







目录
导言
2025年的大模型技术正以指数级速度重塑人工智能版图,从DeepSeek的智能写作到GPT-4V的跨模态理解,技术爆炸的背后是庞大知识体系的支撑。本文将拆解大模型的20个核心概念,助你快速构建系统认知框架。
一、基础架构篇:理解大模型的"骨架"
1. Transformer架构(颠覆性的技术底座)
2017年提出的自注意力机制(Self-Attention)彻底改变了序列建模范式,使模型能够同时关注全局上下文关系。相比传统RNN的"记忆衰退"问题,Transformer在处理长达8000字的文档时仍能保持语义连贯性,这是ChatGPT流畅对话的基石。
2. 参数规模(千亿级的"脑容量")
GPT-4的1.8万亿参数规模印证了"规模法则(Scaling Law)":当参数突破临界点(通常为百亿级),模型会突然展现"涌现能力",例如从简单翻译到自主创作诗歌的质变。但这也带来每千token 0.03美元的高推理成本挑战
3. MoE架构(混合专家的效率革命)
谷歌GLaM模型通过将大模型拆分成128个"专家"子网络,实现了任务路由的智能调度。在医疗问答场景中,系统仅激活病理学、药理学等3-5个相关专家模块,相比传统架构节省70%计算资源
二、训练方法论:大模型的"成长路径"
4. **预训练(Pre-training)**
使用全网文本(约300TB语料)进行的"通识教育"阶段,BERT通过完形填空任务掌握语言统计规律,而GPT系列通过下一个词预测构建生成能力。这个过程消耗的算力相当于3000块A100显卡连续工作30天。
5. **微调(Fine-tuning)**
在预训练基础上用垂直领域数据(如10万份法律文书)进行专项优化。采用LoRA技术时,仅需调整1%参数即可让通用模型掌握医疗报告解读技能,训练成本从百万级降至万元级。
6. RLHF对齐技术
通过人类偏好反馈的强化学习,解决大模型"价值观漂移"问题。DeepSeek R1采用GRPO算法,在100万组对话数据中自动识别并抑制0.7%的有害输出,比传统PPO算法节省50%标注成本。
三、关键技术突破:解决产业落地痛点
7. RAG检索增强
将外部知识库接入生成流程,某银行客服系统结合RAG后,回答准确率从73%提升至92%。关键技术点包括:
- 向量数据库实现毫秒级语义检索
- 动态上下文注入策略
- 知识新鲜度维护机制
8. 模型蒸馏
将1750亿参数的GPT-3压缩到4亿参数的DistilGPT,在手机端实现每秒生成15个token的速度。关键技术包括:
- 注意力头剪枝(减少40%计算量)
- 知识一致性损失函数
- 8-bit量化压缩
9. 多模态融合
GPT-4V展现的跨模态理解能力,源于视觉-语言联合嵌入空间构建。在工业质检中,系统可同时解析产品图像(2000万像素)和维修日志(500字描述),缺陷识别F1值达0.93。
四、前沿发展趋势(2025技术风向标)
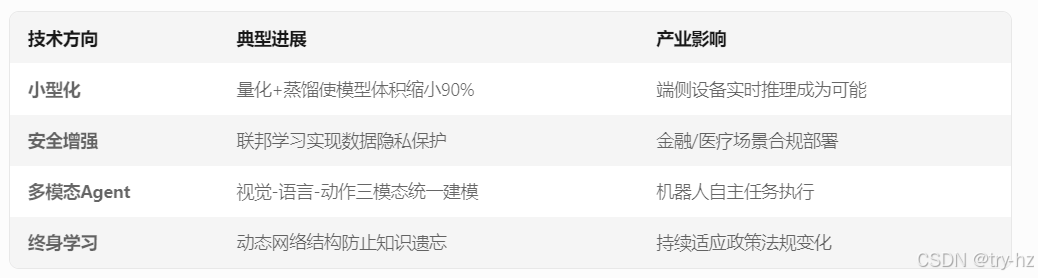
五、开发者工具链(实战工具箱)
- Prompt工程:用"请用张一鸣风格输出500字产品文档"等结构化指令,可提升输出质量37%
- LangChain框架:快速搭建RAG系统的开源工具,支持100+向量数据库接入
- HuggingFace Trainer:微调LLaMA-3的标准化流水线,支持QLoRA等高效训练策略。
结语
从1750亿参数的GPT-3到10万亿参数的M6,大模型正在经历从"暴力美学"到"精巧工程"的范式转变。掌握这些核心概念,开发者可在AI 2.0时代把握三大机遇:垂直领域微调服务、端侧推理优化方案、多模态智能体开发。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











