




Attention机制讲解
attention是一种能让模型对重要信息重点关注并充分学习吸收的技术,它不算是一个完整的模型,应当是一种技术,能够作用于任何序列模型中。
Seq2Seq
在开始讲解Attention之前,我们先简单回顾一下Seq2Seq模型,传统的机器翻译基本都是基于Seq2Seq模型来做的,该模型分为encoder层与decoder层,并均为RNN或RNN的变体构成,如下图所示:
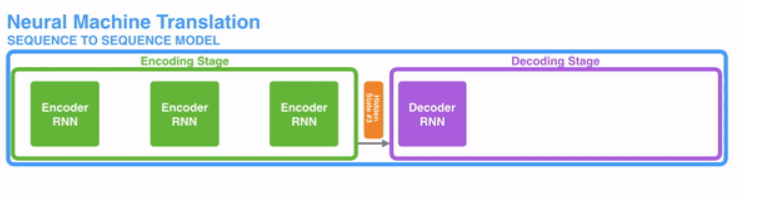
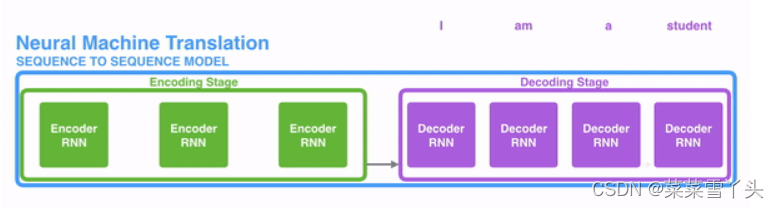
该模型对于短文本的翻译来说效果很好,但是其也存在一定的缺点,如果文本稍长一些,就很容易丢失文本的一些信息,为了解决这个问题,Attention应运而生。
Attention
Attention,正如其名,注意力,该模型在decode阶段,会选择最适合当前节点的context作为输入。
Attention与传统的Seq2Seq模型的不同
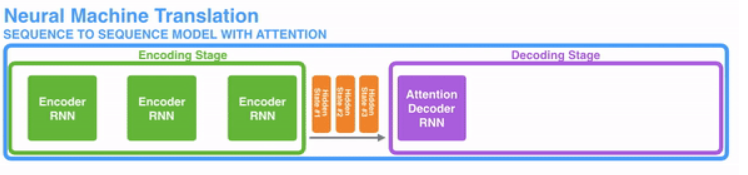
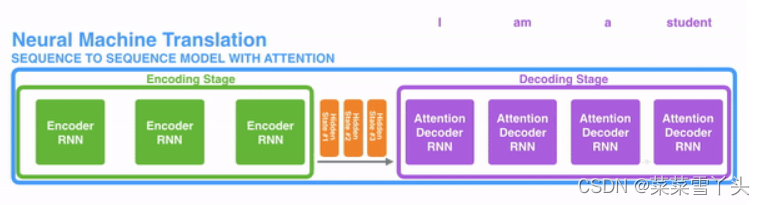
- encoder提供了更多的数据给到decoder,encoder会把所有的节点的hidden state提供给decoder,而不仅仅只是encoder最后一个节点的hidden state。
- decoder并不是直接把所有encoder提供的hidden state作为输入,而是采取一种选择机制,把最符合当前位置的hidden state选出来,具体的步骤如下:
- 计算每一个hidden state的分数值(具体怎么计算我们下文讲解);
- 对每个分数值做一个softmax的计算,这能让相关性高的hidden state的分数值更大,相关性低的hidden state的分数值更低;
- 加权求和。
Attention公式
An attention function ca be described as mapping a query and a set of key-value pairs to an output.
Attention函数的本质可以被描述为一个查询(query)到一系列键key-值value对的映射。
A t t e n t i o n ( Q u e r y , S o u r c e ) = ∑ S i m i l a r i t y ( Q u e r y , K e y i ) ∗ V a l u e i Attention(Query, Source) = \sum Similarity(Query, Key_i)*Value_i Attention(Query,Source)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









