark distinct中numTasks含义)
//代码
val c = sc.parallelize(List("Gnu", "Dog", "Gnu"), 2)
println(c.distinct.collect.mkString(","))
//res:Dog,Gnu
subtract
subtract相当于进行集合的差操作,RDD 1去除RDD 1和RDD 2交集中的所有元素。 V1在两个RDD中均有,根据差集运算规则,新RDD不保留,V2在第一个RDD有,第二个RDD没有,则在新RDD元素中包含V2。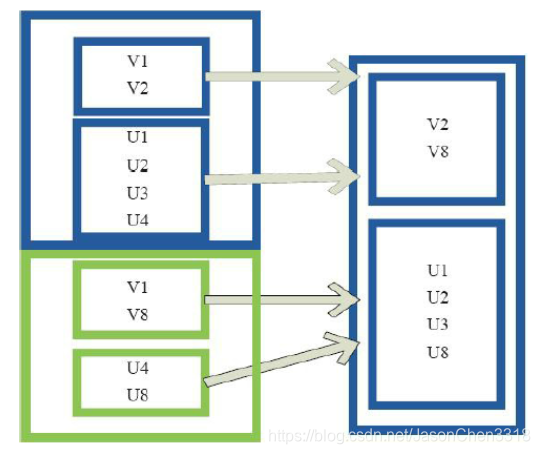
//代码
val a = sc.parallelize(1 to 3, 3)
val b = sc.parallelize(3 to 5, 3)
val c = a.subtract(b)
println(c.collect.mkString(","))
//res:1,2===>以第一个RDD为准,RDD1中没有的元素新的RDD中也没有sample
sample(withReplacement : scala.Boolean, fraction : scala.Double,seed scala.Long)
sample算子时用来抽样用的,其有3个参数
withReplacement:表示抽出样本后是否在放回去,true表示会放回去,这也就意味着抽出的样本可能有重复
fraction :抽出多少,这是一个double类型的参数,0-1之间,eg:0.3表示抽出30%
seed:表示一个种子,根据这个seed随机抽取,一般情况下只用前两个参数就可以,那么这个参数是干嘛的呢,这个参数一般用于调试,有时候不知道是程序出问题还是数据出了问题,就可以将这个参数设置为定值
seed:作用???
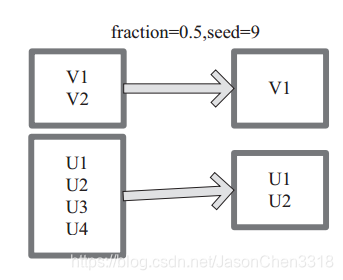
sample 将 RDD 这个集合内的元素进行采样,获取所有元素的子集。内部实现是生成 SampledRDD(withReplacement, fraction, seed)。
函数参数设置:
图 中 的 每 个 方 框 是 一 个 RDD 分 区。 通 过 sample 函 数, 采 样 50% 的 数 据。V1、 V2、 U1、 U2、U3、U4 采样出数据 V1 和 U1、 U2 形成新的 RDD。
//代码
val a = sc.parallelize(1 to 100, 3)
println(a.sample(false, 0.1, 10).collect.mkString(","))
//res:2,5,8,10,15,16,31,52,64,67,76,94takeSample
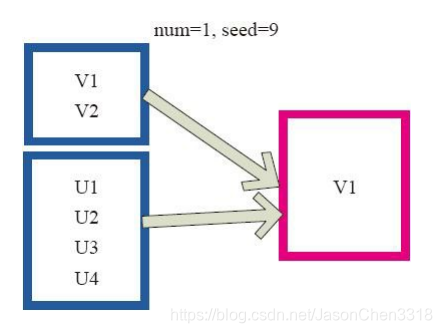
takeSample()函数和上面的sample函数是一个原理,但是不使用相对比例采样,而是按设定的采样个数进行采样,同时返回结果不再是RDD,而是相当于对采样后的数据进行Collect(),返回结果的集合为单机的数组。
图中左侧的方框代表分布式的各个节点上的分区,右侧方框代表单机上返回的结果数组。 通过takeSample对数据采样,设置为采样一份数据,返回结果为V1。
对于一个数据集进行随机抽样,返回一个包含num个随机抽样元素的数组,withReplacement表示是否有放回抽样,参数seed指定生成随机数的种子。
该方法仅在预期结果数组很小的情况下使用,因为所有数据都被加载到driver端的内存中。
//代码
val x = sc.parallelize(1 to 100, 3)
println(x.takeSample(true, 10, 1).mkString(","))
//res:77,94,13,80,78,91,12,60,71,49
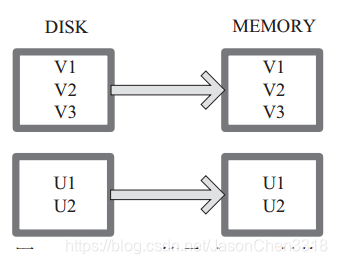
cache
cache 将 RDD 元素从磁盘缓存到内存。 相当于 persist(MEMORY_ONLY) 函数的功能。
图 中每个方框代表一个 RDD 分区,左侧相当于数据分区都存储在磁盘,通过 cache 算子将数据缓存在内存。
//代码
val c = sc.parallelize(List("Gnu", "Cat", "Rat", "Dog", "Gnu", "Rat"), 2)
println(c.getStorageLevel)
//res:StorageLevel(false, false, false, false, 1)
c.cache
println(c.getStorageLevel)
//res:StorageLevel(false, true, false, true, 1)persist
persist
persist 函数对 RDD 进行缓存操作。数据缓存在哪里依据 StorageLevel 这个枚举类型进行确定。 有以下几种类型的组合(见10), DISK 代表磁盘,MEMORY 代表内存, SER 代表数据是否进行序列化存储。
下面为函数定义, StorageLevel 是枚举类型,代表存储模式,用户可以通过图 14-1 按需进行选择。
persist(newLevel:StorageLevel)
图 14-1 中列出persist 函数可以进行缓存的模式。例如,MEMORY_AND_DISK_SER 代表数据可以存储在内存和磁盘,并且以序列化的方式存储,其他同理。
图 中方框代表 RDD 分区。 disk 代表存储在磁盘, mem 代表存储在内存。数据最初全部存储在磁盘,通过 persist(MEMORY_AND_DISK) 将数据缓存到内存,但是有的分区无法容纳在内存,将含有 V1、 V2、 V3 的RDD存储到磁盘,将含有U1,U2的RDD仍旧存储在内存。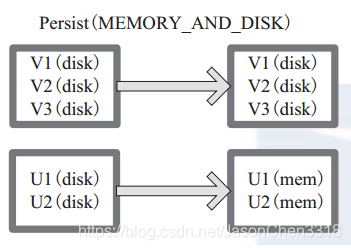
mapValues
mapValues :针对(Key, Value)型数据中的 Value 进行 Map 操作,而不对 Key 进行处理。
图 15 中的方框代表 RDD 分区。 a=>a+2 代表对 (V1,1) 这样的 Key Value 数据对,数据只对 Value 中的 1 进行加 2 操作,返回结果为 3。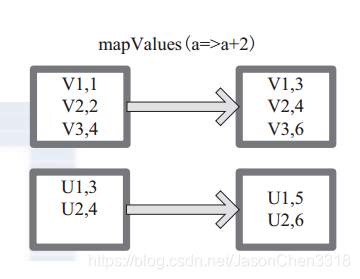
//代码
val a = sc.parallelize(List("dog", "lion", "cat", "dog"), 2)
val b = a.map(x => (x.length, x))
println(b.mapValues("x" + _ + "x").collect.mkString(","))
//res:(3,xdogx),(4,xlionx),(3,xcatx),(3,xdogx)combineByKey
下面代码为 combineByKey 函数的定义:
combineByKey[C](createCombiner:(V) C,
mergeValue:(C, V) C,
mergeCombiners:(C, C) C,
partitioner:Partitioner,
mapSideCombine:Boolean=true,
serializer:Serializer=null):RDD[(K,C)]
说明:
‰ createCombiner: V => C, C 不存在的情况下,比如通过 V 创建 seq C。
‰ mergeValue: (C, V) => C,当 C 已经存在的情况下,需要 merge,比如把 item V
加到 seq C 中,或者叠加。
mergeCombiners: (C, C) => C,合并两个 C。
‰ partitioner: Partitioner, Shuff le 时需要的 Partitioner。
‰ mapSideCombine : Boolean = true,为了减小传输量,很多 combine 可以在 map
端先做,比如叠加,可以先在一个 partition 中把所有相同的 key 的 value 叠加,
再 shuff le。
‰ serializerClass: String = null,传输需要序列化,用户可以自定义序列化类:
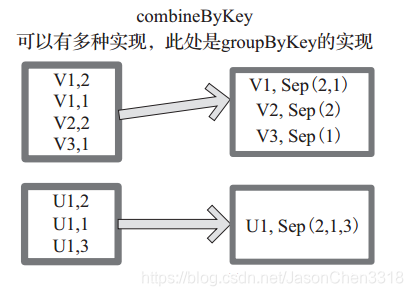
例如,相当于将元素为 (Int, Int) 的 RDD 转变为了 (Int, Seq[Int]) 类型元素的 RDD。图 中的方框代表 RDD 分区。如图,通过 combineByKey, 将 (V1,2), (V1,1)数据合并为( V1,Seq(2,1))。
//代码
val a = sc.parallelize(List("dog","cat","gnu","salmon","rabbit",
"turkey","wolf","bear","bee"), 3)
val b = sc.parallelize(List(1,1,2,2,2,1,2,2,2), 3)
val c = b.zip(a)
println(c.collect.mkString(","))
//res:(1,dog),(1,cat),(2,gnu),(2,salmon),(2,rabbit),(1,turkey),(2,wolf),(2,bear),(2,bee)
val d = c.combineByKey(List(_), (x:List[String], y:String) => y :: x, (x:List[String], y:List[String]) => x ::: y)
println(d.collect.mkString(","))
//res:(1,List(cat, dog, turkey)),(2,List(gnu, rabbit, salmon, bee, bear, wolf))reduceByKey
reduceByKey 是比 combineByKey 更简单的一种情况,只是两个值合并成一个值,( Int, Int V)to (Int, Int C),比如叠加。所以 createCombiner reduceBykey 很简单,就是直接返回 v,而 mergeValue和 mergeCombiners 逻辑是相同的,没有区别。
函数实现:
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)]
= {
combineByKey[V]((v: V) => v, func, func, partitioner)
}
图中的方框代表 RDD 分区。通过用户自定义函数 (A,B) => (A + B) 函数,将相同 key 的数据 (V1,2) 和 (V1,1) 的 value 相加运算,结果为( V1,3)。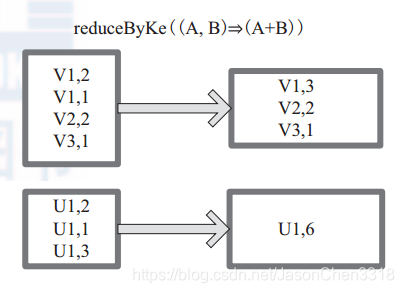
与groupByKey类似,却有不同。如(a,1), (a,2), (b,1), (b,2)。groupByKey产生中间结果为( (a,1), (a,2) ), ( (b,1), (b,2) )。而reduceByKey为(a,3), (b,3)。
reduceByKey主要作用是聚合,groupByKey主要作用是分组。(function对于key值来进行聚合)
//代码
val a = sc.parallelize(List("dog", "catt", "owl", "gnu", "ant"), 2)
println(a.collect().mkString(","))
//res:dog,catt,owl,gnu,ant
val b = a.map(x => (x.length,x))
println(b.reduceByKey(_ + _).collect.mkString(","))
//res:(4,catt),(3,dogowlgnuant)partitionBy
partitionBy函数对RDD进行分区操作。
函数定义如下。
partitionBy(partitioner:Partitioner)
如果原有RDD的分区器和现有分区器(partitioner)一致,则不重分区,如果不一致,则相当于根据分区器生成一个新的ShuffledRDD。
图18中的方框代表RDD分区。 通过新的分区策略将原来在不同分区的V1、 V2数据都合并到了一个分区。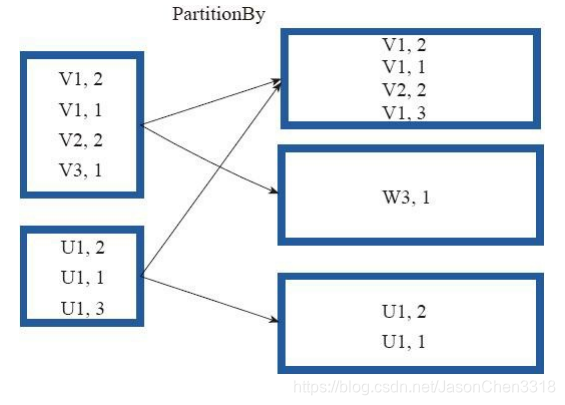
cogroup
cogroup函数将两个RDD进行协同划分,cogroup函数的定义如下。
cogroup[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (Iterable[V], Iterable[W]))]
对在两个RDD中的Key-Value类型的元素,每个RDD相同Key的元素分别聚合为一个集合,并且返回两个RDD中对应Key的元素集合的迭代器。
(K, (Iterable[V], Iterable[W]))
其中,Key和Value,Value是两个RDD下相同Key的两个数据集合的迭代器所构成的元组。
图中的大方框代表RDD,大方框内的小方框代表RDD中的分区。 将RDD1中的数据(U1,1)、 (U1,2)和RDD2中的数据(U1,2)合并为(U1,((1,2),(2)))。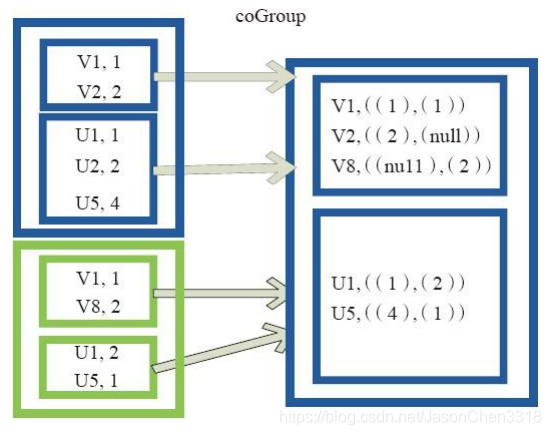
//代码
val a = sc.parallelize(List(1, 2, 1), 1)
val b = a.map((_, ("b","b")))
val c = a.map((_, "c"))
println(b.cogroup(c).collect.mkString(","))
//res:(1,(CompactBuffer((b,b), (b,b)),CompactBuffer(c, c))),(2,(CompactBuffer((b,b)),CompactBuffer(c)))join
join 对两个需要连接的 RDD 进行 cogroup函数操作,将相同 key 的数据能够放到一个分区,在 cogroup 操作之后形成的新 RDD 对每个key 下的元素进行笛卡尔积的操作,返回的结果再展平,对应 key 下的所有元组形成一个集合。最后返回 RDD[(K, (V, W))]。
下 面 代 码 为 join 的 函 数 实 现, 本 质 是通 过 cogroup 算 子 先 进 行 协 同 划 分, 再 通 过flatMapValues 将合并的数据打散。
this.cogroup(other,partitioner).f latMapValues{case(vs,ws) => for(v<-vs;w<-ws)yield(v,w) }
图 20是对两个 RDD 的 join 操作示意图。大方框代表 RDD,小方框代表 RDD 中的分区。函数对相同 key 的元素,如 V1 为 key 做连接后结果为 (V1,(1,1)) 和 (V1,(1,2))。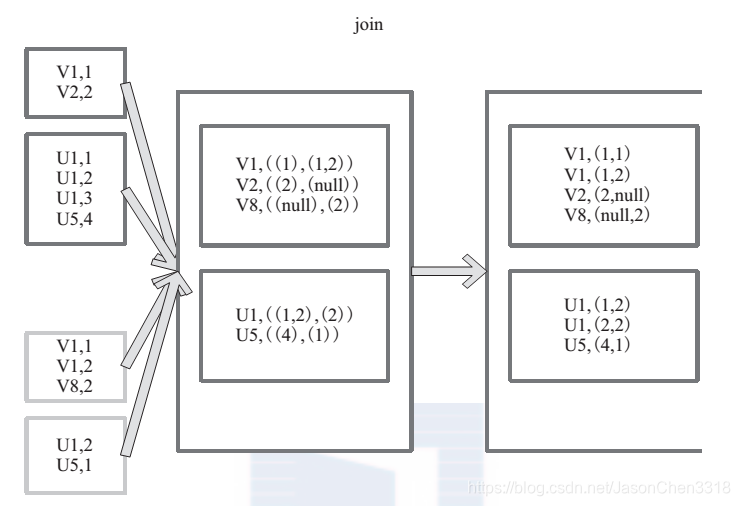
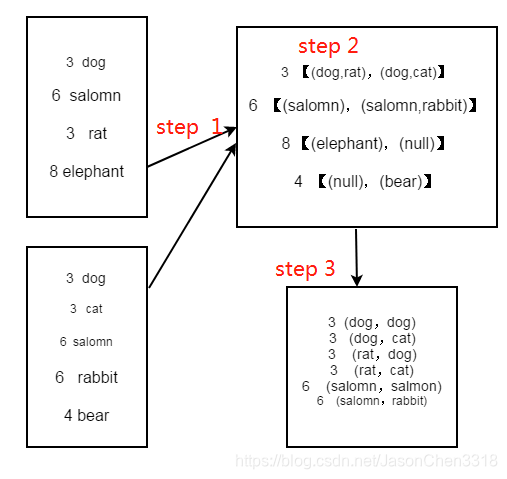
//代码
val a = sc.parallelize(List("dog", "salmon", "rat", "elephant"), 3)
val b = a.keyBy(_.length)
println(b.collect().mkString(","))
val c = sc.parallelize(List("dog","cat","salmon","rabbit","bear"), 3)
val d = c.keyBy(_.length)
println(b.join(d).collect.mkString(","))
//res:(6,(salmon,salmon)),(6,(salmon,rabbit)),(3,(dog,dog)),(3,(dog,cat)),(3,(rat,dog)),(3,(rat,cat))
leftOuterJoin
LeftOutJoin(左外连接)和RightOutJoin(右外连接)相当于在join的基础上先判断一侧的RDD元素是否为空,如果为空,则填充为空。 如果不为空,则将数据进行连接运算,并
返回结果。
下面代码是leftOutJoin的实现。
if (ws.isEmpty) {
vs.map(v => (v, None))
} else {
for (v <- vs; w <- ws) yield (v, Some(w))
}
//代码
val a = sc.parallelize(List("dog", "salmon", "rat", "elephant"), 3)
val b = a.keyBy(_.length)
val c = sc.parallelize(List("dog","salmon","rabbit","bear"), 3)
val d = c.keyBy(_.length)
//左外连接
println(b.leftOuterJoin(d).collect.mkString(","))
//res:(6,(salmon,Some(salmon))),(6,(salmon,Some(rabbit))),(3,(dog,Some(dog))),(3,(rat,Some(dog))),(8,(elephant,None))
//右外连接
println(b.rightOuterJoin(d).collect.mkString(","))
//(6,(Some(salmon),salmon)),(6,(Some(salmon),rabbit)),(3,(Some(dog),dog)),(3,(Some(rat),dog)),(4,(None,bear))
Action算子
本质上在 Action 算子中通过 SparkContext 进行了提交作业的 runJob 操作,触发了RDD DAG 的执行。
例如, Action 算子 collect 函数的代码如下,感兴趣的读者可以顺着这个入口进行源码剖析:
/**
* Return an array that contains all of the elements in this RDD.
*/
def collect(): Array[T] = {
/* 提交 Job*/
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
Foreach
foreach 对 RDD 中的每个元素都应用 f 函数操作,不返回 RDD 和 Array, 而是返回Uint。图表示 foreach 算子通过用户自定义函数对每个数据项进行操作。本例中自定义函数为 println(),控制台打印所有数据项。
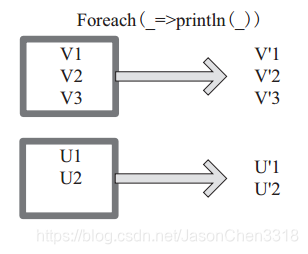
//代码
val c = sc.parallelize(List("cat", "dog", "tiger", "lion", "ant", "dolphin"), 3)
c.foreach(x => println(x + "s are yummy"))
/*res:
cats are yummy
dogs are yummy
tigers are yummy
lions are yummy
ants are yummy
dolphins are yummy
*/saveAsTextFile
函数将数据输出,存储到 HDFS 的指定目录。
下面为 saveAsTextFile 函数的内部实现,其内部
通过调用 saveAsHadoopFile 进行实现:
this.map(x => (NullWritable.get(), new Text(x.toString))).saveAsHadoopFile[TextOutputFormat[NullWritable, Text]](path)
将 RDD 中的每个元素映射转变为 (null, x.toString),然后再将其写入 HDFS。
图 中左侧方框代表 RDD 分区,右侧方框代表 HDFS 的 Block。通过函数将RDD 的每个分区存储为 HDFS 中的一个 Block。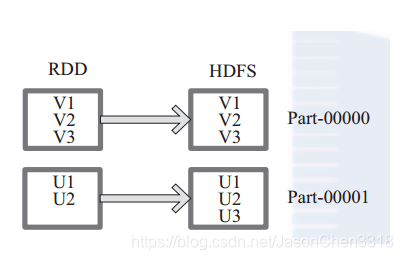
//代码
val a = sc.parallelize(1 to 10000, 3)
a.saveAsTextFile("mydata_a")
//res:19/05/07 18:15:38 INFO FileOutputCommitter: Saved output of task 'attempt_201905071815_0000_m_000002_2' to file:/F:/Test/Test/mydata_a/_temporary/0/task_201905071815_0000_m_000002saveAsObjectFile
saveAsObjectFile将分区中的每10个元素组成一个Array,然后将这个Array序列化,映射为(Null,BytesWritable(Y))的元素,写入HDFS为SequenceFile的格式。
下面代码为函数内部实现。
map(x=>(NullWritable.get(),new BytesWritable(Utils.serialize(x))))
图24中的左侧方框代表RDD分区,右侧方框代表HDFS的Block。 通过函数将RDD的每个分区存储为HDFS上的一个Block。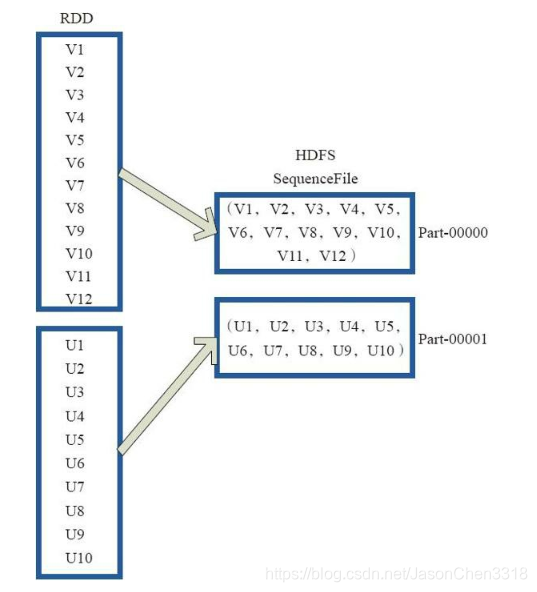
//代码
val x = sc.parallelize(1 to 100, 3)
x.saveAsObjectFile("objFile")
val y = sc.objectFile[Int]("objFile")
println(y.collect.mkString(","))
//res:打印出1-100collect
collect 相当于 toArray, toArray 已经过时不推荐使用, collect 将分布式的 RDD 返回为一个单机的 scala Array 数组。在这个数组上运用 scala 的函数式操作。
图 中左侧方框代表 RDD 分区,右侧方框代表单机内存中的数组。通过函数操作,将结果返回到 Driver 程序所在的节点,以数组形式存储。
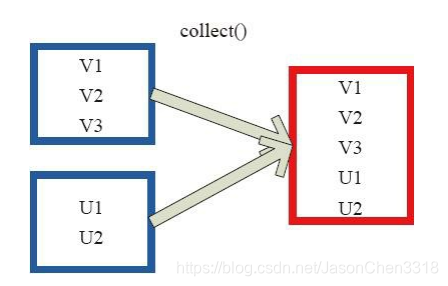
//代码
val c = sc.parallelize(List("Gnu", "Cat", "Rat"), 2)
println(c.collect.mkString(","))
//res:Gnu,Cat,Rat,Dog,Gnu,RatcollectAsMap
collectAsMap对(K,V)型的RDD数据返回一个单机HashMap。 对于重复K的RDD元素,后面的元素覆盖前面的元素。
图中的左侧方框代表RDD分区,右侧方框代表单机数组。 数据通过collectAsMap函数返回给Driver程序计算结果,结果以HashMap形式存储。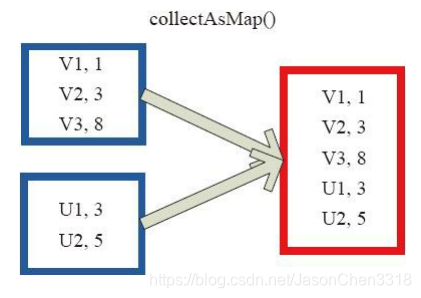
//代码
val a = sc.parallelize(List(1, 2, 1, 3), 1)
val b = a.zip(a)
println(b.collect().mkString(","))
println(b.collectAsMap)
/*
res:(1,1),(2,2),(1,1),(3,3)
res:Map(2 -> 2, 1 -> 1, 3 -> 3)
*/reduceByKeyLocally
实现的是先reduce再collectAsMap的功能,先对RDD的整体进行reduce操作,然后再收集所有结果返回为一个HashMap。
//代码
val a = sc.parallelize(List("dg", "catt", "owl", "gnu", "ant"), 2)
val b = a.map(x => (x.length, x))
println(b.collect().mkString(","))
println(b.reduceByKey(_ + _).collect.mkString(","))
/*res:
(4,catt),(2,dg),(3,owlgnuant)
(2,dg),(4,catt),(3,owl),(3,gnu),(3,ant)
*/lookup
下面代码为lookup的声明。
lookup(key:K):Seq[V]
Lookup函数对(Key,Value)型的RDD操作,返回指定Key对应的元素形成的Seq。 这个函数处理优化的部分在于,如果这个RDD包含分区器,则只会对应处理K所在的分区,然后返回由(K,V)形成的Seq。 如果RDD不包含分区器,则需要对全RDD元素进行暴力扫描处理,搜索指定K对应的元素。
图28中的左侧方框代表RDD分区,右侧方框代表Seq,最后结果返回到Driver所在节点的应用中。
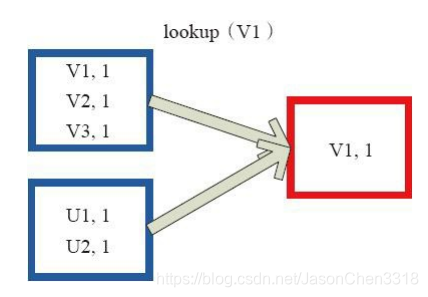
//代码
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
val b = a.map(x => (x.length, x))
println(b.lookup(5))
//res:WrappedArray(tiger, eagle)count
count 返回整个 RDD 的元素个数。
内部函数实现为:
defcount():Long=sc.runJob(this,Utils.getIteratorSize_).sum
图 29中,返回数据的个数为 5。一个方块代表一个 RDD 分区。
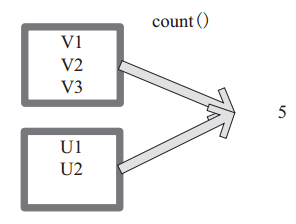
//代码
val c = sc.parallelize(List("Gnu", "Cat", "Rat", "Dog"), 2)
println(c.count)
//res:4top、take、takeOrdered、first
top可返回最大的k个元素。 函数定义如下。
top(num:Int)(implicit ord:Ordering[T]):Array[T]
相近函数说明如下。
·top返回最大的k个元素。
·take返回一个包含数据集前n个元素的数组(从0下标到n-1下标的元素),不排序。。
·takeOrdered:RDD数组先按升序排序,然后返回RDD中前n个元素,(按默认顺序排序(升序)或者按自定义比较器顺序排序。)
·first相当于top(1)返回整个RDD中的前k个元素,可以定义排序的方式Ordering[T]。
返回的是一个含前k个元素的数组。
//代码
val c = sc.parallelize(Array(6, 9, 4, 7, 5, 8), 2)
println(c.top(2).mkString(","))
println(c.take(4).mkString(","))
println(c.takeOrdered(4).mkString(","))
println(c.first)
//res:
9,8
6,9,4,7
4,5,6,7
6reduce
reduce函数相当于对RDD中的元素进行reduceLeft函数的操作。 函数实现如下。
Some(iter.reduceLeft(cleanF))
reduceLeft先对两个元素<K,V>进行reduce函数操作,然后将结果和迭代器取出的下一个元素<k,V>进行reduce函数操作,直到迭代器遍历完所有元素,得到最后结果。在RDD中,先对每个分区中的所有元素<K,V>的集合分别进行reduceLeft。 每个分区形成的结果相当于一个元素<K,V>,再对这个结果集合进行reduceleft操作。
例如:用户自定义函数如下。
f:(A,B)=>(A._1+”@”+B._1,A._2+B._2)
图31中的方框代表一个RDD分区,通过用户自定函数f将数据进行reduce运算。 示例
最后的返回结果为V1@[1]V2U!@U2@U3@U4,12。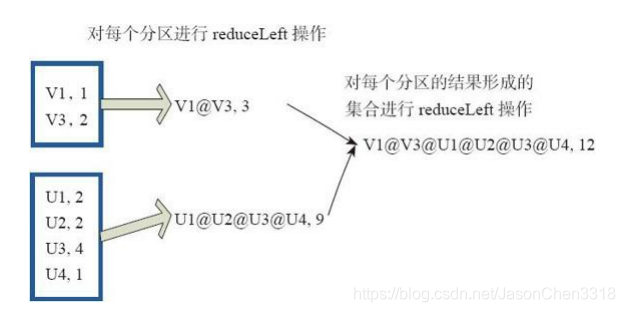
//代码
val a = sc.parallelize(1 to 100, 3)
println(a.reduce(_ + _))
//res:5050fold
fold和reduce的原理相同,但是与reduce不同,相当于每个reduce时,迭代器取的第一个元素是zeroValue。
图32中通过下面的用户自定义函数进行fold运算,图中的一个方框代表一个RDD分区。 读者可以参照reduce函数理解。
fold((”V0@”,2))( (A,B)=>(A._1+”@”+B._1,A._2+B._2))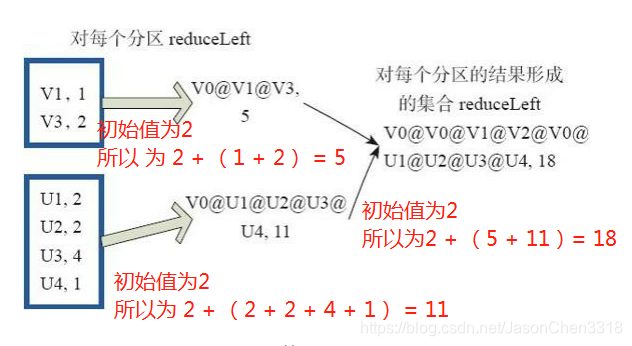
//代码
val a = sc.parallelize(List(1,2,3), 3)
println(a.fold(2)(_ + _))
//res:14
计算步骤:
1) 2 + 1 = 3
2) 2 + 2 = 4
3) 2 + 3 = 5
4) 2 + (3 + 4 + 5) = 14aggregate
aggragete算子作为spark的算子之一,虽然没有map,reduce算子使用的多但是也是一个不容忽略的算子,但是关于这个算子的用法很多解释都含糊不清 ,下面就记载下来以备以后观看。
aggregate在scala语言中本来就存在,它的输入值和返回值的类型可以不一致,而reduce函数输入和输出数据类型 必须一致。首先他需要接受一个输入的初始值,然后再接受一个函数f1,把数据进行分块,按照分块计算各个分块之间的数据得到一个结果,它还有一个函数f2参数,使用这个参数对分块求得的结果再次进行计算。
在spark中aggregate也是接受一个初始值,在各个分区之间应用f1函数,然后分区之间应用f2函数最后得到一个结果进行返回。
eg:”a1”,(“A”,”1,2,3”) 这种字符串的 “1,2,3”为某种聚合值,对所有的这种类型的值按照列进行累加求和,下面就可以使用这种函数进行操作。以下为原生scala中的操作,在spark中该函数(算子)的使用方法也是相同的。
object Fun{
def main(args: Array[String]): Unit = {
val seq = Seq(("a1",("A","1,2,3")),("a2",("A","1,2,3")),("a3",("A","1,2,3")),("a4",("A","1,2,3")))
val res = seq.aggregate("0,0,0")( (x,y) => getAddition(x, y._2._2), (x,y) => getAddition(x,y))
println(res)
}
def getAddition(fist:String,second:String):String ={
val s1 = fist.split("\\,")
val s2 = second.split("\\,")
val resSeq = for (i <- 0 until s1.length) yield (s1(i).toInt + s2(i).toInt).toString
resSeq.mkString(",")
}
}
运行结果:
4,8,12//代码
val z = sc.parallelize(List(1,2,3,4), 3)
// lets first print out the contents of the RDD with partition labels
def myfunc(index: Int, iter: Iterator[(Int)]) : Iterator[String] = {
iter.toList.map(x => "[partID:" + index + ", val: " + x + "]").iterator
}
println(z.mapPartitionsWithIndex(myfunc).collect.mkString(","))
println(math.max(1, 2), 1 + 2)
println(z.aggregate(0)(math.max(_, _), _ + _))
//res:
[partID:0, val: 1],[partID:1, val: 2],[partID:2, val: 3],[partID:2, val: 4]
(2,3)
7
















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









